Kubernetes简介
kubernetes是可移植、可扩展、开源的容器管理平台,是谷歌Borg的开源版本,简称k8s,它可以创建应用、更新应用、回滚应用,也可实现应用的扩容缩容,做到故障自恢复。
可移植:基于镜像可从一个环境迁移到另一个环境
可扩展:k8s集群可以横向扩展、根据流量实现自动扩缩容
开源的:源代码已经公开了,可以被用户免费使用,可以二次开发
可以对容器自动化部署、自动化扩缩容、跨主机管理等;
可以对代码进行灰度发布、金丝雀发布、蓝绿发布、滚动更新等;
具有完整的监控系统和日志收集平台,具有故障自恢复的能力。
kubernetes起源
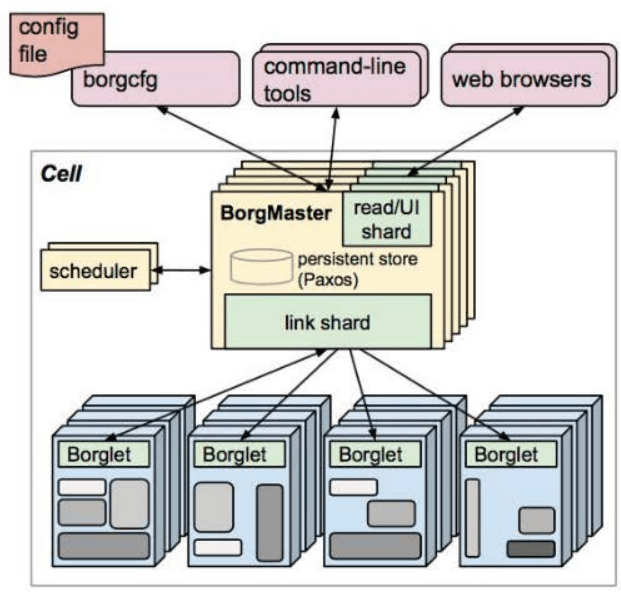
Borg是谷歌内部的一个容器编排工具,谷歌业务90%以上都在Borg上运行,Borg在谷歌内部已经使用了大概15年。 K8S是在Borg的基础上开发出来的轻量级容器编排工具。K8S的根基非常牢固,得益于Borg过去十数年间积累的经验和教训,是站在巨人的肩膀上发展起来的项目。开源之后,迅速称霸容器编排技术领域。
Google Borg架构
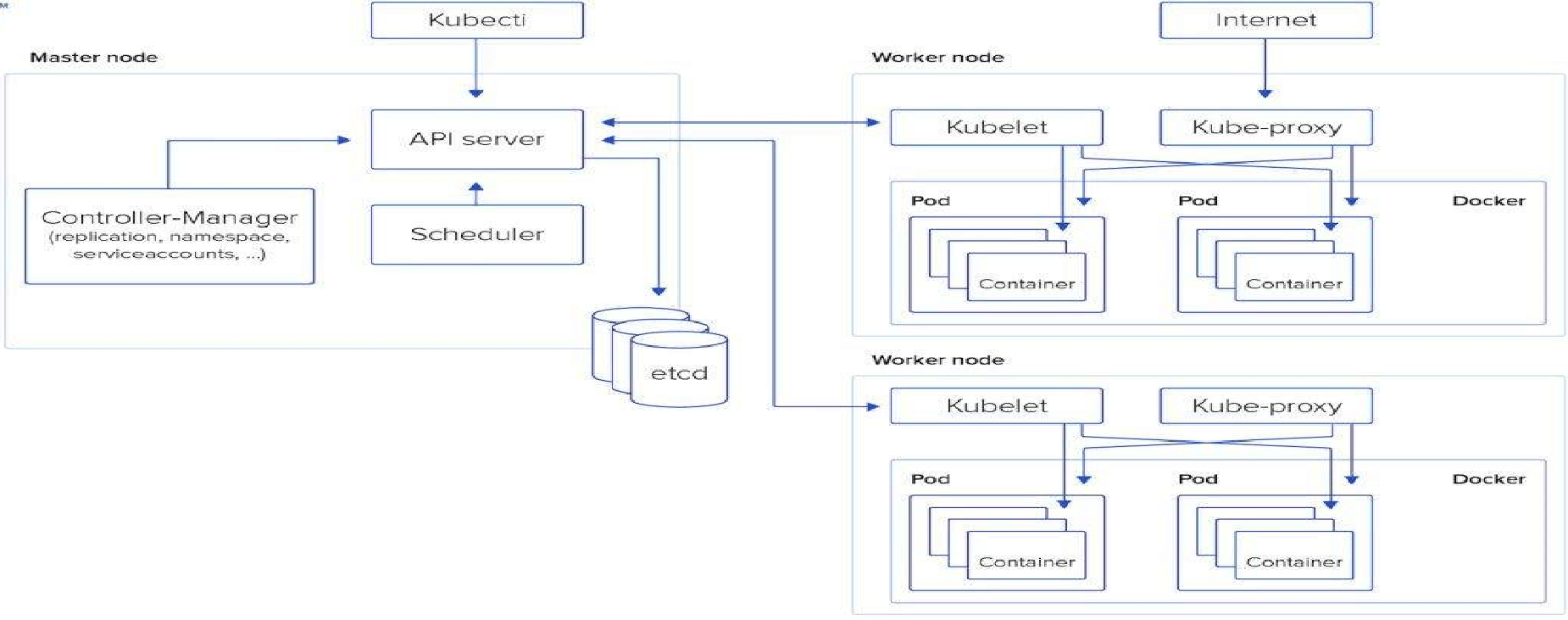
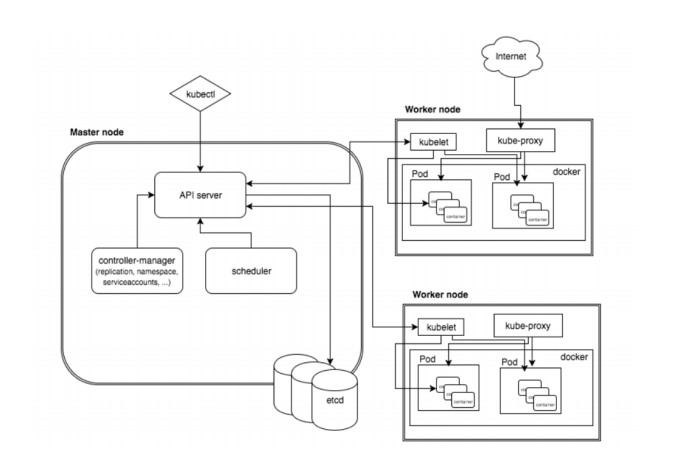
Kubernetes架构
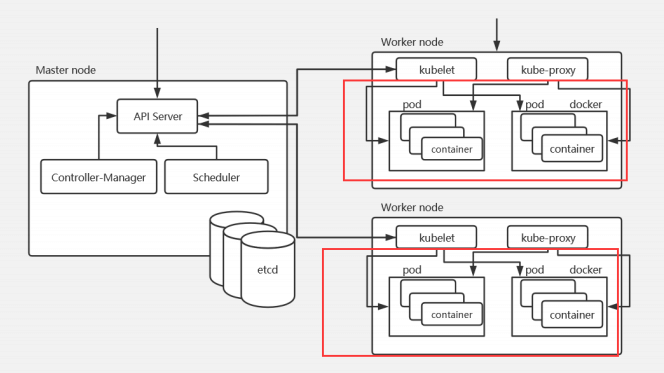
k8s的物理架构是master/node模式:
K8S集群至少需要一个主节点(Master)和多个工作节点(Worker),Master节点是集群的控制节点,负责整个集群的管理和控制,主要用于暴露API、调度部署和对节点进行管理。工作节点主要是运行容器的。
单master节点架构图
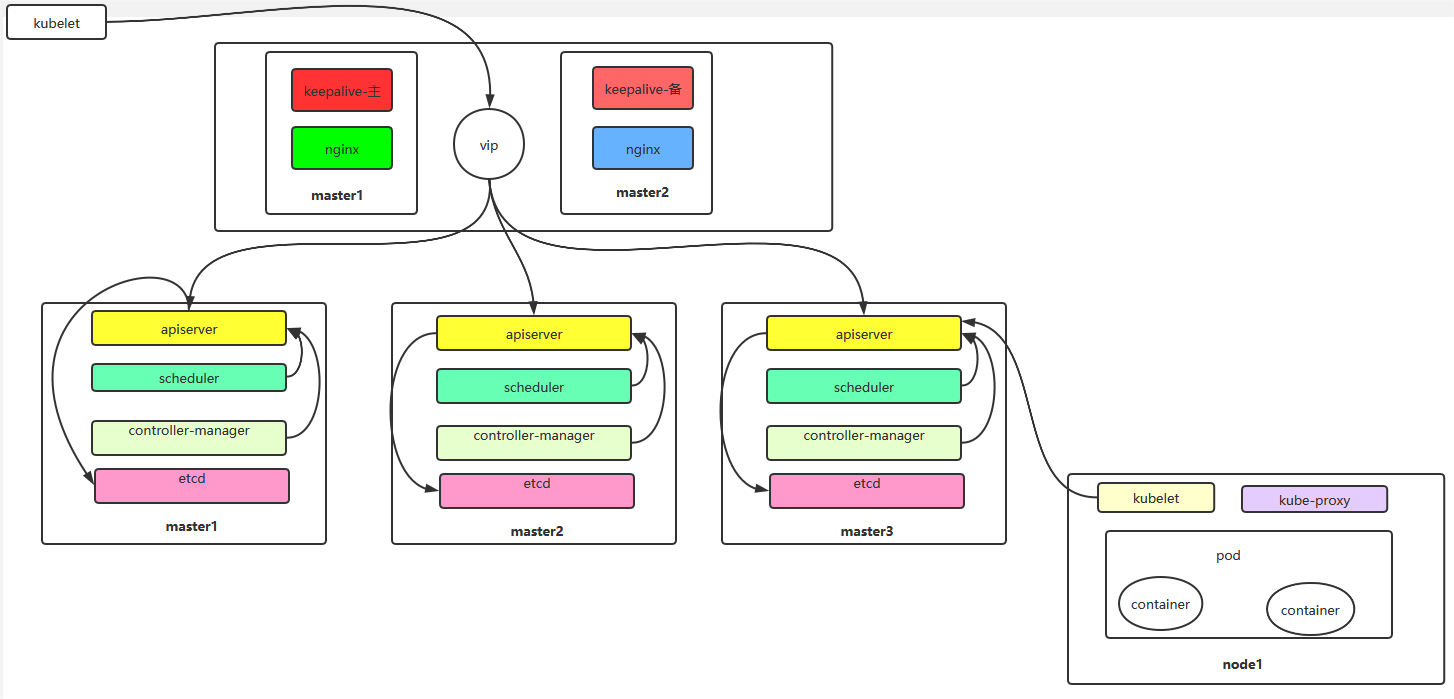
多master节点架构图
Kubernetes组件 Master node
apiserver
scheduler
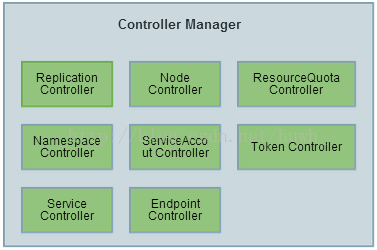
controller-manager
Etcd
calico
docker
Work node
kubelet
kube-proxy
Calico
Coredns
docker
各组件解析
kubectl
管理k8s的命令行工具,可以操作k8s中的资源对象,如增删改查等。
etcd
是一个高可用的键值数据库,存储k8s的资源状态信息和网络信息的,etcd中的数据变更是通过api server进行的。
apiserver
提供k8s api,是整个系统的对外接口,提供资源操作的唯一入口,供客户端和其它组件调用,提供了k8s各类资源对象(pod,deployment,Service等)的增删改查,是整个系统的数据总线和数据中心,并提供认证、授权、访问控制、API注册和发现等机制,并将操作对象持久化到etcd中。
scheduler
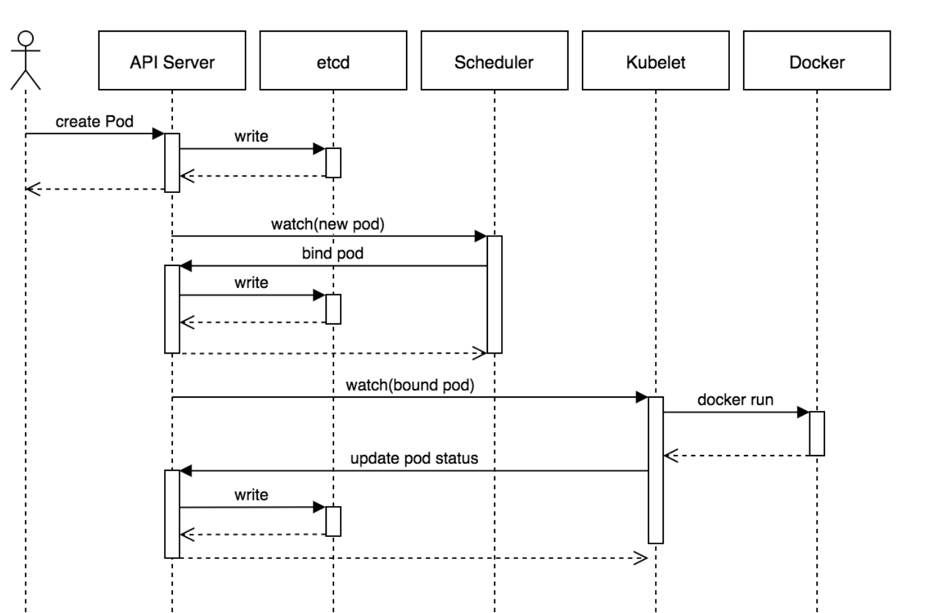
负责k8s集群中pod的调度的 , scheduler通过与apiserver交互监听到创建Pod副本的信息后,它会检索所有符合该Pod要求的工作节点列表,开始执行Pod调度逻辑。调度成功后将Pod绑定到目标节点上,相当于“调度室”。
Controller-Manager
作为集群内部的管理控制中心,负责集群内的Node、Pod副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的管理,当某个Node意外宕机时,Controller Manager会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。
每个Controller通过API Server提供的接口实时监控整个集群的每个资源对象的当前状态,当发生各种故障导致系统状态发生变化时,会尝试将系统状态修复到“期望状态”。
kubelet
每个Node节点上的kubelet定期就会调用API Server的REST接口报告自身状态,API Server接收这些信息后,将节点状态信息更新到etcd中。kubelet也通过API Server监听Pod信息,从而对Node机器上的POD进行管理,如创建、删除、更新Pod
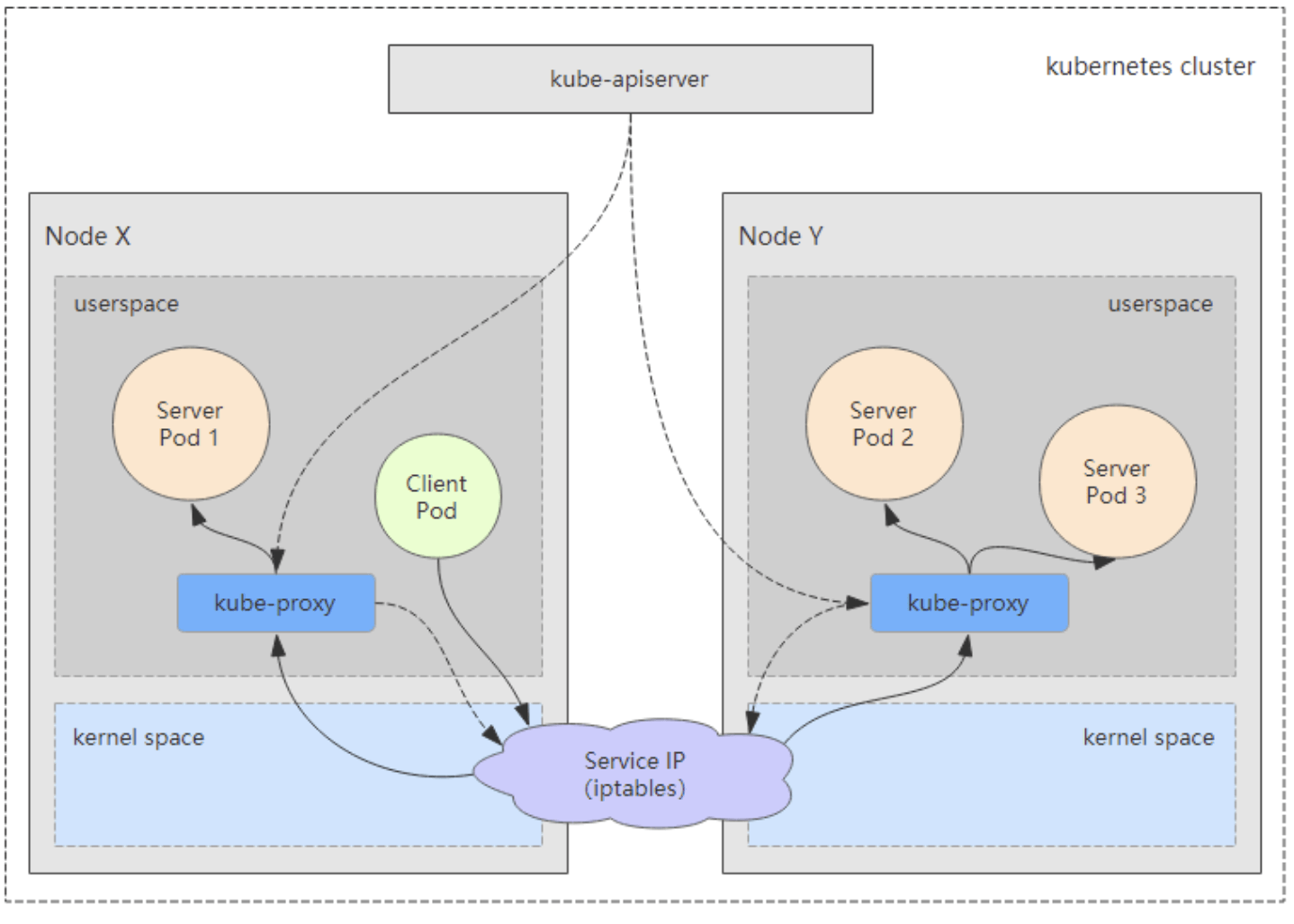
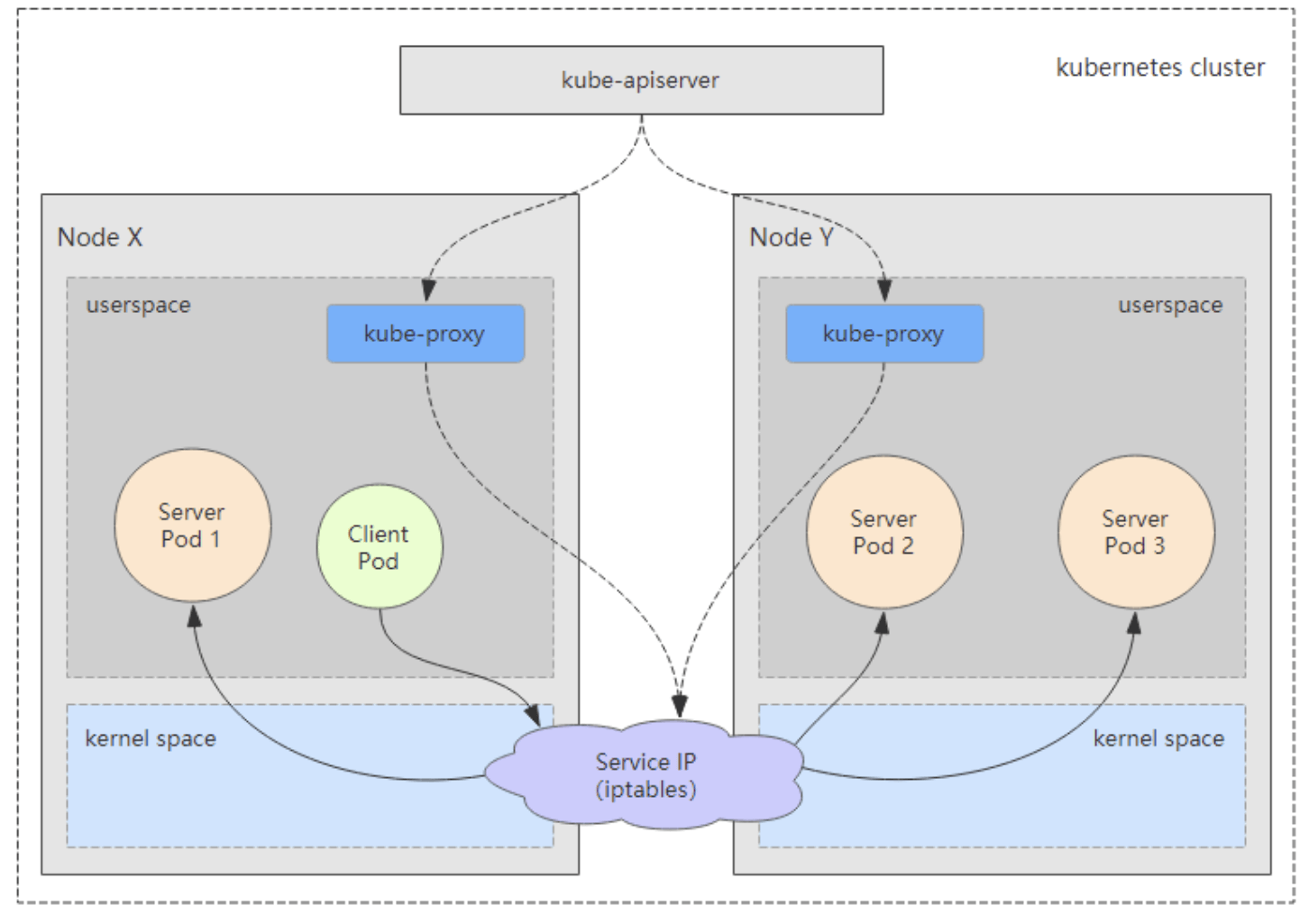
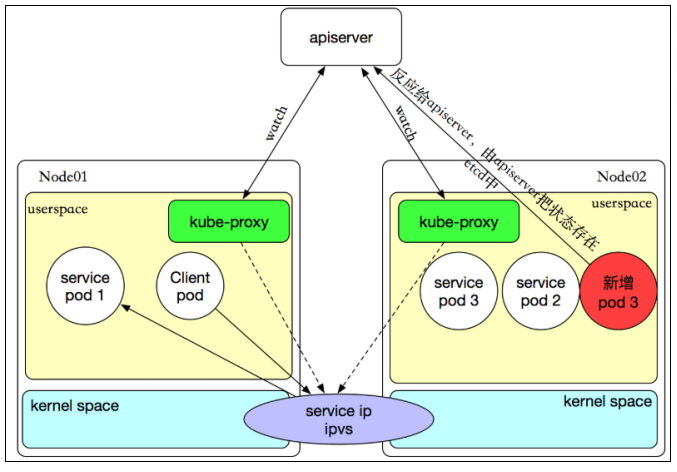
kube-proxy
提供网络代理和负载均衡,是实现service的通信与负载均衡机制的重要组件,kube-proxy负责为Pod创建代理服务,从apiserver获取所有service信息,并根据service信息创建代理服务,实现service到Pod的请求路由和转发,从而实现K8s层级的虚拟转发网络,将到service的请求转发到后端的pod上。
Cordns
CoreDNS 其实就是一个 DNS 服务,而 DNS 作为一种常见的服务发现手段,很多开源项目以及工程师都会使用 CoreDNS 为集群提供服务发现的功能,Kubernetes 就在集群中使用 CoreDNS 解决服务发现的问题。
Calico
是一套开源的网络和网络安全方案,用于容器、虚拟机、宿主机之前的网络连接,可以用在kubernetes、OpenShift、DockerEE、OpenStrack等PaaS或IaaS平台上。
Docker
容器运行时,负责启动容器的,在k8s1.20版本之后建议废弃docker,使用container作为容器运行时
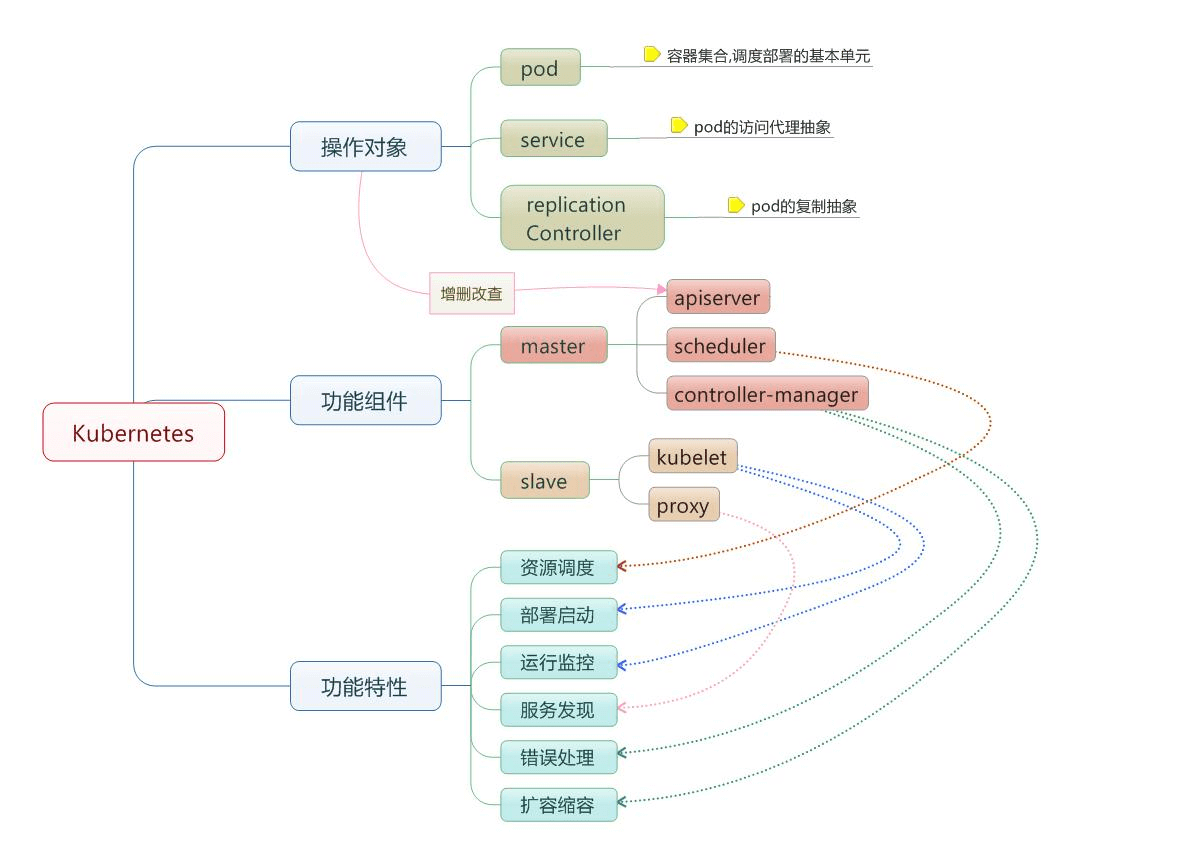
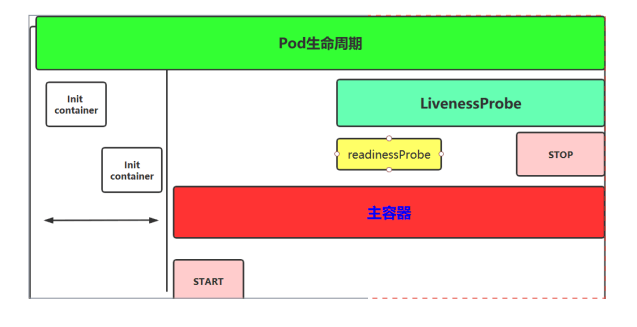
Kubernetes核心资源解读 Pod
Pod是Kubernetes中的最小调度单元,k8s是通过定义一个Pod的资源,然后在Pod里面运行容器,容器需要指定镜像,用来运行具体的服务。
Pod代表集群上正在运行的一个进程,一个Pod封装一个容器(也可以封装多个容器),Pod里的容器共享存储、网络等。
也就是说,应该把整个pod看作虚拟机,然后每个容器相当于运行在虚拟机的进程。
可以把pod看成是一个“豌豆荚”,里面有很多“豆子”(容器)。一个豌豆荚里的豆子,它们吸收着共同的营养成分、肥料、水分等,Pod和容器的关系也是一样,Pod里面的容器共享pod的网络、存储等。
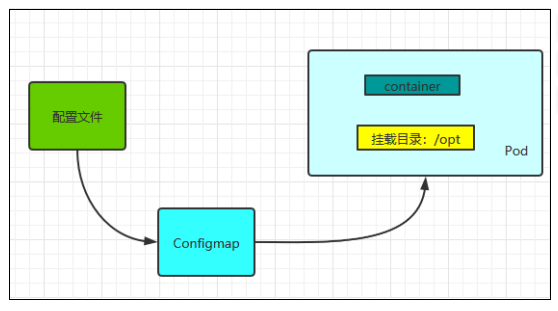
在K8s中,所有的资源都可以使用一个yaml配置文件来创建,创建Pod也可以使用yaml配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ~]# cat pod.yaml apiVersion: v1 kind: Pod metadata: name: tomcat-pod namespace: default labels: tomcat: tomcat-pod spec: containers: - name: tomcat-pod-java ports: - containerPort: 8080 image: tomcat:8.5-jre8-alpine imagePullPolicy: IfNotPresent ~]# kubectl apply -f pod.yaml ~]# kubectl get pods -l tomcat=tomcat-pod NAME READY STATUS RESTARTS AGE tomcat-pod 1 /1 Running 0 9s
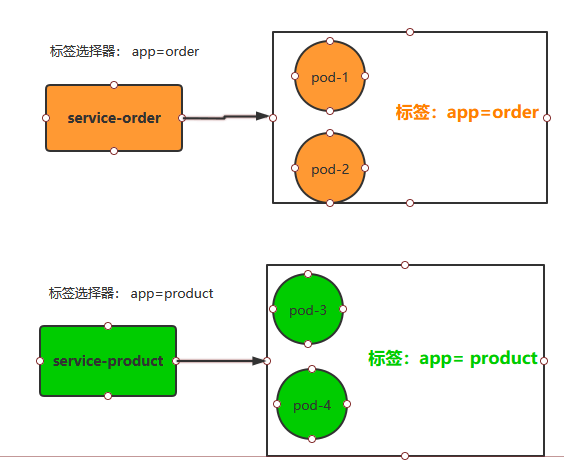
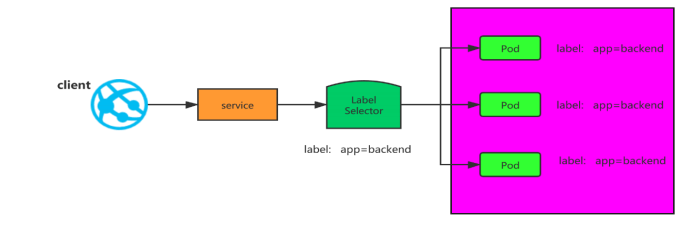
label
label是标签的意思,k8s中的资源对象大都可以打上标签,如Node、Pod、Service 等,一个资源可以绑定任意多个label,k8s 通过 Label 可实现多维度的资源分组管理,后续可通过 Label Selector 查询和筛选拥有某些 Label 的资源对象
例如创建一个 Pod,给定一个 Label是app=tomcat,那么service可以通过label selector选择拥有app=tomcat的pod,和其相关联,也可通过 app=tomcat 删除拥有该标签的 Pod 资源
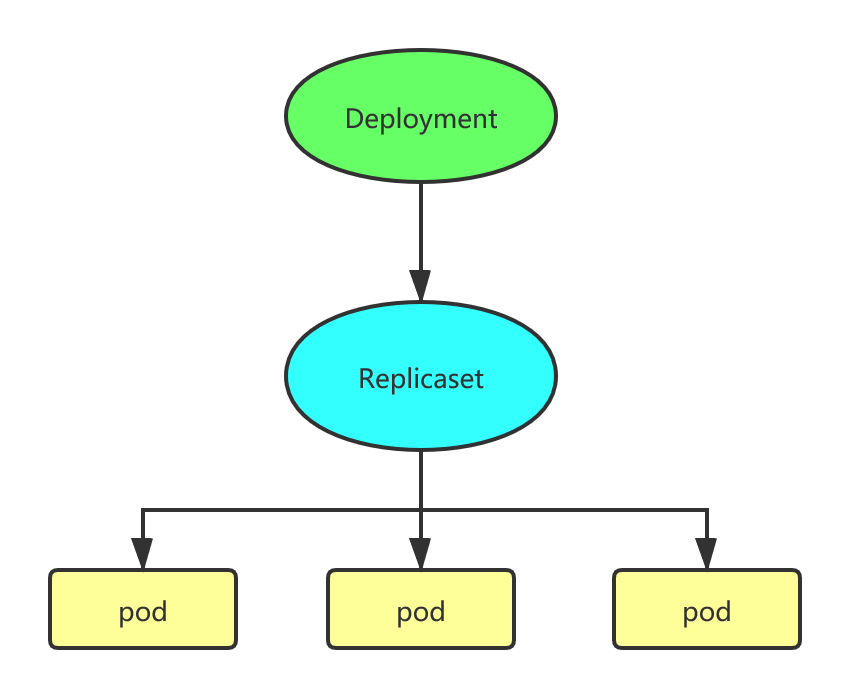
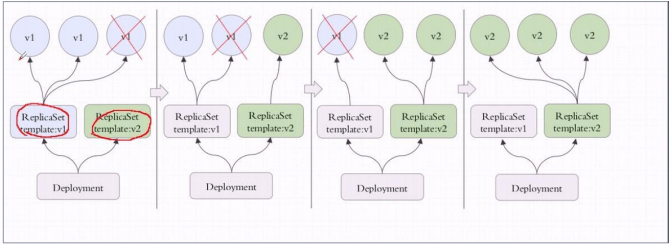
Deployment
Replicaset是Kubernetes中的副本控制器,管理Pod,使pod副本的数量始终维持在预设的个数。
Deployment是管理Replicaset和Pod的副本控制器,Deployment可以管理多个Replicaset,是比Replicaset更高级的控制器
也即是说在创建Deployment的时候,会自动创建Replicaset,由Replicaset再创建Pod,Deployment能对Pod扩容、缩容、滚动更新和回滚、维持Pod数量。
创建Deployment也可以使用yaml配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 ~]# cat deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: my-nginx spec: selector: matchLabels: run: my-nginx replicas: 2 template: metadata: labels: run: my-nginx spec: containers: - name: my-nginx image: nginx ports: - containerPort: 80 ~]# kubectl apply -f deployment.yaml ~]# kubectl get deploy | grep my-nginx my-nginx 2 /2 2 2 2m52s ~]# kubectl get rs | grep my-nginx my-nginx-5b56ccd65f 2 2 2 3m26s ~]# kubectl get pods -l run=my-nginx NAME READY STATUS RESTARTS AGE my-nginx-5b56ccd65f-29w6d 1 /1 Running 0 102s my-nginx-5b56ccd65f-8dblk 1 /1 Running 0 102s
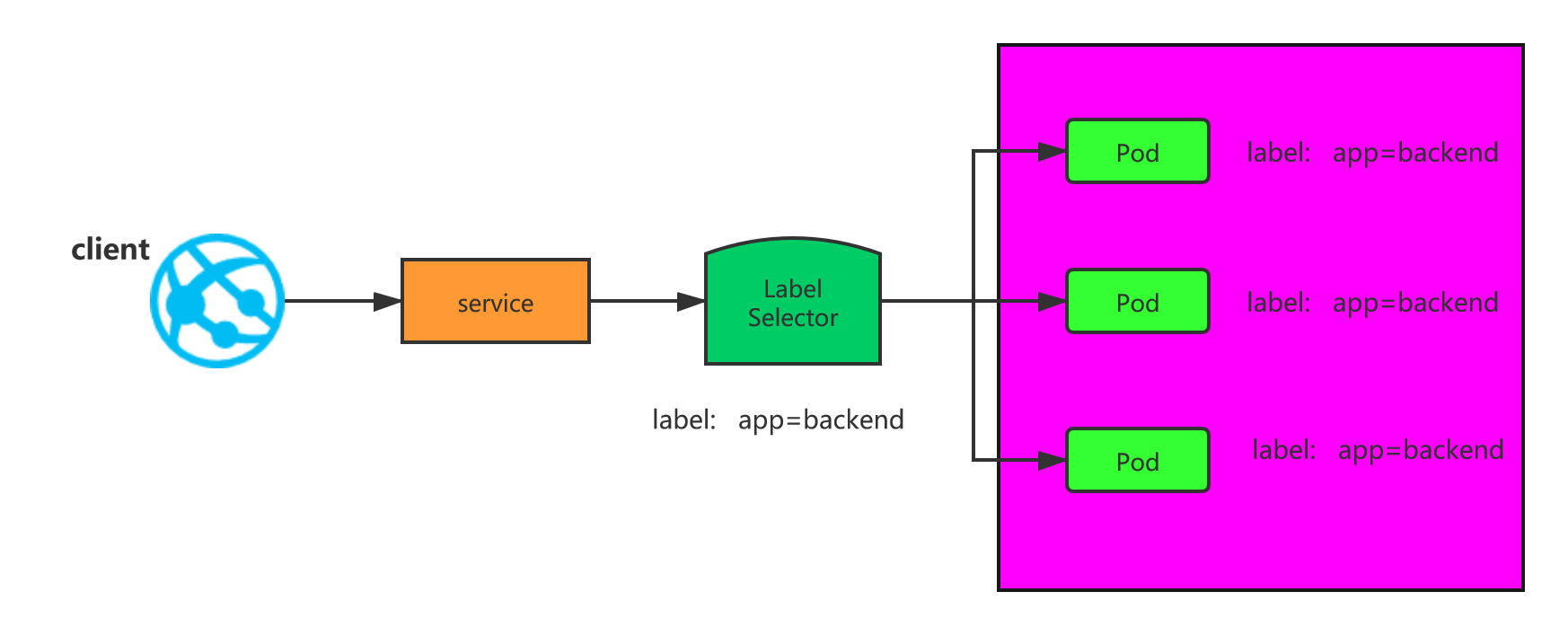
Service
在kubernetes中,Pod是有生命周期的,如果Pod重启IP很有可能会发生变化。如果我们的服务都是将Pod的IP地址写死,Pod的挂掉或者重启,和刚才重启的pod相关联的其他服务将会找不到它所关联的Pod
为了解决这个问题,在kubernetes中定义了service资源对象,Service 定义了一个服务访问的入口,客户端通过这个入口即可访问服务背后的应用集群实例,service是一组Pod的逻辑集合,这一组 Pod 能够被 Service 访问到,通常是通过 Label Selector实现的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 ~]# cat pod_test.yaml apiVersion: apps/v1 kind: Deployment metadata: name: my-nginx spec: selector: matchLabels: run: my-nginx replicas: 2 template: metadata: labels: run: my-nginx spec: containers: - name: my-nginx image: nginx ports: - containerPort: 80 ~]# cat service.yaml apiVersion: v1 kind: Service metadata: name: my-nginx labels: run: my-nginx spec: ports: - port: 80 protocol: TCP selector: run: my-nginx ~]# kubectl apply -f service.yaml ~]# kubectl get svc -l run=my-nginx NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE my-nginx ClusterIP 10.105 .104 .137 <none> 80 /TCP 12s ~]# curl 10.105 .104 .137
kubeadm安装高可用的k8s集群 k8s环境规划
centos7.6操作系统,4G/6CPU/100G,网络NAT,开启虚拟化
podSubnet(pod网段)10.244.0.0/16
k8s集群角色
ip
主机名
安装的组件
控制节点
192.168.1.180
master1
apiserver、controller-manager、scheduler、kubelet、etcd、docker、kube-proxy、keepalived、nginx、calico
控制节点
192.168.1.181
master2
apiserver、controller-manager、scheduler、kubelet、etcd、docker、kube-proxy、keepalived、nginx、calico
工作节点
192.168.1.182
node1
kubelet、kube-proxy、docker、calico、coredns
VIP
192.168.1.199
kubeadm 和二进制安装 k8s 适用场景分析
Kubeadm 和二进制都适合生产环境,在生产环境运行都很稳定,具体如何选择,可以根据实际项目进行评估。
kubeadm 是官方提供的开源工具,是一个开源项目,用于快速搭建 kubernetes 集群,目前是比较方便和推荐使用的。
kubeadm init 以及 kubeadm join 这两个命令可以快速创建 kubernetes 集群。
Kubeadm 初始化 k8s,所有的组件都是以 pod 形式运行的,具备故障自恢复能力
kubeadm 是工具,可以快速搭建集群,也就是相当于用程序脚本帮我们装好了集群,属于自动部署,简化部署操作,自动部署屏蔽了很多细节,使得对各个模块感知很少,如果对 k8s 架构组件理解不深的话,遇到问题比较难排查
kubeadm 适合需要经常部署 k8s,或者对自动化要求比较高的场景下使用。
二进制:在官网下载相关组件的二进制包,如果手动安装,对 kubernetes 理解也会更全面。
初始化实验环境
所有节点做相同操作
1 2 3 4 5 6 7 8 9 10 11 12 vim /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE=Ethernet BOOTPROTO=static # static 表示静态 ip 地址 IPADDR=192.168.1.180 # ip 地址,需要跟自己电脑所在网段一致 NETMASK=255.255.255.0 # 子网掩码,需要跟自己电脑所在网段一致 GATEWAY=192.168.1.2 # 网关,在自己电脑打开 cmd,输入 ipconfig /all 可看到 DNS1=223.5.5.5 # DNS,在自己电脑打开 cmd,输入 ipconfig /all 可看到 NAME=ens33 # 网卡名字,跟 DEVICE 名字保持一致即可 DEVICE=ens33 # 网卡设备名,ip addr 可看到自己的这个网卡设备名 ONBOOT=yes # 开机自启动网络,必须是 yes service network restart
1 2 3 4 5 6 7 8 9 10 11 12 13 # 在 192.168.1.180 上执行 hostnamectl set-hostname master1 && bash # 在 192.168.40.181 上执行 hostnamectl set-hostname master2 && bash # 在 192.168.40.182 上执行 hostnamectl set-hostname node1 && bash # 配置主机 hosts 文件 192.168.1.180 master1 192.168.1.181 master2 192.168.1.182 node1
1 2 3 4 5 6 ssh-keygen for i in master1 master2 node1 do ssh-copy-id root@$i done
为什么要关闭 swap 交换分区?
Swap 是交换分区,如果机器内存不够,会使用 swap 分区,但是 swap 分区的性能较低,k8s 设计的时候为了能提升性能,默认是不允许使用交换分区的。Kubeadm 初始化的时候会检测 swap 是否关闭,如果没关闭,那就初始化失败。如果不想要关闭交换分区,安装 k8s 的时候可以指定–ignore-preflight-errors=Swap 来解决。
1 2 3 4 5 6 7 8 # 临时关闭 swapoff -a # 永久关闭:注释 swap 挂载,给 swap 这行开头加一下注释 vim /etc/fstab # /dev/mapper/centos-swap swap swap defaults 0 0 # 如果是克隆的虚拟机,需要删除 UUID
问题 1:sysctl 是做什么的?
在运行时配置内核参数
问题 2:为什么要执行 modprobe br_netfilter?
修改/etc/sysctl.d/k8s.conf 文件,增加如下三行参数:
解决方法:
问题 3:为什么开启 net.bridge.bridge-nf-call-iptables 内核参数?
在 centos 下安装 docker,执行 docker info 出现如下警告:
解决办法:
问题 4:为什么要开启 net.ipv4.ip_forward = 1 参数?
kubeadm 初始化 k8s 如果报错:
net.ipv4.ip_forward 是数据包转发:
1 2 3 4 5 6 7 8 9 10 modprobe br_netfilter echo "modprobe br_netfilter" >> /etc/profile cat > /etc/sysctl.d/k8s.conf <<EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 EOF sysctl -p /etc/sysctl.d/k8s.conf
1 2 3 systemctl stop firewalld systemctl disable firewalld systemctl status firewalld
1 2 3 4 5 6 7 8 9 10 11 12 # 修改 selinux 配置文件之后,重启机器,selinux 配置才能永久生效 sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config # 重启 reboot # 临时关闭 setenforce 0 # 显示 Disabled 说明 selinux 已经关闭 getenforce Disabled
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 备份基础repo源 mkdir /root/repo.bak cd /etc/yum.repos.d/ mv * /root/repo.bak/ # 拉取阿里云repo源 curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo # 配置国内阿里云 docker 的 repo 源 yum install yum-utils -y yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo # 配置安装 k8s 组件需要的阿里云的 repo 源 vim /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=0
1 2 3 4 5 6 7 8 9 10 11 12 # 安装 ntpdate 命令 yum install ntpdate -y # 跟网络时间做同步 ntpdate cn.pool.ntp.org # 把时间同步做成计划任务 crontab -e * */1 * * * /usr/sbin/ntpdate cn.pool.ntp.org # 重启 crond 服务 service crond restart
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 # 编写脚本开启模块 vim /etc/sysconfig/modules/ipvs.modules # !/bin/bash ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack" for kernel_module in ${ipvs_modules}; do /sbin/modinfo -F filename ${kernel_module} > /dev/null 2>&1 if [ 0 -eq 0 ]; then /sbin/modprobe ${kernel_module} fi done # 执行脚本,查看模块是否开启 chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs ip_vs_ftp 13079 0 nf_nat 26583 1 ip_vs_ftp ip_vs_sed 12519 0 ip_vs_nq 12516 0 ip_vs_sh 12688 0 ip_vs_dh 12688 0
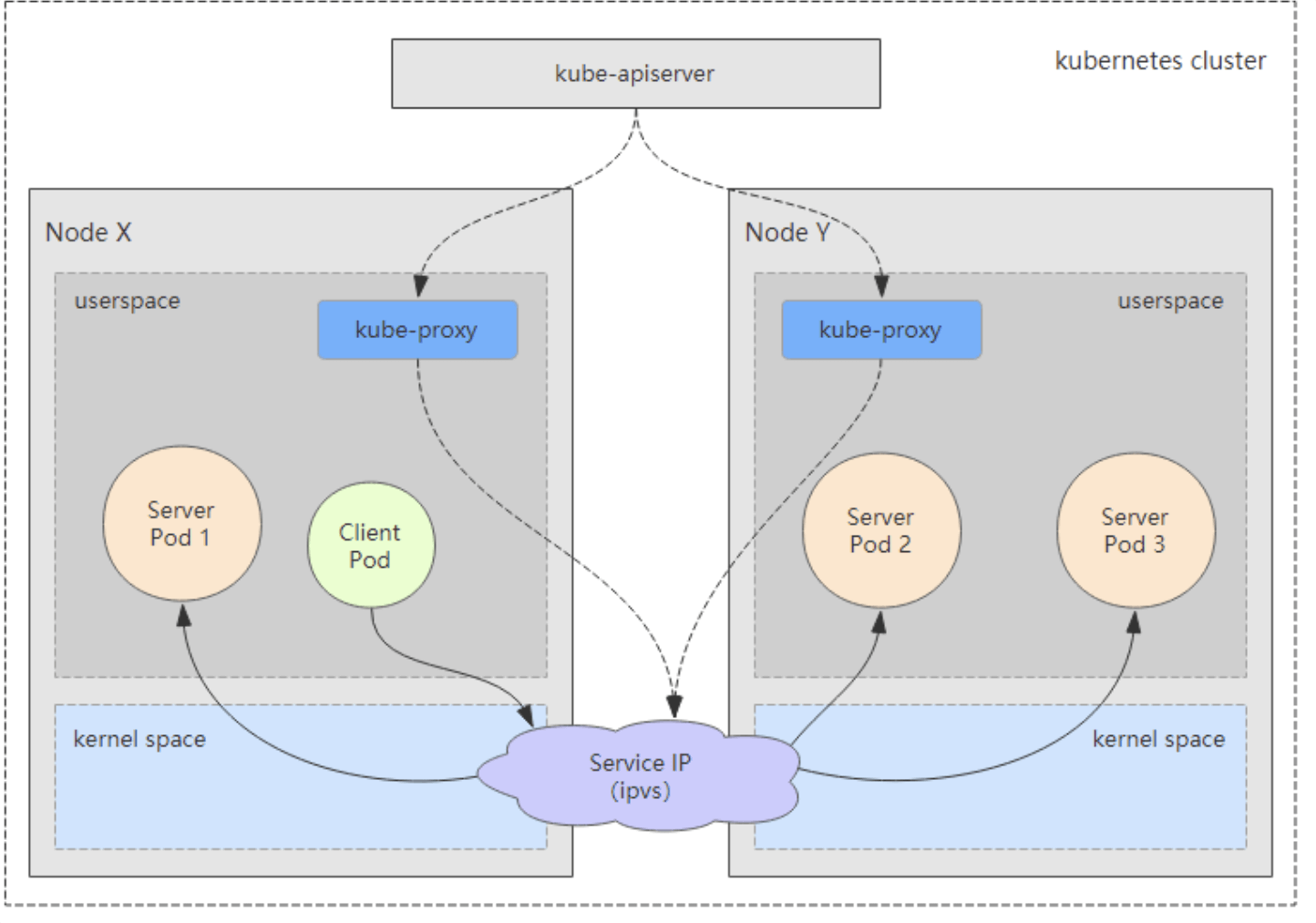
问题 1:ipvs 是什么?
ipvs (IP Virtual Server) 实现了传输层负载均衡,也就是我们常说的 4 层 LAN 交换,作为 Linux内核的一部分。ipvs 运行在主机上,在真实服务器集群前充当负载均衡器。ipvs 可以将基于 TCP 和 UDP的服务请求转发到真实服务器上,并使真实服务器的服务在单个 IP 地址上显示为虚拟服务。
问题 2:ipvs 和 iptable 对比分析
kube-proxy 支持 iptables 和 ipvs 两种模式, 在 kubernetes v1.8 中引入了 ipvs 模式,在v1.9 中处于 beta 阶段,在 v1.11 中已经正式可用了。iptables 模式在 v1.1 中就添加支持了,从v1.2 版本开始 iptables 就是 kube-proxy 默认的操作模式,ipvs 和 iptables 都是基于 netfilter的,但是 ipvs 采用的是 hash 表,因此当 service 数量达到一定规模时,hash 查表的速度优势就会显现出来,从而提高 service 的服务性能。那么 ipvs 模式和 iptables 模式之间有哪些差异呢?
1、ipvs 为大型集群提供了更好的可扩展性和性能
1 yum install -y yum-utils device-mapper-persistent-data lvm2 wget net-tools nfs-utils lrzsz gcc gcc-c++ make cmake libxml2-devel openssl-devel curl curl-devel unzip sudo ntp libaio-devel wget vim ncurses-devel autoconf automake zlib-devel python-devel epel-release openssh-server socat ipvsadm conntrack ntpdate telnet
1 2 3 4 5 6 7 8 9 # 如果用 firewalld 不习惯,可以安装 iptables # 安装 iptables yum install iptables-services -y # 禁用 iptables service iptables stop && systemctl disable iptables # 清空防火墙规则 iptables -F
安装docker
所有节点做相同操作
1 2 3 yum install docker-ce-20.10.6 docker-ce-cli-20.10.6 containerd.io -y systemctl start docker && systemctl enable docker && systemctl status docker
1 2 3 4 5 6 7 8 9 10 11 vim /etc/docker/daemon.json { "registry-mirrors":["https://rsbud4vc.mirror.aliyuncs.com","https://registry.docker-cn.com","https://docker.mirrors.ustc.edu.cn","https://dockerhub.azk8s.cn","http://hub-mirror.c.163.com","http://qtid6917.mirror.aliyuncs.com","https://rncxm540.mirror.aliyuncs.com"], "exec-opts": ["native.cgroupdriver=systemd"] # "insecure-registries" : ["192.168.1.100" ]} # 修改 docker 文件驱动为 systemd,默认为 cgroupfs,kubelet 默认使用 systemd,两者必须一致才可以。 systemctl daemon-reload && systemctl restart docker systemctl status docker
安装初始化 k8s 需要的软件包
所有节点做相同操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 yum install -y kubelet-1.20.6 kubeadm-1.20.6 kubectl-1.20.6 systemctl enable kubelet && systemctl start kubelet # 可以看到 kubelet 状态不是 running 状态,这个是正常的,不用管,等 k8s 组件起来这个kubelet 就正常了。 systemctl status kubelet ● kubelet.service - kubelet: The Kubernetes Node Agent Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled) Drop-In: /usr/lib/systemd/system/kubelet.service.d └─10-kubeadm.conf Active: activating (auto-restart) (Result: exit-code) since 日 2023-07-16 12:16:23 CST; 9s ago Docs: https://kubernetes.io/docs/ Process: 13693 ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS (code=exited, status=255) Main PID: 13693 (code=exited, status=255) # 注:每个软件包的作用 # Kubeadm: kubeadm 是一个工具,用来初始化 k8s 集群的 # kubelet: 安装在集群所有节点上,用于启动 Pod 的 # kubectl: 通过 kubectl 可以部署和管理应用,查看各种资源,创建、删除和更新各种组件
通过 keepalive+nginx 实现 k8s apiserver 节点高可用
在master1和master2上操作
1 2 # 在 master1 和 master2 上做 nginx 主备安装 yum install nginx keepalived nginx-mod-stream -y
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 vim /etc/nginx/nginx.conf user nginx; worker_processes auto; error_log /var/log/nginx/error.log; pid /run/nginx.pid; include /usr/share/nginx/modules/*.conf; events { worker_connections 1024; } # 四层负载均衡,为两台 Master apiserver 组件提供负载均衡 stream { log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent'; access_log /var/log/nginx/k8s-access.log main; upstream k8s-apiserver { server 192.168.1.180:6443; # Master1 APISERVER IP:PORT server 192.168.1.181:6443; # Master2 APISERVER IP:PORT } server { listen 16443; # 由于 nginx 与 master 节点复用,这个监听端口不能是 6443,否则会冲突 proxy_pass k8s-apiserver; } } http { log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; tcp_nopush on; tcp_nodelay on; keepalive_timeout 65; types_hash_max_size 2048; include /etc/nginx/mime.types; default_type application/octet-stream; server { listen 80 default_server; server_name _; location / { } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 vim /etc/keepalived/keepalived.conf global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id NGINX_MASTER } vrrp_script check_nginx { script "/etc/keepalived/check_nginx.sh" } vrrp_instance VI_1 { state MASTER interface ens32 # 修改为实际网卡名 virtual_router_id 51 # VRRP 路由 ID 实例,每个实例是唯一的 priority 100 # 优先级,备服务器设置 90 advert_int 1 # 指定 VRRP 心跳包通告间隔时间,默认 1 秒 authentication { auth_type PASS auth_pass 1111 } # 虚拟 IP virtual_ipaddress { 192.168.1.199/24 } track_script { check_nginx } } # vrrp_script:指定检查 nginx 工作状态脚本(根据 nginx 状态判断是否故障转移) # virtual_ipaddress:虚拟 IP(VIP)
1 2 3 4 5 6 7 8 9 vim /etc/keepalived/check_nginx.sh # !/bin/bash count=$(ps -ef |grep nginx | grep sbin | egrep -cv "grep|$$") if [ "$count" -eq 0 ];then systemctl stop keepalived fi chmod +x /etc/keepalived/check_nginx.sh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 vim /etc/keepalived/keepalived.conf global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id NGINX_MASTER } vrrp_script check_nginx { script "/etc/keepalived/check_nginx.sh" } vrrp_instance VI_1 { state BACKUP interface ens32 virtual_router_id 51 priority 90 advert_int 1 authentication { auth_type PASS auth_pass 1111 } # 虚拟 IP virtual_ipaddress { 192.168.1.199/24 } track_script { check_nginx } }
1 2 3 4 5 6 7 8 9 vim /etc/keepalived/check_nginx.sh # !/bin/bash count=$(ps -ef |grep nginx | grep sbin | egrep -cv "grep|$$") if [ "$count" -eq 0 ];then systemctl stop keepalived fi chmod +x /etc/keepalived/check_nginx.sh
1 2 3 4 5 6 7 systemctl daemon-reload systemctl start nginx && systemctl enable nginx systemctl start keepalived && systemctl enable keepalived systemctl status keepalived
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@master1 ~]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:3c:ad:b7 brd ff:ff:ff:ff:ff:ff inet 192.168.1.180/24 brd 192.168.1.255 scope global noprefixroute ens32 valid_lft forever preferred_lft forever inet 192.168.1.199/24 scope global secondary ens32 valid_lft forever preferred_lft forever inet6 fe80::f505:3807:9755:3839/64 scope link tentative noprefixroute dadfailed valid_lft forever preferred_lft forever inet6 fe80::559d:3360:2944:a1b1/64 scope link tentative noprefixroute dadfailed valid_lft forever preferred_lft forever inet6 fe80::a15a:e07:fa1e:4a60/64 scope link noprefixroute valid_lft forever preferred_lft forever 3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default link/ether 02:42:25:a7:a3:4c brd ff:ff:ff:ff:ff:ff inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0 valid_lft forever preferred_lft forever
停掉 master1 上的 nginx。Vip 会漂移到 master2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@master1 ~]# systemctl stop nginx.service [root@master2 ~]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:e0:93:9e brd ff:ff:ff:ff:ff:ff inet 192.168.1.181/24 brd 192.168.1.255 scope global noprefixroute ens32 valid_lft forever preferred_lft forever inet 192.168.1.199/24 scope global secondary ens32 valid_lft forever preferred_lft forever inet6 fe80::f505:3807:9755:3839/64 scope link tentative noprefixroute dadfailed valid_lft forever preferred_lft forever inet6 fe80::559d:3360:2944:a1b1/64 scope link noprefixroute valid_lft forever preferred_lft forever 3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default link/ether 02:42:69:d1:a0:c5 brd ff:ff:ff:ff:ff:ff inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0 valid_lft forever preferred_lft forever
启动 xianchaomaster1 上的 nginx 和 keepalived,vip 又会漂移回来
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 [root@master1 ~]# systemctl daemon-reload [root@master1 ~]# systemctl start nginx.service [root@master1 ~]# systemctl start keepalived.service [root@master1 ~]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:3c:ad:b7 brd ff:ff:ff:ff:ff:ff inet 192.168.1.180/24 brd 192.168.1.255 scope global noprefixroute ens32 valid_lft forever preferred_lft forever inet 192.168.1.199/24 scope global secondary ens32 valid_lft forever preferred_lft forever inet6 fe80::f505:3807:9755:3839/64 scope link tentative noprefixroute dadfailed valid_lft forever preferred_lft forever inet6 fe80::559d:3360:2944:a1b1/64 scope link tentative noprefixroute dadfailed valid_lft forever preferred_lft forever inet6 fe80::a15a:e07:fa1e:4a60/64 scope link noprefixroute valid_lft forever preferred_lft forever 3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default link/ether 02:42:25:a7:a3:4c brd ff:ff:ff:ff:ff:ff inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0 valid_lft forever preferred_lft forever
kubeadm 初始化 k8s 集群
在master1上创建 kubeadm-config.yaml 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 vim kubeadm-config.yaml apiVersion: kubeadm.k8s.io/v1beta2 kind: ClusterConfiguration kubernetesVersion: v1.20.6 controlPlaneEndpoint: 192.168 .1 .199 :16443 imageRepository: registry.aliyuncs.com/google_containers apiServer: certSANs: - 192.168 .1 .180 - 192.168 .1 .181 - 192.168 .1 .182 - 192.168 .1 .199 networking: podSubnet: 10.244 .0 .0 /16 serviceSubnet: 10.10 .0 .0 /16 --- apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration mode: ipvs
把初始化 k8s 集群需要的离线镜像包上传到 master1、master2、node1机器上,手动解压:
1 2 3 docker load -i k8simage-1-20-6.tar.gz # 没有离线镜像包,会从阿里云拉取镜像
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 kubeadm init --config kubeadm-config.yaml --ignore-preflight-errors=SystemVerification # 显示如下,说明安装完成 Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of control-plane nodes by copying certificate authorities and service account keys on each node and then running the following as root: # 这里是把 master 节点加入集群的命令 kubeadm join 192.168.1.199:16443 --token 3yano8.s4yo3bdw8r71y2cw \ --discovery-token-ca-cert-hash sha256:4ba3577abc437bd0aa2a93072085ec94c7471824a3690328f03cb501e6e92830 \ --control-plane Then you can join any number of worker nodes by running the following on each as root: # 这里是把 node 节点加入集群的命令 kubeadm join 192.168.1.199:16443 --token 3yano8.s4yo3bdw8r71y2cw \ --discovery-token-ca-cert-hash sha256:4ba3577abc437bd0aa2a93072085ec94c7471824a3690328f03cb501e6e92830
相当于对 kubectl 进行授权,这样 kubectl 命令可以使用这个证书对 k8s 集群进行管理
1 2 3 4 5 mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
扩容 k8s 集群-添加 master 节点
1 cd /root && mkdir -p /etc/kubernetes/pki/etcd &&mkdir -p ~/.kube/
把 master1 节点的证书拷贝到 master2 上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 scp /etc/kubernetes/pki/ca.crt master2:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/ca.key master2:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/sa.key master2:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/sa.pub master2:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/front-proxy-ca.crt master2:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/front-proxy-ca.key master2:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/etcd/ca.crt master2:/etc/kubernetes/pki/etcd/ scp /etc/kubernetes/pki/etcd/ca.key master2:/etc/kubernetes/pki/etcd/
在master1上查看加入命令
1 2 3 4 kubeadm token create --print-join-command kubeadm join 192.168.1.199:16443 --token b6s893.vo2d43b2488tif6c \ --discovery-token-ca-cert-hash sha256:4ba3577abc437bd0aa2a93072085ec94c7471824a3690328f03cb501e6e92830
master2执行命令
1 2 3 4 5 6 7 8 kubeadm join 192.168.1.199:16443 --token b6s893.vo2d43b2488tif6c \ --discovery-token-ca-cert-hash sha256:4ba3577abc437bd0aa2a93072085ec94c7471824a3690328f03cb501e6e92830 \ --control-plane --ignore-preflight-errors=SystemVerification mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
1 2 3 4 5 6 # 可以看到 master2 已经加入到集群了 kubectl get nodes NAME STATUS ROLES AGE VERSION master1 NotReady control-plane,master 33m v1.20.6 master2 NotReady control-plane,master 80s v1.20.6
扩容 k8s 集群-添加 node 节点
1 2 3 4 kubeadm token create --print-join-command kubeadm join 192.168.1.199:16443 --token flsons.7c66kxcihkjpgnly \ --discovery-token-ca-cert-hash sha256:4ba3577abc437bd0aa2a93072085ec94c7471824a3690328f03cb501e6e92830
1 2 3 kubeadm join 192.168.1.199:16443 --token flsons.7c66kxcihkjpgnly \ --discovery-token-ca-cert-hash sha256:4ba3577abc437bd0aa2a93072085ec94c7471824a3690328f03cb501e6e92830 \ --ignore-preflight-errors=SystemVerification
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 kubectl get nodes NAME STATUS ROLES AGE VERSION master1 NotReady control-plane,master 64m v1.20.6 master2 NotReady control-plane,master 31m v1.20.6 node1 NotReady <none> 42s v1.20.6 # 可以看到 node1 的 ROLES 角色为空,<none>就表示这个节点是工作节点。 # 可以把 node1 的 ROLES 变成 work kubectl label node node1 node-role.kubernetes.io/worker=worker kubectl get nodes NAME STATUS ROLES AGE VERSION master1 NotReady control-plane,master 65m v1.20.6 master2 NotReady control-plane,master 33m v1.20.6 node1 NotReady worker 2m18s v1.20.6 kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE coredns-7f89b7bc75-2ht5z 0/1 Pending 0 66m coredns-7f89b7bc75-xv9mv 0/1 Pending 0 66m etcd-master1 1/1 Running 0 66m etcd-master2 1/1 Running 0 33m kube-apiserver-master1 1/1 Running 1 66m kube-apiserver-master2 1/1 Running 0 33m kube-controller-manager-master1 1/1 Running 1 66m kube-controller-manager-master2 1/1 Running 0 33m kube-proxy-q9dq7 1/1 Running 0 2m48s kube-proxy-w664w 1/1 Running 0 66m kube-proxy-wkqdv 1/1 Running 0 33m kube-scheduler-master1 1/1 Running 1 66m kube-scheduler-master2 1/1 Running 0 33m # coredns-7f89b7bc75-2ht5z 是 pending 状态,这是因为还没有安装网络插件,等到下面安装好网络插件之后这个 cordns 就会变成 running 了
安装 kubernetes 网络组件-Calico
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 # 在master1上安装 wget https://docs.projectcalico.org/manifests/calico.yaml # 版本可能不同会有报错 # apiVersion: policy/v1 >改>为> policy/v1beta1 # kind: PodDisruptionBudget # 有镜像包的话,三台虚拟机上都需要docker load # 有自己的镜像站让其他节点加入就行 kubectl apply -f calico.yaml kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE calico-kube-controllers-6949477b58-tf9dm 1/1 Running 0 27s calico-node-bmr42 1/1 Running 0 27s calico-node-qfkwj 1/1 Running 0 27s calico-node-tqb7c 1/1 Running 0 27s coredns-7f89b7bc75-2ht5z 1/1 Running 0 151m coredns-7f89b7bc75-xv9mv 1/1 Running 0 151m etcd-master1 1/1 Running 0 151m etcd-master2 1/1 Running 0 119m kube-apiserver-master1 1/1 Running 1 151m kube-apiserver-master2 1/1 Running 0 119m kube-controller-manager-master1 1/1 Running 1 151m kube-controller-manager-master2 1/1 Running 0 119m kube-proxy-q9dq7 1/1 Running 0 88m kube-proxy-w664w 1/1 Running 0 151m kube-proxy-wkqdv 1/1 Running 0 119m kube-scheduler-master1 1/1 Running 1 151m kube-scheduler-master2 1/1 Running 0 119m # coredns-这个 pod 现在是 running 状态,运行正常
1 2 3 4 5 6 7 # STATUS 状态是 Ready,说明 k8s 集群正常运行了 kubectl get nodes NAME STATUS ROLES AGE VERSION master1 Ready control-plane,master 153m v1.20.6 master2 Ready control-plane,master 120m v1.20.6 node1 Ready worker 89m v1.20.6
测试在 k8s 创建 pod 是否可以正常访问网络
1 2 3 4 5 6 7 8 kubectl run busybox --image busybox:1.28 --restart=Never --rm -it -- sh / # ping baidu.com PING baidu.com (39.156.66.10): 56 data bytes 64 bytes from 39.156.66.10: seq=0 ttl=127 time=18.707 ms 64 bytes from 39.156.66.10: seq=1 ttl=127 time=18.246 ms # 通过上面可以看到能访问网络,说明 calico 网络插件已经被正常安装了
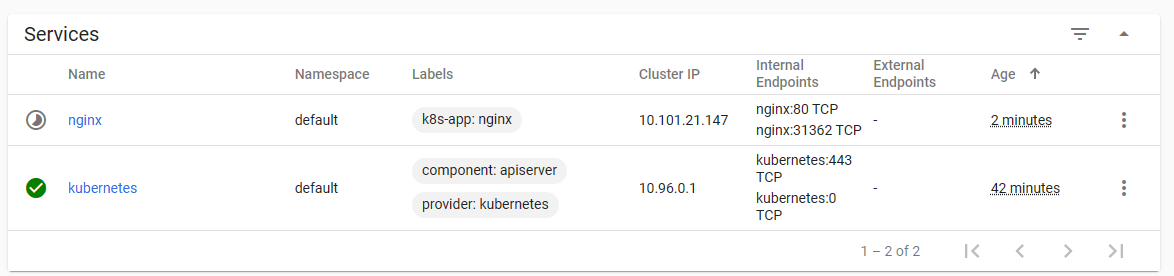
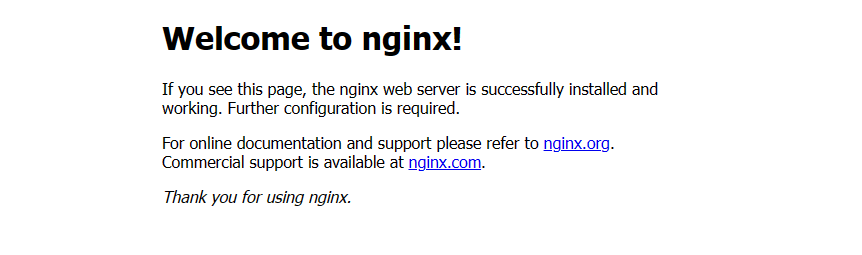
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 [root@master1 ~]# cat tomcat.yaml apiVersion: v1 #pod属于k8s核心组v1 kind: Pod #创建的是一个Pod资源 metadata: #元数据 name: demo-pod #pod名字 namespace: default #pod所属的名称空间 labels: app: myapp #pod具有的标签 env: dev #pod具有的标签 spec: containers: #定义一个容器,容器是对象列表,下面可以有多个name - name: tomcat-pod-java #容器的名字 ports: - containerPort: 8080 image: tomcat:8.5-jre8-alpine #容器使用的镜像 imagePullPolicy: IfNotPresent [root@master1 ~]# cat tomcat-service.yaml apiVersion: v1 kind: Service metadata: name: tomcat spec: type: NodePort ports: - port: 8080 nodePort: 30080 selector: app: myapp env: dev [root@master1 ~]# kubectl apply -f tomcat.yaml [root@master1 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES demo-pod 1/1 Running 0 7m44s 10.244.166.133 node1 <none> <none> [root@master1 ~]# curl http://10.244.166.133:8080 -I HTTP/1.1 200 # 状态码 200 为正常 Content-Type: text/html;charset=UTF-8 Transfer-Encoding: chunked Date: Sun, 16 Jul 2023 10:32:55 GMT [root@master1 ~]# kubectl apply -f tomcat-service.yaml [root@master1 ~]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.10.0.1 <none> 443/TCP 160m tomcat NodePort 10.10.24.186 <none> 8080:30080/TCP 34s # 浏览器访问master节点的IP:30080,即可打开tomcat
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 kubectl run busybox --image busybox:1.28 --restart=Never --rm -it busybox -- sh / # nslookup kubernetes.default.svc.cluster.local Server: 10.10.0.10 Address 1: 10.10.0.10 kube-dns.kube-system.svc.cluster.local Name: kubernetes.default.svc.cluster.local Address 1: 10.10.0.1 kubernetes.default.svc.cluster.local / # nslookup tomcat.default.svc.cluster.local Server: 10.10.0.10 Address 1: 10.10.0.10 kube-dns.kube-system.svc.cluster.local Name: tomcat.default.svc.cluster.local Address 1: 10.10.24.186 tomcat.default.svc.cluster.local # 10.10.0.10 就是我们 coreDNS 的 clusterIP,说明 coreDNS 配置好了。 [root@master1 ~]# kubectl get svc -n kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kube-dns ClusterIP 10.10.0.10 <none> 53/UDP,53/TCP,9153/TCP 3h2m # 解析内部 Service 的名称,是通过 coreDNS 去解析的。 # 10.10.24.186 是创建的 tomcat 的 service ip [root@master1 ~]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.10.0.1 <none> 443/TCP 3h3m tomcat NodePort 10.10.24.186 <none> 8080:30080/TCP 22m # 注意:busybox 要用指定的 1.28 版本,不能用最新版本,最新版本,nslookup 会解析不到 dns 和 ip
二进制安装多master的k8s集群 k8s环境规划
centos7.6操作系统,4G/4CPU/100G,网络NAT,开启虚拟化
podSubnet(pod网段)10.0.0.0/16
k8s集群角色
ip
主机名
安装的组件
控制节点
192.168.1.180
master1
apiserver、controller-manager、scheduler、etcd、docker、keepalived、nginx
控制节点
192.168.1.181
master2
apiserver、controller-manager、scheduler、etcd、docker、keepalived、nginx
控制节点
192.168.1.182
master3
apiserver、controller-manager、scheduler、etcd、docker
工作节点
192.168.1.183
node1
kubelet、kube-proxy、docker、calico、coredns
VIP
192.168.1.199
初始化
所有主机做以下操作
1 2 3 4 echo "192.168.1.180 master1 192.168.1.181 master2 192.168.1.182 master3 192.168.1.183 node1" >> /etc/hosts
1 2 3 ssh-keygen for i in master1 master2 master3 node1;do ssh-copy-id root@$i;done
1 systemctl disable --now firewalld
1 2 3 4 5 6 7 sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config # 重启生效 reboot # 显示 Disabled 说明 selinux 已经关闭 getenforce
1 2 3 4 5 6 7 8 # 临时关闭 swapoff -a # 永久关闭:注释 swap 挂载,给 swap 这行开头加一下注释 vim /etc/fstab # /dev/mapper/centos-swap swap swap defaults 0 0 # 如果是克隆的虚拟机,需要删除 UUID
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # 加载 br_netfilter 模块 modprobe br_netfilter # 验证模块是否加载成功: lsmod |grep br_netfilter # 修改内核参数 cat > /etc/sysctl.d/k8s.conf <<EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 EOF # 使刚才修改的内核参数生效 sysctl -p /etc/sysctl.d/k8s.conf
1 2 3 4 5 6 7 8 9 10 11 12 # 备份基础repo源 mkdir /root/repo.bak cd /etc/yum.repos.d/ mv * /root/repo.bak/ # 拉取阿里云repo源 curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo # 配置国内阿里云 docker 的 repo 源 yum install yum-utils -y yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
1 2 3 4 5 6 7 8 9 10 11 12 # 安装 ntpdate 命令, yum install ntpdate -y # 跟网络源做同步 ntpdate cn.pool.ntp.org # 把时间同步做成计划任务 crontab -e * */1 * * * /usr/sbin/ntpdate cn.pool.ntp.org # 重启 crond 服务 service crond restart
1 2 3 4 5 6 7 8 # 安装 iptables yum install iptables-services -y # 禁用 iptables service iptables stop && systemctl disable iptables # 清空防火墙规则 iptables -F
不开启 ipvs 将会使用 iptables 进行数据包转发,但是效率低,所以官网推荐需要开通 ipvs。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 编写脚本开启模块 vim /etc/sysconfig/modules/ipvs.modules # !/bin/bash ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack" for kernel_module in ${ipvs_modules}; do /sbin/modinfo -F filename ${kernel_module} > /dev/null 2>&1 if [ 0 -eq 0 ]; then /sbin/modprobe ${kernel_module} fi done # 执行脚本,查看模块是否开启 chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs ip_vs_ftp 13079 0 nf_nat 26583 1 ip_vs_ftp ip_vs_sed 12519 0 ip_vs_nq 12516 0 ip_vs_sh 12688 0 ip_vs_dh 12688 0
1 yum install -y yum-utils device-mapper-persistent-data lvm2 wget net-tools nfs-utils lrzsz gcc gcc-c++ make cmake libxml2-devel openssl-devel curl curl-devel unzip sudo ntp libaio-devel wget vim ncurses-devel autoconf automake zlib-devel python-devel epel-release openssh-server socat ipvsadm conntrack ntpdate telnet rsync
1 2 3 yum install docker-ce docker-ce-cli containerd.io -y systemctl start docker && systemctl enable docker.service && systemctl status docker
1 2 3 4 5 6 7 8 9 10 11 tee /etc/docker/daemon.json << 'EOF' { "registry-mirrors":["https://rsbud4vc.mirror.aliyuncs.com","https://registry.docker-cn.com","https://docker.mirrors.ustc.edu.cn","https://dockerhub.azk8s.cn","http://hub-mirror.c.163.com","http://qtid6917.mirror.aliyuncs.com","https://rncxm540.mirror.aliyuncs.com"], "exec-opts": ["native.cgroupdriver=systemd"] # "insecure-registries" : ["192.168.1.100" ]} EOF systemctl daemon-reload systemctl restart docker systemctl status docker
搭建etcd集群
1 2 3 4 5 [root@master1 ~]# mkdir -p /etc/etcd/ssl [root@master2 ~]# mkdir -p /etc/etcd/ssl [root@master3 ~]# mkdir -p /etc/etcd/ssl
先在master1上操作,后面会拷贝给其他master主机
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@master1 ~]# mkdir /data/work -p [root@master1 ~]# cd /data/work/ # cfssl-certinfo_linux-amd64 、cfssljson_linux-amd64 、cfssl_linux-amd64 上传到/data/work/目录下 [root@master1 work]# ls cfssl-certinfo_linux-amd64 cfssljson_linux-amd64 cfssl_linux-amd64 [root@master1 work]# chmod +x * [root@master1 work]# mv cfssl_linux-amd64 /usr/local/bin/cfssl [root@master1 work]# mv cfssljson_linux-amd64 /usr/local/bin/cfssljson [root@master1 work]# mv cfssl-certinfo_linux-amd64 /usr/local/bin/cfssl-certinfo
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 # 生成ca证书请求文件 [root@master1 work]# cat ca-csr.json { "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "Hubei", "L": "Wuhan", "O": "k8s", "OU": "system" } ], "ca": { "expiry": "87600h" } } # CN:Common Name(公用名称),kube-apiserver 从证书中提取该字段作为请求的用户名 (User Name);浏览器使用该字段验证网站是否合法;对于 SSL 证书,一般为网站域名;而对于代码签名证书则为申请单位名称;而对于客户端证书则为证书申请者的姓名。 # O:Organization(单位名称),kube-apiserver 从证书中提取该字段作为请求用户所属的组 (Group);对于 SSL 证书,一般为网站域名;而对于代码签名证书则为申请单位名称;而对于客户端单位证书则为证书申请者所在单位名称。 # L 字段:所在城市 # S 字段:所在省份 # C 字段:只能是国家字母缩写,如中国:CN [root@master1 work]# cfssl gencert -initca ca-csr.json | cfssljson -bare ca 2023/07/17 18:24:49 [INFO] generating a new CA key and certificate from CSR 2023/07/17 18:24:49 [INFO] generate received request 2023/07/17 18:24:49 [INFO] received CSR 2023/07/17 18:24:49 [INFO] generating key: rsa-2048 2023/07/17 18:24:49 [INFO] encoded CSR 2023/07/17 18:24:49 [INFO] signed certificate with serial number 217844315801648044942786609438022401383793351285 # 生成ca证书文件 [root@master1 work]# cat ca-config.json { "signing": { "default": { "expiry": "87600h" }, "profiles": { "kubernetes": { "usages": [ "signing", "key encipherment", "server auth", "client auth" ], "expiry": "87600h" } } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 [root@master1 work]# cat etcd-csr.json { "CN": "etcd", "hosts": [ "127.0.0.1", "192.168.1.180", "192.168.1.181", "192.168.1.182", "192.168.1.199" ], "key": { "algo": "rsa", "size": 2048 }, "names": [{ "C": "CN", "ST": "Hubei", "L": "Wuhan", "O": "k8s", "OU": "system" }] } [root@master1 work]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes etcd-csr.json | cfssljson -bare etcd 2023/07/17 18:28:48 [INFO] generate received request 2023/07/17 18:28:48 [INFO] received CSR 2023/07/17 18:28:48 [INFO] generating key: rsa-2048 2023/07/17 18:28:48 [INFO] encoded CSR 2023/07/17 18:28:48 [INFO] signed certificate with serial number 454088009324202770940629185352283532986074407108 2023/07/17 18:28:48 [WARNING] This certificate lacks a "hosts" field. This makes it unsuitable for websites. For more information see the Baseline Requirements for the Issuance and Management of Publicly-Trusted Certificates, v.1.1.6, from the CA/Browser Forum (https://cabforum.org); specifically, section 10.2.3 ("Information Requirements"). [root@master1 work]# ls etcd*.pem etcd-key.pem etcd.pem
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 # 把 etcd-v3.4.13-linux-amd64.tar.gz 上传到/data/work 目录下 [root@master1 work]# tar xf etcd-v3.4.13-linux-amd64.tar.gz [root@master1 work]# cp -p etcd-v3.4.13-linux-amd64/etcd* /usr/local/bin/ [root@master1 work]# scp -r etcd-v3.4.13-linux-amd64/etcd* master2:/usr/local/bin/ [root@master1 work]# scp -r etcd-v3.4.13-linux-amd64/etcd* master3:/usr/local/bin/ # 创建配置文件 [root@master1 work]# cat etcd.conf # [Member] ETCD_NAME="etcd1" ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="https://192.168.1.180:2380" ETCD_LISTEN_CLIENT_URLS="https://192.168.1.180:2379,http://127.0.0.1:2379" # [Clustering] ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.1.180:2380" ETCD_ADVERTISE_CLIENT_URLS="https://192.168.1.180:2379" ETCD_INITIAL_CLUSTER="etcd1=https://192.168.1.180:2380,etcd2=https://192.168.1.181:2380,etcd3=https://192.168.1.182:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new" # ETCD_NAME:节点名称,集群中唯一 # ETCD_DATA_DIR:数据目录 # ETCD_LISTEN_PEER_URLS:集群通信监听地址 # ETCD_LISTEN_CLIENT_URLS:客户端访问监听地址 # ETCD_INITIAL_ADVERTISE_PEER_URLS:集群通告地址 # ETCD_ADVERTISE_CLIENT_URLS:客户端通告地址 # ETCD_INITIAL_CLUSTER:集群节点地址 # ETCD_INITIAL_CLUSTER_TOKEN:集群 Token # ETCD_INITIAL_CLUSTER_STATE:加入集群的当前状态,new 是新集群,existing 表示加入已有集群 # 创建启动服务文件 [root@master1 work]# cat etcd.service [Unit] Description=Etcd Server After=network.target After=network-online.target Wants=network-online.target [Service] Type=notify EnvironmentFile=-/etc/etcd/etcd.conf WorkingDirectory=/var/lib/etcd/ ExecStart=/usr/local/bin/etcd \ --cert-file=/etc/etcd/ssl/etcd.pem \ --key-file=/etc/etcd/ssl/etcd-key.pem \ --trusted-ca-file=/etc/etcd/ssl/ca.pem \ --peer-cert-file=/etc/etcd/ssl/etcd.pem \ --peer-key-file=/etc/etcd/ssl/etcd-key.pem \ --peer-trusted-ca-file=/etc/etcd/ssl/ca.pem \ --peer-client-cert-auth \ --client-cert-auth Restart=on-failure RestartSec=5 LimitNOFILE=65536 [Install] WantedBy=multi-user.target [root@master1 work]# cp ca*.pem /etc/etcd/ssl/ [root@master1 work]# cp etcd*.pem /etc/etcd/ssl/ [root@master1 work]# cp etcd.conf /etc/etcd/ [root@master1 work]# cp etcd.service /usr/lib/systemd/system/ [root@master1 work]# for i in master2 master3;do rsync -vaz etcd.conf $i:/etc/etcd/;done [root@master1 work]# for i in master2 master3;do rsync -vaz ca*.pem $i:/etc/etcd/ssl/;done [root@master1 work]# for i in master2 master3;do rsync -vaz etcd*.pem $i:/etc/etcd/ssl/;done [root@master1 work]# for i in master2 master3;do rsync -vaz etcd.service $i:/usr/lib/systemd/system/;done
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 [root@master1 work]# mkdir -p /var/lib/etcd/default.etcd [root@master2 ~]# mkdir -p /var/lib/etcd/default.etcd [root@master3 ~]# mkdir -p /var/lib/etcd/default.etcd [root@master2 ~]# vim /etc/etcd/etcd.conf # [Member] ETCD_NAME="etcd2" ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="https://192.168.1.181:2380" ETCD_LISTEN_CLIENT_URLS="https://192.168.1.181:2379,http://127.0.0.1:2379" # [Clustering] ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.1.181:2380" ETCD_ADVERTISE_CLIENT_URLS="https://192.168.1.181:2379" ETCD_INITIAL_CLUSTER="etcd1=https://192.168.1.180:2380,etcd2=https://192.168.1.181:2380,etcd3=https://192.168.1.182:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new" [root@master3 ~]# vim /etc/etcd/etcd.conf # [Member] ETCD_NAME="etcd3" ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="https://192.168.1.182:2380" ETCD_LISTEN_CLIENT_URLS="https://192.168.1.182:2379,http://127.0.0.1:2379" # [Clustering] ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.1.182:2380" ETCD_ADVERTISE_CLIENT_URLS="https://192.168.1.182:2379" ETCD_INITIAL_CLUSTER="etcd1=https://192.168.1.180:2380,etcd2=https://192.168.1.181:2380,etcd3=https://192.168.1.182:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new" [root@master1 ~]# systemctl daemon-reload && systemctl enable etcd.service && systemctl start etcd.service # 启动 etcd 的时候,先启动 master1 的 etcd 服务,会一直卡住在启动的状态,然后接着再启动 master2 的 etcd,这样 master1 这个节点 etcd 才会正常起来 [root@master2 ~]# systemctl daemon-reload && systemctl enable etcd.service && systemctl start etcd.service [root@master3 ~]# systemctl daemon-reload && systemctl enable etcd.service && systemctl start etcd.service
1 2 3 4 5 6 7 8 9 10 [root@master1 ~]# ETCDCTL_API=3 [root@master1 ~]# /usr/local/bin/etcdctl --write-out=table --cacert=/etc/etcd/ssl/ca.pem --cert=/etc/etcd/ssl/etcd.pem --key=/etc/etcd/ssl/etcd-key.pem --endpoints=https://192.168.1.180:2379,https://192.168.1.181:2379,https://192.168.1.182:2379 endpoint health +----------------------------+--------+-------------+-------+ | ENDPOINT | HEALTH | TOOK | ERROR | +----------------------------+--------+-------------+-------+ | https://192.168.1.180:2379 | true | 10.004032ms | | | https://192.168.1.181:2379 | true | 14.682589ms | | | https://192.168.1.182:2379 | true | 14.800295ms | | +----------------------------+--------+-------------+-------+
安装kubernetes组件 下载安装包
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 把 kubernetes-server-linux-amd64.tar.gz 上传到 xianchaomaster1 上的/data/work 目录下 [root@master1 work]# tar xf kubernetes-server-linux-amd64.tar.gz [root@master1 work]# cd kubernetes/server/bin/ [root@master1 bin]# cp kube-apiserver kube-controller-manager kube-scheduler kubectl /usr/local/bin/ [root@master1 bin]# rsync -vaz kube-apiserver kube-controller-manager kube-scheduler kubectl master2:/usr/local/bin/ [root@master1 bin]# rsync -vaz kube-apiserver kube-controller-manager kube-scheduler kubectl master3:/usr/local/bin/ [root@master1 bin]# scp kubelet kube-proxy node1:/usr/local/bin/ [root@master1 bin]# cd /data/work/ [root@master1 work]# mkdir -p /etc/kubernetes/ssl [root@master1 work]# mkdir /var/log/kubernetes
部署apiserver组件
启动 TLS Bootstrapping 机制
Master apiserver 启用 TLS 认证后,每个节点的 kubelet 组件都要使用由 apiserver 使用的 CA 签发的有效证书才能与 apiserver 通讯,当 Node 节点很多时,这种客户端证书颁发需要大量工作,同样也会增加集群扩展复杂度。
为了简化流程,Kubernetes 引入了 TLS bootstraping 机制来自动颁发客户端证书,kubelet 会以一个低权限用户自动向 apiserver 申请证书,kubelet 的证书由 apiserver 动态签署。
Bootstrap 是很多系统中都存在的程序,比如 Linux 的 bootstrap,bootstrap 一般都是作为预先配置在开启或者系统启动的时候加载,这可以用来生成一个指定环境。Kubernetes 的 kubelet 在启动时同样可以加载一个这样的配置文件,这个文件的内容类似如下形式:
1 2 3 4 5 6 7 8 9 10 11 12 13 apiVersion: v1 clusters: null contexts: - context: cluster: kubernetes user: kubelet-bootstra name: default current-context: default kind: Config preferences: {}users: - name: kubelet-bootstrap user: {}
TLS bootstrapping 具体引导过程
1.TLS 作用
2.RBAC 作用
以上说明:第一,想要与 apiserver 通讯就必须采用由 apiserver CA 签发的证书,这样才能形成信任关系,建立 TLS 连接;第二,可以通过证书的 CN、O 字段来提供 RBAC 所需的用户与用户组。
kubelet 首次启动流程
TLS bootstrapping 功能是让 kubelet 组件去 apiserver 申请证书,然后用于连接 apiserver;那么第一次启动时没有证书如何连接 apiserver ?
在 apiserver 配置中指定了一个 token.csv 文件,该文件中是一个预设的用户配置;同时该用户的 Token 和 由 apiserver 的 CA 签发的用户被写入了 kubelet 所使用的 bootstrap.kubeconfig 配置文件中;这样在首次请求时,kubelet 使用 bootstrap.kubeconfig 中被 apiserver CA 签发证书时信任的用户来与 apiserver 建立TLS 通讯,使用 bootstrap.kubeconfig 中的用户 Token 来向 apiserver 声明自己的 RBAC 授权身份.
token.csv 格式:
3940fd7fbb391d1b4d861ad17a1f0613,kubelet-bootstrap,10001,”system:kubelet-bootstrap”
首次启动时,可能与遇到 kubelet 报 401 无权访问 apiserver 的错误;这是因为在默认情况下,kubelet 通过 bootstrap.kubeconfig 中的预设用户 Token 声明了自己的身份,然后创建CSR 请求;但是不要忘记这个用户在我们不处理的情况下他没任何权限的,包括创建 CSR 请求;所以需要创建一个 ClusterRoleBinding,将预设用户 kubelet-bootstrap 与内置的ClusterRole system:node-bootstrapper 绑定到一起,使其能够发起 CSR 请求。
1 2 3 4 5 6 7 [root@master1 work]# cat > token.csv << EOF $ (head -c 16 /dev/urandom | od -An -t x | tr -d ' ' ),kubelet-bootstrap,10001,"system:kubelet-bootstrap" EOF # 格式:token,用户名,UID,用户组 [root@master1 work]# cat token.csv c13d0ed83fbeb79f18ef50a60f3646e9,kubelet-bootstrap,10001,"system:kubelet-bootstrap"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 [ root@master1 work] # cat kube-apiserver-csr.json{ "CN" : "kubernetes" , "hosts" : [ "127.0.0.1" , "192.168.1.180" , "192.168.1.181" , "192.168.1.182" , "192.168.1.183" , "192.168.1.199" , "10.255.0.1" , "kubernetes" , "kubernetes.default" , "kubernetes.default.svc" , "kubernetes.default.svc.cluster" , "kubernetes.default.svc.cluster.local" ] , "key" : { "algo" : "rsa" , "size" : 2048 } , "names" : [ { "C" : "CN" , "ST" : "Hubei" , "L" : "Wuhan" , "O" : "k8s" , "OU" : "system" } ] } # 注: 如果 hosts 字段不为空则需要指定授权使用该证书的 IP 或域名列表。 由于该证书后续被kubernetes master 集群使用,需要将 master 节点的 IP 都填上,同时还需要填写 service 网络的首个IP。(一般是 kube-apiserver 指定的 service-cluster-ip-range 网段的第一个 IP,如 10.255 .0 .1 )
1 2 3 4 5 6 7 8 9 10 [root@master1 work]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-apiserver-csr.json | cfssljson -bare kube-apiserver 2023/07/17 21:14:49 [INFO] generate received request 2023/07/17 21:14:49 [INFO] received CSR 2023/07/17 21:14:49 [INFO] generating key: rsa-2048 2023/07/17 21:14:49 [INFO] encoded CSR 2023/07/17 21:14:49 [INFO] signed certificate with serial number 60558345437536204224759334781081714276751605494 2023/07/17 21:14:49 [WARNING] This certificate lacks a "hosts" field. This makes it unsuitable for websites. For more information see the Baseline Requirements for the Issuance and Management of Publicly-Trusted Certificates, v.1.1.6, from the CA/Browser Forum (https://cabforum.org); specifically, section 10.2.3 ("Information Requirements").
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 [root@master1 work] KUBE_APISERVER_OPTS="--enable-admission-plugins=NamespaceLifecycle,NodeRestriction,LimitRanger,ServiceAccount,DefaultStorageClass,ResourceQuota \ --anonymous-auth=false \ --bind-address=192.168.1.180 \ --secure-port=6443 \ --advertise-address=192.168.1.180 \ --insecure-port=0 \ --authorization-mode=Node,RBAC \ --runtime-config=api/all=true \ --enable-bootstrap-token-auth \ --service-cluster-ip-range=10.255.0.0/16 \ --token-auth-file=/etc/kubernetes/token.csv \ --service-node-port-range=30000-50000 \ --tls-cert-file=/etc/kubernetes/ssl/kube-apiserver.pem \ --tls-private-key-file=/etc/kubernetes/ssl/kube-apiserver-key.pem \ --client-ca-file=/etc/kubernetes/ssl/ca.pem \ --kubelet-client-certificate=/etc/kubernetes/ssl/kube-apiserver.pem \ --kubelet-client-key=/etc/kubernetes/ssl/kube-apiserver-key.pem \ --service-account-key-file=/etc/kubernetes/ssl/ca-key.pem \ --service-account-signing-key-file=/etc/kubernetes/ssl/ca-key.pem \ --service-account-issuer=https://kubernetes.default.svc.cluster.local \ --etcd-cafile=/etc/etcd/ssl/ca.pem \ --etcd-certfile=/etc/etcd/ssl/etcd.pem \ --etcd-keyfile=/etc/etcd/ssl/etcd-key.pem \ --etcd-servers=https://192.168.1.180:2379,https://192.168.1.181:2379,https://192.168.1.182:2379 \ --enable-swagger-ui=true \ --allow-privileged=true \ --apiserver-count=3 \ --audit-log-maxage=30 \ --audit-log-maxbackup=3 \ --audit-log-maxsize=100 \ --audit-log-path=/var/log/kube-apiserver-audit.log \ --event-ttl=1h \ --alsologtostderr=true \ --logtostderr=false \ --log-dir=/var/log/kubernetes \ --v=4" --logtostderr:启用日志 --v:日志等级 --log-dir:日志目录 --etcd-servers:etcd 集群地址 --bind-address:监听地址 --secure-port:https 安全端口 --advertise-address:集群通告地址 --allow-privileged:启用授权 --service-cluster-ip-range:Service 虚拟 IP 地址段 --enable-admission-plugins:准入控制模块 --authorization-mode:认证授权,启用 RBAC 授权和节点自管理 --enable-bootstrap-token-auth:启用 TLS bootstrap 机制 --token-auth-file:bootstrap token 文件 --service-node-port-range:Service nodeport 类型默认分配端口范围 --kubelet-client-xxx:apiserver 访问 kubelet 客户端证书 --tls-xxx-file:apiserver https 证书 --etcd-xxxfile:连接 Etcd 集群证书 – -audit-log-xxx:审计日志
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [root@master1 work]# cat kube-apiserver.service [Unit] Description=Kubernetes API Server Documentation=https://github.com/kubernetes/kubernetes After=etcd.service Wants=etcd.service [Service] EnvironmentFile=-/etc/kubernetes/kube-apiserver.conf ExecStart=/usr/local/bin/kube-apiserver $KUBE_APISERVER_OPTS Restart=on-failure RestartSec=5 Type=notify LimitNOFILE=65536 [Install] WantedBy=multi-user.target
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 [root@master1 work]# cp ca*.pem /etc/kubernetes/ssl [root@master1 work]# cp kube-apiserver*.pem /etc/kubernetes/ssl/ [root@master1 work]# cp token.csv /etc/kubernetes/ [root@master1 work]# cp kube-apiserver.conf /etc/kubernetes/ [root@master1 work]# cp kube-apiserver.service /usr/lib/systemd/system/ [root@master1 work]# rsync -vaz token.csv master2:/etc/kubernetes/ [root@master1 work]# rsync -vaz token.csv master3:/etc/kubernetes/ [root@master1 work]# rsync -vaz kube-apiserver*.pem master2:/etc/kubernetes/ssl/ [root@master1 work]# rsync -vaz kube-apiserver*.pem master3:/etc/kubernetes/ssl/ [root@master1 work]# rsync -vaz ca*.pem master2:/etc/kubernetes/ssl/ [root@master1 work]# rsync -vaz ca*.pem master3:/etc/kubernetes/ssl/ [root@master1 work]# rsync -vaz kube-apiserver.conf master2:/etc/kubernetes/ [root@master1 work]# rsync -vaz kube-apiserver.conf master3:/etc/kubernetes/ [root@master1 work]# rsync -vaz kube-apiserver.service master2:/usr/lib/systemd/system/ [root@master1 work]# rsync -vaz kube-apiserver.service master3:/usr/lib/systemd/system/ # 注:master2 和 master3 配置文件 kube-apiserver.conf 的 IP 地址修改为实际的本机 IP [root@master2 ~]# cat /etc/kubernetes/kube-apiserver.conf KUBE_APISERVER_OPTS="--enable-admission-plugins=NamespaceLifecycle,NodeRestriction,LimitRanger,ServiceAccount,DefaultStorageClass,ResourceQuota \ --anonymous-auth=false \ --bind-address=192.168.1.181 \ --secure-port=6443 \ --advertise-address=192.168.1.181 \ --insecure-port=0 \ --authorization-mode=Node,RBAC \ --runtime-config=api/all=true \ --enable-bootstrap-token-auth \ --service-cluster-ip-range=10.255.0.0/16 \ --token-auth-file=/etc/kubernetes/token.csv \ --service-node-port-range=30000-50000 \ --tls-cert-file=/etc/kubernetes/ssl/kube-apiserver.pem \ --tls-private-key-file=/etc/kubernetes/ssl/kube-apiserver-key.pem \ --client-ca-file=/etc/kubernetes/ssl/ca.pem \ --kubelet-client-certificate=/etc/kubernetes/ssl/kube-apiserver.pem \ --kubelet-client-key=/etc/kubernetes/ssl/kube-apiserver-key.pem \ --service-account-key-file=/etc/kubernetes/ssl/ca-key.pem \ --service-account-signing-key-file=/etc/kubernetes/ssl/ca-key.pem \ --service-account-issuer=https://kubernetes.default.svc.cluster.local \ --etcd-cafile=/etc/etcd/ssl/ca.pem \ --etcd-certfile=/etc/etcd/ssl/etcd.pem \ --etcd-keyfile=/etc/etcd/ssl/etcd-key.pem \ --etcd-servers=https://192.168.1.180:2379,https://192.168.1.181:2379,https://192.168.1.182:2379 \ --enable-swagger-ui=true \ --allow-privileged=true \ --apiserver-count=3 \ --audit-log-maxage=30 \ --audit-log-maxbackup=3 \ --audit-log-maxsize=100 \ --audit-log-path=/var/log/kube-apiserver-audit.log \ --event-ttl=1h \ --alsologtostderr=true \ --logtostderr=false \ --log-dir=/var/log/kubernetes \ --v=4" [root@master3 ~]# cat /etc/kubernetes/kube-apiserver.conf KUBE_APISERVER_OPTS="--enable-admission-plugins=NamespaceLifecycle,NodeRestriction,LimitRanger,ServiceAccount,DefaultStorageClass,ResourceQuota \ --anonymous-auth=false \ --bind-address=192.168.1.182 \ --secure-port=6443 \ --advertise-address=192.168.1.182 \ --insecure-port=0 \ --authorization-mode=Node,RBAC \ --runtime-config=api/all=true \ --enable-bootstrap-token-auth \ --service-cluster-ip-range=10.255.0.0/16 \ --token-auth-file=/etc/kubernetes/token.csv \ --service-node-port-range=30000-50000 \ --tls-cert-file=/etc/kubernetes/ssl/kube-apiserver.pem \ --tls-private-key-file=/etc/kubernetes/ssl/kube-apiserver-key.pem \ --client-ca-file=/etc/kubernetes/ssl/ca.pem \ --kubelet-client-certificate=/etc/kubernetes/ssl/kube-apiserver.pem \ --kubelet-client-key=/etc/kubernetes/ssl/kube-apiserver-key.pem \ --service-account-key-file=/etc/kubernetes/ssl/ca-key.pem \ --service-account-signing-key-file=/etc/kubernetes/ssl/ca-key.pem \ --service-account-issuer=https://kubernetes.default.svc.cluster.local \ --etcd-cafile=/etc/etcd/ssl/ca.pem \ --etcd-certfile=/etc/etcd/ssl/etcd.pem \ --etcd-keyfile=/etc/etcd/ssl/etcd-key.pem \ --etcd-servers=https://192.168.1.180:2379,https://192.168.1.181:2379,https://192.168.1.182:2379 \ --enable-swagger-ui=true \ --allow-privileged=true \ --apiserver-count=3 \ --audit-log-maxage=30 \ --audit-log-maxbackup=3 \ --audit-log-maxsize=100 \ --audit-log-path=/var/log/kube-apiserver-audit.log \ --event-ttl=1h \ --alsologtostderr=true \ --logtostderr=false \ --log-dir=/var/log/kubernetes \ --v=4"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [root@master1 ~]# systemctl daemon-reload && systemctl enable --now kube-apiserver.service [root@master2 ~]# systemctl daemon-reload && systemctl enable --now kube-apiserver.service [root@master3 ~]# systemctl daemon-reload && systemctl enable --now kube-apiserver.service [root@master1 work]# curl --insecure https://192.168.1.180:6443/ { "kind": "Status", "apiVersion": "v1", "metadata": { }, "status": "Failure", "message": "Unauthorized", "reason": "Unauthorized", "code": 401 } # 上面看到 401,这个是正常的的状态,还没认证
部署kubectl组件
Kubectl 是客户端工具,操作 k8s 资源的,如增删改查等。
Kubectl 操作资源的时候,怎么知道连接到哪个集群,需要一个文件/etc/kubernetes/admin.conf,kubectl会根据这个文件的配置,去访问 k8s 资源。/etc/kubernetes/admin.con 文件记录了访问的 k8s 集群,和用到的证书。
可以设置一个环境变量 KUBECONFIG
也可以按照下面方法,这个是在 kubeadm 初始化 k8s 的时候会告诉我们要用的一个方法
如果设置了 KUBECONFIG,那就会先找到 KUBECONFIG 去操作 k8s,如果没有 KUBECONFIG 变量,那就会使用/root/.kube/config 文件决定管理哪个 k8s 集群的资源
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [ root@master1 work] # cat admin-csr.json { "CN" : "admin" , "hosts" : [ ] , "key" : { "algo" : "rsa" , "size" : 2048 } , "names" : [ { "C" : "CN" , "ST" : "Hubei" , "L" : "Wuhan" , "O" : "system:masters" , "OU" : "system" } ] }
说明: 后续 kube-apiserver 使用 RBAC 对客户端(如 kubelet、kube-proxy、Pod)请求进行授权;kube-apiserver 预 定 义 了 一 些 RBAC 使 用 的 RoleBindings , 如 cluster-admin 将 Group system:masters 与 Role cluster-admin 绑定,该 Role 授予了调用 kube-apiserver 的所有 API 的权限; O 指定该证书的 Group 为 system:masters,kubelet 使用该证书访问 kube-apiserver 时 ,由于证书被 CA 签名,所以认证通过,同时由于证书用户组为经过预授权的 system:masters,所以被授予访问所有 API 的权限;
注: 这个 admin 证书,是将来生成管理员用的 kube config 配置文件用的,现在我们一般建议使用 RBAC 来对 kubernetes 进行角色权限控制,kubernetes 将证书中的 CN 字段 作为 User,O 字段作为 Group;”O”: “system:masters”, 必须是 system:masters,否则后面 kubectl create clusterrolebinding 报错。
证书 O 配置为 system:masters 在集群内部 cluster-admin 的 clusterrolebinding 将system:masters 组和 cluster-admin clusterrole 绑定在一起
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@master1 work]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes admin-csr.json | cfssljson -bare admin 2023/07/18 09:36:33 [INFO] generate received request 2023/07/18 09:36:33 [INFO] received CSR 2023/07/18 09:36:33 [INFO] generating key: rsa-2048 2023/07/18 09:36:33 [INFO] encoded CSR 2023/07/18 09:36:33 [INFO] signed certificate with serial number 590504316254400223853731101622257961862372429191 2023/07/18 09:36:33 [WARNING] This certificate lacks a "hosts" field. This makes it unsuitable for websites. For more information see the Baseline Requirements for the Issuance and Management of Publicly-Trusted Certificates, v.1.1.6, from the CA/Browser Forum (https://cabforum.org); specifically, section 10.2.3 ("Information Requirements"). [root@master1 work]# cp admin*.pem /etc/kubernetes/ssl/
创建 kubeconfig 配置文件,比较重要
kubeconfig 为 kubectl 的配置文件,包含访问 apiserver 的所有信息,如 apiserver 地址、CA 证书和自身使用的证书(这里如果报错找不到 kubeconfig 路径,请手动复制到相应路径下,没有则忽略)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # 设置集群参数 [root@master1 work]# kubectl config set-cluster kubernetes --certificate-authority=ca.pem --embed-certs=true --server=https://192.168.1.180:6443 --kubeconfig=kube.config # 设置客户端认证参数 [root@master1 work]# kubectl config set-credentials admin --client-certificate=admin.pem --client-key=admin-key.pem --embed-certs=true --kubeconfig=kube.config # 设置上下文 [root@master1 work]# kubectl config set-context kubernetes --cluster=kubernetes --user=admin --kubeconfig=kube.config # 设置当前上下文 [root@master1 work]# kubectl config use-context kubernetes --kubeconfig=kube.config [root@master1 work]# mkdir ~/.kube -p [root@master1 work]# cp kube.config ~/.kube/config # 授权kubernetes证书访问kubelet api权限 [root@master1 work]# kubectl create clusterrolebinding kube-apiserver:kubelet-apis --clusterrole=system:kubelet-api-admin --user kubernetes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [root@master1 work]# kubectl cluster-info Kubernetes control plane is running at https://192.168.1.180:6443 To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'. [root@master1 work]# kubectl get componentstatuses Warning: v1 ComponentStatus is deprecated in v1.19+ NAME STATUS MESSAGE ERROR scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused etcd-2 Healthy {"health":"true"} etcd-1 Healthy {"health":"true"} etcd-0 Healthy {"health":"true"} [root@master1 work]# kubectl get all --all-namespaces NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE default service/kubernetes ClusterIP 10.255.0.1 <none> 443/TCP 12h
1 2 3 4 5 6 [root@master2 ~]# mkdir /root/.kube/ [root@master3 ~]# mkdir /root/.kube/ [root@master1 work]# rsync -vaz /root/.kube/config master2:/root/.kube/ [root@master1 work]# rsync -vaz /root/.kube/config master3:/root/.kube/
1 2 3 4 5 6 7 8 9 10 11 yum install -y bash-completion source /usr/share/bash-completion/bash_completion source <(kubectl completion bash) kubectl completion bash > ~/.kube/completion.bash.inc source '/root/.kube/completion.bash.inc' source $HOME/.bash_profile
部署 kube-controller-manager 组件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [ root@master1 work] # cat kube-controller-manager-csr.json{ "CN" : "system:kube-controller-manager" , "key" : { "algo" : "rsa" , "size" : 2048 } , "hosts" : [ "127.0.0.1" , "192.168.1.180" , "192.168.1.181" , "192.168.1.182" , "192.168.1.199" ] , "names" : [ { "C" : "CN" , "ST" : "Hubei" , "L" : "Wuhan" , "O" : "system:kube-controller-manager" , "OU" : "system" } ] }
注: hosts 列表包含所有 kube-controller-manager 节点 IP; CN 为 system:kube-controller-manager、O 为 system:kube-controller-manager,kubernetes 内置的 ClusterRoleBindings system:kube-controller-manager 赋予 kube-controller-manager 工作所需的权限
1 2 3 4 5 6 7 8 9 10 [root@master1 work]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-controller-manager-csr.json | cfssljson -bare kube-controller-manager 2023/07/18 09:55:46 [INFO] generate received request 2023/07/18 09:55:46 [INFO] received CSR 2023/07/18 09:55:46 [INFO] generating key: rsa-2048 2023/07/18 09:55:47 [INFO] encoded CSR 2023/07/18 09:55:47 [INFO] signed certificate with serial number 28384387730590989137248799757595047228060784622 2023/07/18 09:55:47 [WARNING] This certificate lacks a "hosts" field. This makes it unsuitable for websites. For more information see the Baseline Requirements for the Issuance and Management of Publicly-Trusted Certificates, v.1.1.6, from the CA/Browser Forum (https://cabforum.org); specifically, section 10.2.3 ("Information Requirements").
创建kube-controller-manager的kubeconfig
1 2 3 4 5 6 7 8 9 10 11 # 设置集群参数 [root@master1 work]# kubectl config set-cluster kubernetes --certificate-authority=ca.pem --embed-certs=true --server=https://192.168.1.180:6443 --kubeconfig=kube-controller-manager.kubeconfig # 设置客户端认证参数 [root@master1 work]# kubectl config set-credentials system:kube-controller-manager --client-certificate=kube-controller-manager.pem --client-key=kube-controller-manager-key.pem --embed-certs=true --kubeconfig=kube-controller-manager.kubeconfig # 设置上下文参数 [root@master1 work]# kubectl config set-context system:kube-controller-manager --cluster=kubernetes --user=system:kube-controller-manager --kubeconfig=kube-controller-manager.kubeconfig # 设置当前上下文 [root@master1 work]# kubectl config use-context system:kube-controller-manager --kubeconfig=kube-controller-manager.kubeconfig
创建配置文件kube-controller-manager.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [ root@master1 work] # cat kube-controller-manager.confKUBE_CONTROLLER_MANAGER_OPTS="--port=0 \ --secure-port=10252 \ --bind-address=127.0.0.1 \ --kubeconfig=/etc/kubernetes/kube-controller-manager.kubeconfig \ --service-cluster-ip-range=10.255.0.0/16 \ --cluster-name=kubernetes \ --cluster-signing-cert-file=/etc/kubernetes/ssl/ca.pem \ --cluster-signing-key-file=/etc/kubernetes/ssl/ca-key.pem \ --allocate-node-cidrs=true \ --cluster-cidr=10.0.0.0/16 \ --experimental-cluster-signing-duration=87600h \ --root-ca-file=/etc/kubernetes/ssl/ca.pem \ --service-account-private-key-file=/etc/kubernetes/ssl/ca-key.pem \ --leader-elect=true \ --feature-gates=RotateKubeletServerCertificate=true \ --controllers=*,bootstrapsigner,tokencleaner \ --horizontal-pod-autoscaler-use-rest-clients=true \ --horizontal-pod-autoscaler-sync-period=10s \ --tls-cert-file=/etc/kubernetes/ssl/kube-controller-manager.pem \ --tls-private-key-file=/etc/kubernetes/ssl/kube-controller-manager-key.pem \ --use-service-account-credentials=true \ --alsologtostderr=true \ --logtostderr=false \ --log-dir=/var/log/kubernetes \ --v=2"
1 2 3 4 5 6 7 8 9 10 11 [root@master1 work]# cat kube-controller-manager.service [Unit] Description=Kubernetes Controller Manager Documentation=https://github.com/kubernetes/kubernetes [Service] EnvironmentFile=-/etc/kubernetes/kube-controller-manager.conf ExecStart=/usr/local/bin/kube-controller-manager $KUBE_CONTROLLER_MANAGER_OPTS Restart=on-failure RestartSec=5 [Install] WantedBy=multi-user.target
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 [root@master1 work]# cp kube-controller-manager*.pem /etc/kubernetes/ssl/ [root@master1 work]# cp kube-controller-manager.kubeconfig /etc/kubernetes/ [root@master1 work]# cp kube-controller-manager.conf /etc/kubernetes/ [root@master1 work]# cp kube-controller-manager.service /usr/lib/systemd/system/ [root@master1 work]# rsync -vaz kube-controller-manager*.pem master2:/etc/kubernetes/ssl/ [root@master1 work]# rsync -vaz kube-controller-manager*.pem master3:/etc/kubernetes/ssl/ [root@master1 work]# rsync -vaz kube-controller-manager.kubeconfig kube-controller-manager.conf master2:/etc/kubernetes/ [root@master1 work]# rsync -vaz kube-controller-manager.kubeconfig kube-controller-manager.conf master3:/etc/kubernetes/ [root@master1 work]# rsync -vaz kube-controller-manager.service master2:/usr/lib/systemd/system/ [root@master1 work]# rsync -vaz kube-controller-manager.service master3:/usr/lib/systemd/system/ [root@master1 work]# systemctl daemon-reload && systemctl enable --now kube-controller-manager.service && systemctl status kube-controller-manager.service Active: active (running) since [root@master2 ~]# systemctl daemon-reload && systemctl enable --now kube-controller-manager.service && systemctl status kube-controller-manager.service Active: active (running) since [root@master3 ~]# systemctl daemon-reload && systemctl enable --now kube-controller-manager.service && systemctl status kube-controller-manager.service Active: active (running) since
部署kube-scheduler组件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [ root@master1 work] # cat kube-scheduler-csr.json{ "CN" : "system:kube-scheduler" , "hosts" : [ "127.0.0.1" , "192.168.1.180" , "192.168.1.181" , "192.168.1.182" , "192.168.1.199" ] , "key" : { "algo" : "rsa" , "size" : 2048 } , "names" : [ { "C" : "CN" , "ST" : "Hubei" , "L" : "Wuhan" , "O" : "system:kube-scheduler" , "OU" : "system" } ] }
1 2 3 4 5 6 7 8 9 10 [root@master1 work]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-scheduler-csr.json | cfssljson -bare kube-scheduler 2023/07/18 10:11:29 [INFO] generate received request 2023/07/18 10:11:29 [INFO] received CSR 2023/07/18 10:11:29 [INFO] generating key: rsa-2048 2023/07/18 10:11:30 [INFO] encoded CSR 2023/07/18 10:11:30 [INFO] signed certificate with serial number 555324633751814240953910934040569183966634377630 2023/07/18 10:11:30 [WARNING] This certificate lacks a "hosts" field. This makes it unsuitable for websites. For more information see the Baseline Requirements for the Issuance and Management of Publicly-Trusted Certificates, v.1.1.6, from the CA/Browser Forum (https://cabforum.org); specifically, section 10.2.3 ("Information Requirements").
创建kube-scheduler的kubeconfig
1 2 3 4 5 6 7 8 9 10 11 # 设置集群参数 [root@master1 work]# kubectl config set-cluster kubernetes --certificate-authority=ca.pem --embed-certs=true --server=https://192.168.1.180:6443 --kubeconfig=kube-scheduler.kubeconfig # 设置客户端认证参数 [root@master1 work]# kubectl config set-credentials system:kube-scheduler --client-certificate=kube-scheduler.pem --client-key=kube-scheduler-key.pem --embed-certs=true --kubeconfig=kube-scheduler.kubeconfig # 设置上下文参数 [root@master1 work]# kubectl config set-context system:kube-scheduler --cluster=kubernetes --user=system:kube-scheduler --kubeconfig=kube-scheduler.kubeconfig # 设置当前上下文 [root@master1 work]# kubectl config use-context system:kube-scheduler --kubeconfig=kube-scheduler.kubeconfig
创建配置文件kube-scheduler.conf
1 2 3 4 5 6 7 8 [root@master1 work]# cat kube-scheduler.conf KUBE_SCHEDULER_OPTS="--address=127.0.0.1 \ --kubeconfig=/etc/kubernetes/kube-scheduler.kubeconfig \ --leader-elect=true \ --alsologtostderr=true \ --logtostderr=false \ --log-dir=/var/log/kubernetes \ --v=2"
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@master1 work]# cat kube-scheduler.service [Unit] Description=Kubernetes Scheduler Documentation=https://github.com/kubernetes/kubernetes [Service] EnvironmentFile=-/etc/kubernetes/kube-scheduler.conf ExecStart=/usr/local/bin/kube-scheduler $KUBE_SCHEDULER_OPTS Restart=on-failure RestartSec=5 [Install] WantedBy=multi-user.target
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@master1 work]# cp kube-scheduler*.pem /etc/kubernetes/ssl/ [root@master1 work]# cp kube-scheduler.kubeconfig /etc/kubernetes/ [root@master1 work]# cp kube-scheduler.conf /etc/kubernetes/ [root@master1 work]# cp kube-scheduler.service /usr/lib/systemd/system/ [root@master1 work]# rsync -vaz kube-scheduler*.pem master2:/etc/kubernetes/ssl/ [root@master1 work]# rsync -vaz kube-scheduler*.pem master3:/etc/kubernetes/ssl/ [root@master1 work]# rsync -vaz kube-scheduler.kubeconfig kube-scheduler.conf master2:/etc/kubernetes/ [root@master1 work]# rsync -vaz kube-scheduler.kubeconfig kube-scheduler.conf master3:/etc/kubernetes/ [root@master1 work]# rsync -vaz kube-scheduler.service master2:/usr/lib/systemd/system/ [root@master1 work]# rsync -vaz kube-scheduler.service master3:/usr/lib/systemd/system/ [root@master1 work]# systemctl daemon-reload && systemctl enable --now kube-scheduler.service && systemctl status kube-scheduler.service [root@master2 ~]# systemctl daemon-reload && systemctl enable --now kube-scheduler.service && systemctl status kube-scheduler.service [root@master3 ~]# systemctl daemon-reload && systemctl enable --now kube-scheduler.service && systemctl status kube-scheduler.service
导入离线镜像压缩包
把 pause-cordns.tar.gz 上传到 node1 节点,手动解压
1 [root@node1 ~]# docker load -i pause-cordns.tar.gz
部署kubelet组件
kubelet: 每个 Node 节点上的 kubelet 定期就会调用 API Server 的 REST 接口报告自身状态,API Server接收这些信息后,将节点状态信息更新到 etcd 中。kubelet 也通过 API Server 监听 Pod 信息,从而对 Node机器上的 POD 进行管理,如创建、删除、更新 Pod
创建 kubelet-bootstrap.kubeconfig
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@master1 work]# BOOTSTRAP_TOKEN=$(awk -F "," '{print $1}' /etc/kubernetes/token.csv) [root@master1 work]# echo $BOOTSTRAP_TOKEN c13d0ed83fbeb79f18ef50a60f3646e9 [root@master1 work]# rm -r kubelet-bootstrap.kubeconfig [root@master1 work]# kubectl config set-cluster kubernetes --certificate-authority=ca.pem --embed-certs=true --server=https://192.168.1.180:6443 --kubeconfig=kubelet-bootstrap.kubeconfig [root@master1 work]# kubectl config set-credentials kubelet-bootstrap --token=${BOOTSTRAP_TOKEN} --kubeconfig=kubelet-bootstrap.kubeconfig [root@master1 work]# kubectl config set-context default --cluster=kubernetes --user=kubelet-bootstrap --kubeconfig=kubelet-bootstrap.kubeconfig [root@master1 work]# kubectl config use-context default --kubeconfig=kubelet-bootstrap.kubeconfig [root@master1 work]# kubectl create clusterrolebinding kubelet-bootstrap --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap
“cgroupDriver”: “systemd”要和 docker 的驱动一致
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 [ root@master1 work] # cat kubelet.json{ "kind" : "KubeletConfiguration" , "apiVersion" : "kubelet.config.k8s.io/v1beta1" , "authentication" : { "x509" : { "clientCAFile" : "/etc/kubernetes/ssl/ca.pem" } , "webhook" : { "enabled" : true , "cacheTTL" : "2m0s" } , "anonymous" : { "enabled" : false } } , "authorization" : { "mode" : "Webhook" , "webhook" : { "cacheAuthorizedTTL" : "5m0s" , "cacheUnauthorizedTTL" : "30s" } } , "address" : "192.168.1.183" , "port" : 10250 , "readOnlyPort" : 10255 , "cgroupDriver" : "systemd" , "hairpinMode" : "promiscuous-bridge" , "serializeImagePulls" : false , "featureGates" : { "RotateKubeletClientCertificate" : true , "RotateKubeletServerCertificate" : true } , "clusterDomain" : "cluster.local." , "clusterDNS" : [ "10.255.0.2" ] } # 注:kubelete.json 配置文件 address 改为各个节点的 ip 地址,在各个 work 节点上启动服务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 [root@master1 work]# cat kubelet.service [Unit] Description=Kubernetes Kubelet Documentation=https://github.com/kubernetes/kubernetes After=docker.service Requires=docker.service [Service] WorkingDirectory=/var/lib/kubelet ExecStart=/usr/local/bin/kubelet \ --bootstrap-kubeconfig=/etc/kubernetes/kubelet-bootstrap.kubeconfig \ --cert-dir=/etc/kubernetes/ssl \ --kubeconfig=/etc/kubernetes/kubelet.kubeconfig \ --config=/etc/kubernetes/kubelet.json \ --network-plugin=cni \ --pod-infra-container-image=k8s.gcr.io/pause:3.2 \ --alsologtostderr=true \ --logtostderr=false \ --log-dir=/var/log/kubernetes \ --v=2 Restart=on-failure RestartSec=5 [Install] WantedBy=multi-user.target # 注: -hostname-override:显示名称,集群中唯一 -network-plugin:启用 CNI -kubeconfig:空路径,会自动生成,后面用于连接 apiserver -bootstrap-kubeconfig:首次启动向 apiserver 申请证书 -config:配置参数文件 -cert-dir:kubelet 证书生成目录 -pod-infra-container-image:管理 Pod 网络容器的镜像
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 [root@node1 ~]# mkdir /etc/kubernetes/ssl -p [root@master1 work]# scp kubelet-bootstrap.kubeconfig kubelet.json node1:/etc/kubernetes/ [root@master1 work]# scp ca.pem node1:/etc/kubernetes/ssl/ [root@master1 work]# scp kubelet.service node1:/usr/lib/systemd/system/ [root@node1 ~]# mkdir /var/lib/kubelet [root@node1 ~]# mkdir /var/log/kubernetes [root@node1 ~]# systemctl daemon-reload && systemctl enable --now kubelet.service && systemctl status kubelet.service # 确认 kubelet 服务启动成功后,接着到 master1 节点上 Approve 一下 bootstrap 请求。 # 执行如下命令可以看到一个 worker 节点发送了一个 CSR 请求 [root@master1 work]# kubectl get csr NAME AGE SIGNERNAME REQUESTOR CONDITION node-csr-QRwNdc_yv-IPt19eqKmAcyrLnDv86x31pubdK3vLTGI 46s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending [root@master1 work]# kubectl certificate approve node-csr-QRwNdc_yv-IPt19eqKmAcyrLnDv86x31pubdK3vLTGI certificatesigningrequest.certificates.k8s.io/node-csr-QRwNdc_yv-IPt19eqKmAcyrLnDv86x31pubdK3vLTGI approved [root@master1 work]# kubectl get csr NAME AGE SIGNERNAME REQUESTOR CONDITION node-csr-QRwNdc_yv-IPt19eqKmAcyrLnDv86x31pubdK3vLTGI 87s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Approved,Issued [root@master1 work]# kubectl get nodes NAME STATUS ROLES AGE VERSION node1 NotReady <none> 37s v1.20.7 # 注意:STATUS 是 NotReady 表示还没有安装网络插件
部署kube-proxy组件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [ root@master1 work] # cat kube-proxy-csr.json { "CN" : "system:kube-proxy" , "key" : { "algo" : "rsa" , "size" : 2048 } , "names" : [ { "C" : "CN" , "ST" : "Hubei" , "L" : "Wuhan" , "O" : "k8s" , "OU" : "system" } ] }
1 2 3 4 5 6 7 8 9 10 [root@master1 work]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy 2023/07/20 10:29:10 [INFO] generate received request 2023/07/20 10:29:10 [INFO] received CSR 2023/07/20 10:29:10 [INFO] generating key: rsa-2048 2023/07/20 10:29:10 [INFO] encoded CSR 2023/07/20 10:29:10 [INFO] signed certificate with serial number 441768971858777701284603976425459769356591871306 2023/07/20 10:29:10 [WARNING] This certificate lacks a "hosts" field. This makes it unsuitable for websites. For more information see the Baseline Requirements for the Issuance and Management of Publicly-Trusted Certificates, v.1.1.6, from the CA/Browser Forum (https://cabforum.org); specifically, section 10.2.3 ("Information Requirements").
1 2 3 4 5 6 7 [root@master1 work]# kubectl config set-cluster kubernetes --certificate-authority=ca.pem --embed-certs=true --server=https://192.168.1.180:6443 --kubeconfig=kube-proxy.kubeconfig [root@master1 work]# kubectl config set-credentials kube-proxy --client-certificate=kube-proxy.pem --client-key=kube-proxy-key.pem --embed-certs=true --kubeconfig=kube-proxy.kubeconfig [root@master1 work]# kubectl config set-context default --cluster=kubernetes --user=kube-proxy --kubeconfig=kube-proxy.kubeconfig [root@master1 work]# kubectl config use-context default --kubeconfig=kube-proxy.kubeconfig
1 2 3 4 5 6 7 8 9 10 [root@master1 work]# cat kube-proxy.yaml apiVersion: kubeproxy.config.k8s.io/v1alpha1 bindAddress: 192.168.1.183 clientConnection: kubeconfig: /etc/kubernetes/kube-proxy.kubeconfig clusterCIDR: 192.168.1.0/24 healthzBindAddress: 192.168.1.183:10256 kind: KubeProxyConfiguration metricsBindAddress: 192.168.1.183:10249 mode: "ipvs"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [root@master1 work]# cat kube-proxy.service [Unit] Description=Kubernetes Kube-Proxy Server Documentation=https://github.com/kubernetes/kubernetes After=network.target [Service] WorkingDirectory=/var/lib/kube-proxy ExecStart=/usr/local/bin/kube-proxy \ --config=/etc/kubernetes/kube-proxy.yaml \ --alsologtostderr=true \ --logtostderr=false \ --log-dir=/var/log/kubernetes \ --v=2 Restart=on-failure RestartSec=5 LimitNOFILE=65536 [Install] WantedBy=multi-user.target
1 2 3 4 5 6 7 [root@master1 work]# scp kube-proxy.kubeconfig kube-proxy.yaml node1:/etc/kubernetes/ [root@master1 work]# scp kube-proxy.service node1:/usr/lib/systemd/system/ [root@node1 ~]# mkdir -p /var/lib/kube-proxy [root@node1 ~]# systemctl daemon-reload && systemctl enable --now kube-proxy && systemctl status kube-proxy
部署calico组件
把 calico.tar.gz 上传到 node1 节点
把 caliso.yaml 上传到 master1 节点
1 2 3 4 5 6 7 8 9 10 11 12 [root@node1 ~]# docker load -i calico.tar.gz [root@master1 work]# kubectl apply -f calico.yaml [root@master1 work]# kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE calico-kube-controllers-6949477b58-s5mxf 1/1 Running 0 32s calico-node-hcghf 1/1 Running 0 31s [root@master1 work]# kubectl get nodes NAME STATUS ROLES AGE VERSION node1 Ready <none> 43m v1.20.7
部署coredns组件
把 coredns.yaml 上次到 master1 节点
1 2 3 4 5 6 7 8 9 10 11 [root@master1 work]# kubectl apply -f coredns.yaml [root@master1 work]# kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE calico-kube-controllers-6949477b58-s5mxf 1/1 Running 0 2m41s calico-node-hcghf 1/1 Running 0 2m40s coredns-7bf4bd64bd-jxxfk 1/1 Running 0 24s [root@master1 work]# kubectl get svc -n kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kube-dns ClusterIP 10.255.0.2 <none> 53/UDP,53/TCP,9153/TCP 40s
查看集群状态
1 2 3 [root@master1 work]# kubectl get nodes NAME STATUS ROLES AGE VERSION node1 Ready <none> 46m v1.20.7
测试k8s集群部署tomcat
把 tomcat.tar.gz 和 busybox-1-28.tar.gz 上传到 node1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 [root@node1 ~]# docker load -i busybox-1-28.tar.gz [root@node1 ~]# docker load -i tomcat.tar.gz [root@master1 ~]# cat tomcat.yaml apiVersion: v1 #pod属于k8s核心组v1 kind: Pod #创建的是一个Pod资源 metadata: #元数据 name: demo-pod #pod名字 namespace: default #pod所属的名称空间 labels: app: myapp #pod具有的标签 env: dev #pod具有的标签 spec: containers: #定义一个容器,容器是对象列表,下面可以有多个name - name: tomcat-pod-java #容器的名字 ports: - containerPort: 8080 image: tomcat:8.5-jre8-alpine #容器使用的镜像 imagePullPolicy: IfNotPresent - name: busybox image: busybox:latest command: #command是一个列表,定义的时候下面的参数加横线 - "/bin/sh" - "-c" - "sleep 3600" [root@master1 ~]# cat tomcat-service.yaml apiVersion: v1 kind: Service metadata: name: tomcat spec: type: NodePort ports: - port: 8080 nodePort: 30080 selector: app: myapp env: dev [root@master1 work]# kubectl apply -f tomcat.yaml [root@master1 work]# kubectl apply -f tomcat-service.yaml [root@master1 work]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.255.0.1 <none> 443/TCP 82m tomcat NodePort 10.255.27.116 <none> 8080:30080/TCP 18s # 浏览器访问 node1:30080
验证cordns 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [root@master1 ~]# kubectl run busybox --image busybox:1.28 --restart=Never --rm -it busybox -- sh / # ping www.baidu.com PING www.baidu.com (110.242.68.3): 56 data bytes 64 bytes from 110.242.68.3: seq=0 ttl=127 time=21.006 ms 64 bytes from 110.242.68.3: seq=1 ttl=127 time=20.862 ms 64 bytes from 110.242.68.3: seq=2 ttl=127 time=20.976 ms 64 bytes from 110.242.68.3: seq=3 ttl=127 time=20.865 ms / # nslookup kubernetes.default.svc.cluster.local Server: 10.255.0.2 Address 1: 10.255.0.2 kube-dns.kube-system.svc.cluster.local Name: kubernetes.default.svc.cluster.local Address 1: 10.255.0.1 kubernetes.default.svc.cluster.local / # nslookup tomcat.default.svc.cluster.local Server: 10.255.0.2 Address 1: 10.255.0.2 kube-dns.kube-system.svc.cluster.local Name: tomcat.default.svc.cluster.local Address 1: 10.255.27.116 tomcat.default.svc.cluster.local
安装keepalived+nginx实现k8s高可用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 [root@master1 ~]# yum install nginx keepalived nginx-mod-stream -y [root@master2 ~]# yum install nginx keepalived nginx-mod-stream -y [root@master1 ~]# cat /etc/nginx/nginx.conf user nginx; worker_processes auto; error_log /var/log/nginx/error.log; pid /run/nginx.pid; include /usr/share/nginx/modules/*.conf; events { worker_connections 1024; } # 四层负载均衡,为两台Master apiserver组件提供负载均衡 stream { log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent'; access_log /var/log/nginx/k8s-access.log main; upstream k8s-apiserver { server 192.168.1.180:6443; # Master1 APISERVER IP:PORT server 192.168.1.181:6443; # Master2 APISERVER IP:PORT server 192.168.1.182:6443; # Master3 APISERVER IP:PORT } server { listen 16443; # 由于nginx与master节点复用,这个监听端口不能是6443,否则会冲突 proxy_pass k8s-apiserver; } } http { log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; tcp_nopush on; tcp_nodelay on; keepalive_timeout 65; types_hash_max_size 2048; include /etc/nginx/mime.types; default_type application/octet-stream; server { listen 80 default_server; server_name _; location / { } } } [root@master1 ~]# scp /etc/nginx/nginx.conf master2:/etc/nginx/nginx.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 # 主 master1 [root@master1 ~]# cat /etc/keepalived/keepalived.conf global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id NGINX_MASTER } vrrp_script check_nginx { script "/etc/keepalived/check_nginx.sh" } vrrp_instance VI_1 { state MASTER interface ens32 # 修改为实际网卡名 virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的 priority 100 # 优先级,备服务器设置 90 advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒 authentication { auth_type PASS auth_pass 1111 } # 虚拟IP virtual_ipaddress { 192.168.1.199/24 } track_script { check_nginx } } [root@master1 ~]# cat /etc/keepalived/check_nginx.sh # !/bin/bash # 1、判断Nginx是否存活 counter=`ps -C nginx --no-header | wc -l` if [ $counter -eq 0 ]; then #2、如果不存活则尝试启动Nginx service nginx start sleep 2 #3、等待2秒后再次获取一次Nginx状态 counter=`ps -C nginx --no-header | wc -l` #4、再次进行判断,如Nginx还不存活则停止Keepalived,让地址进行漂移 if [ $counter -eq 0 ]; then service keepalived stop fi fi [root@master1 ~]# chmod +x /etc/keepalived/check_nginx.sh # 备 master2 [root@master2 ~]# cat /etc/keepalived/keepalived.conf global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id NGINX_MASTER } vrrp_script check_nginx { script "/etc/keepalived/check_nginx.sh" } vrrp_instance VI_1 { state BACKUP interface ens32 # 修改为实际网卡名 virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的 priority 90 # 优先级,备服务器设置 90 advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒 authentication { auth_type PASS auth_pass 1111 } # 虚拟IP virtual_ipaddress { 192.168.1.199/24 } track_script { check_nginx } } [root@master2 ~]# cat /etc/keepalived/check_nginx.sh # !/bin/bash # 1、判断Nginx是否存活 counter=`ps -C nginx --no-header | wc -l` if [ $counter -eq 0 ]; then #2、如果不存活则尝试启动Nginx service nginx start sleep 2 #3、等待2秒后再次获取一次Nginx状态 counter=`ps -C nginx --no-header | wc -l` #4、再次进行判断,如Nginx还不存活则停止Keepalived,让地址进行漂移 if [ $counter -eq 0 ]; then service keepalived stop fi fi [root@master2 ~]# chmod +x /etc/keepalived/check_nginx.sh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@master1 ~]# systemctl daemon-reload && systemctl enable --now nginx.service && systemctl enable --now keepalived.service [root@master2 ~]# systemctl daemon-reload && systemctl enable --now nginx.service && systemctl enable --now keepalived.service [root@master1 ~]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:42:09:5b brd ff:ff:ff:ff:ff:ff inet 192.168.1.180/24 brd 192.168.1.255 scope global noprefixroute ens32 valid_lft forever preferred_lft forever inet 192.168.1.199/24 scope global secondary ens32 valid_lft forever preferred_lft forever inet6 fe80::f505:3807:9755:3839/64 scope link noprefixroute valid_lft forever preferred_lft forever 3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default link/ether 02:42:a8:d0:04:85 brd ff:ff:ff:ff:ff:ff inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0 valid_lft forever preferred_lft forever
目前所有的 Worker Node 组件连接都还是 master1 Node,如果不改为连接 VIP 走负载均衡器,那么 Master 还是单点故障。
因此接下来就是要改所有 Worker Node(kubectl get node 命令查看到的节点)组件配置文件,由原来 192.168.1.180 修改为 192.168.1.199(VIP)。
在所有 Worker Node 执行
1 2 3 4 5 6 7 8 9 10 11 sed -i 's#192.168.1.180:6443#192.168.1.199:16443#' /etc/kubernetes/kubelet-bootstrap.kubeconfig sed -i 's#192.168.1.180:6443#192.168.1.199:16443#' /etc/kubernetes/kubelet.json sed -i 's#192.168.1.180:6443#192.168.1.199:16443#' /etc/kubernetes/kubelet.kubeconfig sed -i 's#192.168.1.180:6443#192.168.1.199:16443#' /etc/kubernetes/kube-proxy.yaml sed -i 's#192.168.1.180:6443#192.168.1.199:16443#' /etc/kubernetes/kube-proxy.kubeconfig systemctl restart kubelet kube-proxy
这样高可用集群就安装好了
基于containerd安装k8s1.26集群 k8s环境规划
centos7.9操作系统,4G/4CPU/100G,网络NAT,开启虚拟化
podSubnet(pod网段)10.244.0.0/16
k8s集群角色
ip
主机名
安装的组件
控制节点
192.168.1.180
master1
apiserver、controller-manager、scheduler、kubelet、etcd、kube-proxy、容器运行时、calico
工作节点
192.168.1.181
node1
kube-prox、calico、coredns、容器运行时、kubelet
工作节点
192.168.1.182
node2
kube-prox、calico、coredns、容器运行时、kubelet
初始化
所有主机做以下操作
1 2 3 echo "192.168.1.180 master1 192.168.1.181 node1 192.168.1.182 node2" >> /etc/hosts
1 2 3 ssh-keygen for i in master1 node1 node2;do ssh-copy-id root@$i;done
1 systemctl disable --now firewalld
1 2 3 4 5 6 7 sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config # 重启生效 reboot # 显示 Disabled 说明 selinux 已经关闭 getenforce
1 2 3 4 5 6 7 8 # 临时关闭 swapoff -a # 永久关闭:注释 swap 挂载,给 swap 这行开头加一下注释 vim /etc/fstab # /dev/mapper/centos-swap swap swap defaults 0 0 # 如果是克隆的虚拟机,需要删除 UUID
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # 加载 br_netfilter 模块 modprobe br_netfilter # 验证模块是否加载成功: lsmod |grep br_netfilter # 修改内核参数 cat > /etc/sysctl.d/k8s.conf <<EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 EOF # 使刚才修改的内核参数生效 sysctl -p /etc/sysctl.d/k8s.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 # 备份基础repo源 mkdir /root/repo.bak cd /etc/yum.repos.d/ mv * /root/repo.bak/ # 拉取阿里云repo源 curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo # 配置国内阿里云 docker 和 containerd 的 repo 源 yum install yum-utils -y yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo # 配置安装 k8s 组件需要的阿里云的 repo 源 cat > /etc/yum.repos.d/kubernetes.repo <<EOF [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=0 EOF
1 2 3 4 5 6 7 8 9 10 11 12 # 安装 ntpdate 命令, yum install ntpdate -y # 跟网络源做同步 ntpdate cn.pool.ntp.org # 把时间同步做成计划任务 crontab -e * */1 * * * /usr/sbin/ntpdate cn.pool.ntp.org # 重启 crond 服务 service crond restart
1 2 3 4 5 6 7 8 # 安装 iptables yum install iptables-services -y # 禁用 iptables service iptables stop && systemctl disable iptables # 清空防火墙规则 iptables -F
不开启 ipvs 将会使用 iptables 进行数据包转发,但是效率低,所以官网推荐需要开通 ipvs。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 编写脚本开启模块 vim /etc/sysconfig/modules/ipvs.modules # !/bin/bash ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack" for kernel_module in ${ipvs_modules}; do /sbin/modinfo -F filename ${kernel_module} > /dev/null 2>&1 if [ 0 -eq 0 ]; then /sbin/modprobe ${kernel_module} fi done # 执行脚本,查看模块是否开启 chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs ip_vs_ftp 13079 0 nf_nat 26583 1 ip_vs_ftp ip_vs_sed 12519 0 ip_vs_nq 12516 0 ip_vs_sh 12688 0 ip_vs_dh 12688 0
1 yum install -y yum-utils device-mapper-persistent-data lvm2 wget net-tools nfs-utils lrzsz gcc gcc-c++ make cmake libxml2-devel openssl-devel curl curl-devel unzip sudo ntp libaio-devel wget vim ncurses-devel autoconf automake zlib-devel python-devel epel-release openssh-server socat ipvsadm conntrack ntpdate telnet rsync bash-completion
安装containerd服务
所有节点做相同操作
1 yum install containerd.io-1.6.6 -y
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 mkdir -p /etc/containerd containerd config default > /etc/containerd/config.toml # 修改配置文件 vim /etc/containerd/config.toml SystemdCgroup = true # false改为true sandbox_image="registry.aliyuncs.com/google_containers/pause:3.7" # k8s.gcr.io/pause:3.6修改为registry.aliyuncs.com/google_containers/pause:3.7 # 配置 containerd 开机启动,并启动 containerd systemctl enable containerd --now # 修改/etc/cictl.yaml文件 cat > /etc/crictl.yaml <<EOF runtime-endpoint: unix:///run/containerd/containerd.sock image-endpoint: unix:///run/containerd/containerd.sock timeout: 10 debug: false EOF systemctl restart containerd
1 2 3 4 5 6 7 8 9 10 11 vim /etc/containerd/config.toml config_path = "/etc/containerd/certs.d" mkdir /etc/containerd/certs.d/docker.io/ -p vim /etc/containerd/certs.d/docker.io/hosts.toml [host."https://vh3bm52y.mirror.aliyuncs.com",host."https://registry.docker-cn.com"] capabilities = ["pull"] # 重启 containerd: systemctl restart containerd
安装docker-ce
docker 也要安装,docker 跟 containerd 不冲突,安装 docker 是为了能基于 dockerfile 构建镜像
1 2 3 yum install docker-ce -y systemctl start docker && systemctl enable docker.service && systemctl status docker
1 2 3 4 5 6 7 8 9 tee /etc/docker/daemon.json << 'EOF' { "registry-mirrors":["https://rsbud4vc.mirror.aliyuncs.com","https://registry.docker-cn.com","https://docker.mirrors.ustc.edu.cn","https://dockerhub.azk8s.cn","http://hub-mirror.c.163.com","http://qtid6917.mirror.aliyuncs.com","https://rncxm540.mirror.aliyuncs.com"] } EOF systemctl daemon-reload systemctl restart docker systemctl status docker
安装初始化k8s需要的软件包
kubeadm:kubeadm是一个工具,用来初始化k8s集群的
1 2 3 yum install -y kubelet-1.26.0 kubeadm-1.26.0 kubectl-1.26.0 systemctl enable kubelet
kubeadm初始化k8s集群
1 2 3 4 5 [root@master1 ~]# crictl config runtime-endpoint unix:///run/containerd/containerd.sock [root@node1 ~]# crictl config runtime-endpoint unix:///run/containerd/containerd.sock [root@node2 ~]# crictl config runtime-endpoint unix:///run/containerd/containerd.sock
1 [root@master1 ~]# kubeadm config print init-defaults > kubeadm.yaml
根据我们自己的需求修改配置,比如修改 imageRepository 的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 apiVersion: kubeadm.k8s.io/v1beta3 bootstrapTokens: - groups: - system:bootstrappers:kubeadm:default-node-token token: abcdef.0123456789abcdef ttl: 24h0m0s usages: - signing - authentication kind: InitConfiguration localAPIEndpoint: advertiseAddress: 192.168 .1 .180 bindPort: 6443 nodeRegistration: criSocket: unix:///run/containerd/containerd.sock imagePullPolicy: IfNotPresent name: master1 taints: null --- apiServer: timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta3 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controllerManager: {}dns: {}etcd: local: dataDir: /var/lib/etcd imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers kind: ClusterConfiguration kubernetesVersion: 1.26 .0 networking: dnsDomain: cluster.local podSubnet: 10.244 .0 .0 /16 serviceSubnet: 10.96 .0 .0 /12 scheduler: {}--- apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration mode: ipvs --- apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration cgroupDriver: systemd
没有本地镜像,会默认从阿里云拉取镜像
1 2 3 4 5 6 7 # ctr是containerd自带的工具,有命名空间的概念,若是k8s相关的镜像,都默认在k8s.io这个命名空间,所以导入镜像时需要指定命令空间为k8s.io [root@master1 ~]# ctr -n=k8s.io images import k8s_1.26.0.tar.gz [root@node1 ~]# ctr -n=k8s.io images import k8s_1.26.0.tar.gz [root@node2 ~]# ctr -n=k8s.io images import k8s_1.26.0.tar.gz
1 2 3 4 5 6 7 8 9 10 11 12 [root@master1 ~]# kubeadm init --config=kubeadm.yaml --ignore-preflight-errors=SystemVerification [root@master1 ~]# mkdir -p $HOME/.kube [root@master1 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config [root@master1 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config [root@master1 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master1 NotReady control-plane 4m48s v1.26.0
扩容k8s集群
1 2 [root@master1 ~]# kubeadm token create --print-join-command kubeadm join 192.168.1.180:6443 --token cc5gcg.xt918axsgznlogjb --discovery-token-ca-cert-hash sha256:7e24f2544d8ac7ab11df4b0ebab8323853ed43f59210e4d0d8b09dce8ef79fcb
1 2 3 [root@node1 ~]# kubeadm join 192.168.1.180:6443 --token cc5gcg.xt918axsgznlogjb --discovery-token-ca-cert-hash sha256:7e24f2544d8ac7ab11df4b0ebab8323853ed43f59210e4d0d8b09dce8ef79fcb --ignore-preflight-errors=SystemVerification [root@node2 ~]# kubeadm join 192.168.1.180:6443 --token cc5gcg.xt918axsgznlogjb --discovery-token-ca-cert-hash sha256:7e24f2544d8ac7ab11df4b0ebab8323853ed43f59210e4d0d8b09dce8ef79fcb --ignore-preflight-errors=SystemVerification
1 2 3 4 5 6 7 8 9 [root@master1 ~]# kubectl label nodes node1 node-role.kubernetes.io/work=work [root@master1 ~]# kubectl label nodes node2 node-role.kubernetes.io/work=work [root@master1 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master1 NotReady control-plane 15m v1.26.0 node1 NotReady work 96s v1.26.0 node2 NotReady work 86s v1.26.0
安装网络组件calico
把calico镜像上传到所有节点解压
1 2 3 4 5 [root@master1 ~]# ctr -n=k8s.io images import calico.tar.gz [root@node1 ~]# ctr -n=k8s.io images import calico.tar.gz [root@node2 ~]# ctr -n=k8s.io images import calico.tar.gz
上传配置文件
1 2 3 4 5 6 7 [root@master1 ~]# kubectl apply -f calico.yaml [root@master1 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master1 Ready control-plane 26m v1.26.0 node1 Ready work 13m v1.26.0 node2 Ready work 13m v1.26.0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 containers: - name: calico-node image: docker.io/calico/node:v3.18.0 …… env: - name: DATASTORE_TYPE value: "kubernetes" - name: CLUSTER_TYPE value: "k8s,bgp" - name: IP value: "autodetect" - name: CALICO_IPV4POOL_CIDR value: "10.244.0.0/16" - name: CALICO_IPV4POOL_IPIP value: "Always" - name: IP_AUTODETECTION_METHOD value: "interface=ens33"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@master1 ~]# kubectl run busybox --image docker.io/library/busybox:1.28 --image-pull-policy=IfNotPresent --restart=Never --rm -it busybox -- sh / # ping baidu.com PING baidu.com (39.156.66.10): 56 data bytes 64 bytes from 39.156.66.10: seq=0 ttl=127 time=21.761 ms 64 bytes from 39.156.66.10: seq=1 ttl=127 time=21.570 ms / # nslookup kubernetes.default.svc.cluster.local Server: 10.96.0.10 Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local Name: kubernetes.default.svc.cluster.local Address 1: 10.96.0.1 kubernetes.default.svc.cluster.local
ctr和crictl区别
ctr是containerd自带的CLI命令行工具,crictl是k8s中CRI(容器运行时接口)的客户端,k8s使用该客户端和containerd进行交互;
1 2 3 4 5 6 7 [root@master1 ~]# cat /etc/crictl.yaml runtime-endpoint: unix:///run/containerd/containerd.sock image-endpoint: unix:///run/containerd/containerd.sock timeout: 10 debug: false pull-image-on-create: false disable-pull-on-run: false
ctr和crictl命令具体区别如下,也可以–help查看。crictl缺少对具体镜像的管理能力,可能是k8s层面镜像管理可以由用户自行控制,能配置pod里面容器的统一镜像仓库,镜像的管理可以有harbor等插件进行处理
命令
ctr
crictl
查看运行的容器
ctr task ls/ctr container ls
crictl ps
查看镜像
ctr image ls
crictl images
查看容器日志
无
crictl logs
查看容器数据信息
ctr container info
crictl inspect
查看容器资源
无
crictl stats
启动/关闭已有容器
ctr task start/kill
crictl start/stop
运行一个新的容器
crt run
无(最小单元为pod)
修改镜像标签
ctr image tag
无
创建一个新的容器
ctr container create
crictl create
导入镜像
ctr image import
无
导出镜像
ctr image export
无
删除容器
ctr container rm
crictl rm
删除镜像
ctr image rm
crictl rmi
拉取镜像
ctr image pull
crictl pull
推送镜像
ctr image push
无
kubeadm安装单master多node测试环境k8s集群 k8s环境规划
centos7.6~centos7.9操作系统,4G/4CPU/100G,网络NAT,开启虚拟化
podSubnet(pod网段)10.244.0.0/16
k8s集群角色
ip
主机名
安装的组件
控制节点
192.168.1.180
master1
apiserver、controller-manager、scheduler、etcd、docker、kube-proxy、calico
工作节点
192.168.1.181
node1
kubelet、kube-proxy、docker、calico、coredns
工作节点
192.168.1.182
node2
kubelet、kube-proxy、docker、calico、coredns
初始化实验环境
所有节点做相同操作
1 2 3 4 5 6 7 8 9 10 11 12 vim /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE=Ethernet BOOTPROTO=static # static 表示静态 ip 地址 IPADDR=192.168.1.180 # ip 地址,需要跟自己电脑所在网段一致 NETMASK=255.255.255.0 # 子网掩码,需要跟自己电脑所在网段一致 GATEWAY=192.168.1.2 # 网关,在自己电脑打开 cmd,输入 ipconfig /all 可看到 DNS1=223.5.5.5 # DNS,在自己电脑打开 cmd,输入 ipconfig /all 可看到 NAME=ens33 # 网卡名字,跟 DEVICE 名字保持一致即可 DEVICE=ens33 # 网卡设备名,ip addr 可看到自己的这个网卡设备名 ONBOOT=yes # 开机自启动网络,必须是 yes service network restart
1 2 3 4 5 6 7 8 9 10 11 12 13 # 在 192.168.1.180 上执行 hostnamectl set-hostname master1 && bash # 在 192.168.40.181 上执行 hostnamectl set-hostname node1 && bash # 在 192.168.40.182 上执行 hostnamectl set-hostname node2 && bash # 配置主机 hosts 文件 192.168.1.180 master1 192.168.1.181 node1 192.168.1.182 node2
1 2 3 4 5 6 ssh-keygen for i in master1 node1 node2 do ssh-copy-id root@$i done
1 2 3 4 5 6 7 8 # 临时关闭 swapoff -a # 永久关闭:注释 swap 挂载,给 swap 这行开头加一下注释 vim /etc/fstab # /dev/mapper/centos-swap swap swap defaults 0 0 # 如果是克隆的虚拟机,需要删除 UUID
1 2 3 4 5 6 7 8 9 10 modprobe br_netfilter echo "modprobe br_netfilter" >> /etc/profile cat > /etc/sysctl.d/k8s.conf <<EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 EOF sysctl -p /etc/sysctl.d/k8s.conf
1 2 3 systemctl stop firewalld systemctl disable firewalld systemctl status firewalld
1 2 3 4 5 6 7 8 9 # 修改 selinux 配置文件之后,重启机器,selinux 配置才能永久生效 sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config # 重启 reboot # 显示 Disabled 说明 selinux 已经关闭 getenforce Disabled
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 # 备份基础repo源 mkdir /root/repo.bak cd /etc/yum.repos.d/ mv * /root/repo.bak/ # 拉取阿里云repo源 curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo # 配置国内阿里云 docker 的 repo 源 yum install yum-utils -y yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo # 配置安装 k8s 组件需要的阿里云的 repo 源 cat > /etc/yum.repos.d/kubernetes.repo << EOF [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=0 EOF
1 2 3 4 5 6 7 8 9 10 11 12 # 安装 ntpdate 命令 yum install ntpdate -y # 跟网络时间做同步 ntpdate cn.pool.ntp.org # 把时间同步做成计划任务 crontab -e * */1 * * * /usr/sbin/ntpdate cn.pool.ntp.org # 重启 crond 服务 service crond restart
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 编写脚本开启模块 vim /etc/sysconfig/modules/ipvs.modules # !/bin/bash ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack" for kernel_module in ${ipvs_modules}; do /sbin/modinfo -F filename ${kernel_module} > /dev/null 2>&1 if [ 0 -eq 0 ]; then /sbin/modprobe ${kernel_module} fi done # 执行脚本,查看模块是否开启 chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs ip_vs_ftp 13079 0 nf_nat 26583 1 ip_vs_ftp ip_vs_sed 12519 0 ip_vs_nq 12516 0 ip_vs_sh 12688 0 ip_vs_dh 12688 0
1 yum install -y yum-utils device-mapper-persistent-data lvm2 wget net-tools nfs-utils lrzsz gcc gcc-c++ make cmake libxml2-devel openssl-devel curl curl-devel unzip sudo ntp libaio-devel wget vim ncurses-devel autoconf automake zlib-devel python-devel epel-release openssh-server socat ipvsadm conntrack ntpdate telnet bash-completion
1 2 3 4 5 6 7 8 9 # 如果用 firewalld 不习惯,可以安装 iptables # 安装 iptables yum install iptables-services -y # 禁用 iptables service iptables stop && systemctl disable iptables # 清空防火墙规则 iptables -F
安装docker
所有节点做相同操作
1 2 3 4 yum install docker-ce-20.10.6 docker-ce-cli-20.10.6 containerd.io -y systemctl start docker && systemctl enable docker systemctl status docker
1 2 3 4 5 6 7 8 9 10 vim /etc/docker/daemon.json { "registry-mirrors":["https://rsbud4vc.mirror.aliyuncs.com","https://registry.docker-cn.com","https://docker.mirrors.ustc.edu.cn","https://dockerhub.azk8s.cn","http://hub-mirror.c.163.com","http://qtid6917.mirror.aliyuncs.com","https://rncxm540.mirror.aliyuncs.com"], "exec-opts": ["native.cgroupdriver=systemd"] } # 修改 docker 文件驱动为 systemd,默认为 cgroupfs,kubelet 默认使用 systemd,两者必须一致才可以。 systemctl daemon-reload && systemctl restart docker systemctl status docker
安装初始化 k8s 需要的软件包
所有节点做相同操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 yum install -y kubelet-1.20.6 kubeadm-1.20.6 kubectl-1.20.6 systemctl enable kubelet && systemctl start kubelet # 可以看到 kubelet 状态不是 running 状态,这个是正常的,不用管,等 k8s 组件起来这个kubelet 就正常了。 systemctl status kubelet ● kubelet.service - kubelet: The Kubernetes Node Agent Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled) Drop-In: /usr/lib/systemd/system/kubelet.service.d └─10-kubeadm.conf Active: activating (auto-restart) (Result: exit-code) since 日 2023-07-16 12:16:23 CST; 9s ago Docs: https://kubernetes.io/docs/ Process: 13693 ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS (code=exited, status=255) Main PID: 13693 (code=exited, status=255) # 注:每个软件包的作用 # Kubeadm: kubeadm 是一个工具,用来初始化 k8s 集群的 # kubelet: 安装在集群所有节点上,用于启动 Pod 的 # kubectl: 通过 kubectl 可以部署和管理应用,查看各种资源,创建、删除和更新各种组件
kubeadm 初始化 k8s 集群
把初始化k8s集群需要的离线镜像包上传到master1、node1、node2机器上,手动解压
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@master1 ~]# docker load -i k8simage-1-20-6.tar.gz [root@node1 ~]# docker load -i k8simage-1-20-6.tar.gz [root@node2 ~]# docker load -i k8simage-1-20-6.tar.gz [root@master1 ~]# kubeadm init --kubernetes-version=1.20.6 --apiserver-advertise-address=192.168.1.180 --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr=10.244.0.0/16 --ignore-preflight-errors=SystemVerification [root@master1 ~]# mkdir -p $HOME/.kube [root@master1 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config [root@master1 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config [root@master1 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master1 NotReady control-plane,master 58s v1.20.6
扩容k8s集群-添加node节点
在master1上查看加入节点的命令
1 2 3 [root@master1 ~]# kubeadm token create --print-join-command kubeadm join 192.168.1.180:6443 --token h332xz.35p2obvl5vzmd3tc --discovery-token-ca-cert-hash sha256:89587e415db91f3f23eb029d3d7871f1dd1fa3562240277d2f49eed4f9d86f7c
在两个node节点上执行
1 2 3 [root@node1 ~]# kubeadm join 192.168.1.180:6443 --token h332xz.35p2obvl5vzmd3tc --discovery-token-ca-cert-hash sha256:89587e415db91f3f23eb029d3d7871f1dd1fa3562240277d2f49eed4f9d86f7c --ignore-preflight-errors=SystemVerification [root@node2 ~]# kubeadm join 192.168.1.180:6443 --token h332xz.35p2obvl5vzmd3tc --discovery-token-ca-cert-hash sha256:89587e415db91f3f23eb029d3d7871f1dd1fa3562240277d2f49eed4f9d86f7c --ignore-preflight-errors=SystemVerification
1 2 3 4 5 [root@master1 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master1 NotReady control-plane,master 3m31s v1.20.6 node1 NotReady <none> 110s v1.20.6 node2 NotReady <none> 81s v1.20.6
1 2 3 4 5 6 7 8 9 [root@master1 ~]# kubectl label node node1 node-role.kubernetes.io/worker=worker [root@master1 ~]# kubectl label node node2 node-role.kubernetes.io/worker=worker [root@master1 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master1 NotReady control-plane,master 3m57s v1.20.6 node1 NotReady worker 2m16s v1.20.6 node2 NotReady worker 107s v1.20.6
安装kubernetes网络组件calico 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [root@master1 ~]# kubectl apply -f calico.yaml [root@master1 ~]# kubectl get pod -n kube-system NAME READY STATUS RESTARTS AGE calico-kube-controllers-6949477b58-62b8l 1/1 Running 0 80s calico-node-4s4xl 1/1 Running 0 80s calico-node-lpml4 1/1 Running 0 80s calico-node-qbs7m 1/1 Running 0 80s coredns-7f89b7bc75-qmmp6 1/1 Running 0 6m1s coredns-7f89b7bc75-rpkgn 1/1 Running 0 6m1s etcd-master1 1/1 Running 0 6m16s kube-apiserver-master1 1/1 Running 1 6m16s kube-controller-manager-master1 1/1 Running 0 6m15s kube-proxy-4c7zm 1/1 Running 0 4m38s kube-proxy-lr4vd 1/1 Running 0 6m1s kube-proxy-vm6m4 1/1 Running 0 4m9s kube-scheduler-master1 1/1 Running 0 6m16s [root@master1 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master1 Ready control-plane,master 6m35s v1.20.6 node1 Ready worker 4m54s v1.20.6 node2 Ready worker 4m25s v1.20.6
测试在 k8s 创建 pod 是否可以正常访问网络
1 2 3 4 5 [root@master1 ~]# kubectl run busybox --image busybox:1.28 --restart=Never --rm -it busybox -- sh / # ping www.baidu.com PING www.baidu.com (39.156.66.18): 56 data bytes 64 bytes from 39.156.66.18: seq=0 ttl=127 time=39.3 ms
安装k8s可视化UI界面dashboard
把kubernetes-dashboard需要的镜像上传到工作阶段node1、node2
1 2 3 4 5 6 7 8 [root@node1 ~]# docker load -i dashboard_2_0_0.tar.gz [root@node1 ~]# docker load -i metrics-scrapter-1-0-1.tar.gz [root@node2 ~]# docker load -i dashboard_2_0_0.tar.gz [root@node2~]# docker load -i metrics-scrapter-1-0-1.tar.gz
上传dashboard的yaml文件到master1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@master1 ~]# kubectl apply -f kubernetes-dashboard.yaml [root@master1 ~]# kubectl get pods -n kubernetes-dashboard NAME READY STATUS RESTARTS AGE dashboard-metrics-scraper-7445d59dfd-kpqmf 1/1 Running 0 53s kubernetes-dashboard-54f5b6dc4b-h6v64 1/1 Running 0 53s [root@master1 ~]# kubectl get svc -n kubernetes-dashboard NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE dashboard-metrics-scraper ClusterIP 10.100.210.13 <none> 8000/TCP 80s kubernetes-dashboard ClusterIP 10.109.67.144 <none> 443/TCP 80s # 修改service type 类型为NodePort [root@master1 ~]# kubectl edit svc kubernetes-dashboard -n kubernetes-dashboard # 把 type : ClusterIP 变成 type : NodePort,保存退出即可 [root@master1 ~]# kubectl get svc -n kubernetes-dashboard NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE dashboard-metrics-scraper ClusterIP 10.100.210.13 <none> 8000/TCP 3m3s kubernetes-dashboard NodePort 10.109.67.144 <none> 443:32240/TCP 3m3s # 浏览器访问https://任意节点IP:32240访问kubernetes-dashboard
通过token令牌访问dashboard
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 # 创建管理员 token,具有查看任何空间的权限,可以管理所有资源对象 [root@master1 ~]# kubectl create clusterrolebinding dashboard-cluster-admin --clusterrole=cluster-admin --serviceaccount=kubernetes-dashboard:kubernetes-dashboard [root@master1 ~]# kubectl get secret -n kubernetes-dashboard NAME TYPE DATA AGE default-token-hwqss kubernetes.io/service-account-token 3 5m42s kubernetes-dashboard-certs Opaque 0 5m42s kubernetes-dashboard-csrf Opaque 1 5m42s kubernetes-dashboard-key-holder Opaque 2 5m42s kubernetes-dashboard-token-rtrkj kubernetes.io/service-account-token 3 5m42s [root@master1 ~]# kubectl describe secret kubernetes-dashboard-token-rtrkj -n kubernetes-dashboard Name: kubernetes-dashboard-token-rtrkj Namespace: kubernetes-dashboard Labels: <none> Annotations: kubernetes.io/service-account.name: kubernetes-dashboard kubernetes.io/service-account.uid: 62c6073e-c3ee-456f-8107-0afe0198a205 Type: kubernetes.io/service-account-token Data ==== ca.crt: 1066 bytes namespace: 20 bytes token: eyJhbGciOiJSUzI1NiIsImtpZCI6IjBCaXlVcWRjT29MSUhNVDdCOXN0TmpfUXNBdEhSdnBVazZqRWNKNENSRFEifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJrdWJlcm5ldGVzLWRhc2hib2FyZC10b2tlbi1ydHJraiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6IjYyYzYwNzNlLWMzZWUtNDU2Zi04MTA3LTBhZmUwMTk4YTIwNSIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlcm5ldGVzLWRhc2hib2FyZDprdWJlcm5ldGVzLWRhc2hib2FyZCJ9.Vy6P6WIyZW_CoKe0I3o3hUE7lnTdic8_C7vKS1iIXsqmwV7HruQbzW-Lt53HpnI5LixgXZWLFWnOHo9mpxAOdPRklucXGEi2s_fCbPp-_vx5hBC6HJvDrtM1iwyx0Hrcbi0auB6zNB_hS0qxMq7pFVEAc0oCeooI_EwH6Zm7xl5keZh4uixIhuMJKTtfOLLoolu6QGpS_W769PNeLvHmsogTgu53COrVP4m0s6P9_tVE5peYj3WeKfh7WO78dcmApxlclRJ4vjyyQe_XnldGNZ0pX60kgUMrufIxjKGx0pIouPJLlSOVJ8po5KUIaEKvQePm8CxpnCY531k6JukUnw
通过 kubeconfig 文件访问 dashboard
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # 创建 cluster 集群 [root@master1 ~]# cd /etc/kubernetes/pki [root@master1 pki]# kubectl config set-cluster kubernetes --certificate-authority=./ca.crt --server="https://192.168.1.180:6443" --embed-certs=true --kubeconfig=/root/dashboard-admin.conf # 创建credentials # 创建 credentials 需要使用上面的 kubernetes-dashboard-token-rtrkj 对应的 token 信息 [root@master1 pki]# DEF_NS_ADMIN_TOKEN=$(kubectl get secret kubernetes-dashboard-token-rtrkj -n kubernetes-dashboard -o jsonpath={.data.token}|base64 -d) [root@master1 pki]# kubectl config set-credentials dashboard-admin --token=$DEF_NS_ADMIN_TOKEN --kubeconfig=/root/dashboard-admin.conf # 创建context [root@master1 pki]# kubectl config set-context dashboard-admin@kubernetes --cluster=kubernetes --user=dashboard-admin --kubeconfig=/root/dashboard-admin.conf # 切换 context 的 current-context 是 dashboard-admin@kubernetes [root@master1 pki]# kubectl config use-context dashboard-admin@kubernetes --kubeconfig=/root/dashboard-admin.conf # 把刚才的 kubeconfig 文件 dashboard-admin.conf 复制到桌面 # 浏览器访问时使用 kubeconfig 认证,把刚才的 dashboard-admin.conf 导入到 web 界面,那么就可以登陆了
通过kubernetes-dashboard创建容器
1 2 3 # 把 nginx.tar.gz 镜像压缩包上传到 node1 和 node2 上,手动解压 docker load -i nginx.tar.gz
1 2 3 4 5 6 7 8 9 10 11 12 13 应用名称:nginx 容器镜像:nginx pod数量:2 service:external外部网络 port:80 targetport:80 注:表单中创建 pod 时没有创建 nodeport 的选项,会自动创建在 30000+以上的端口。 关于 port、targetport、nodeport 的说明: nodeport 是集群外流量访问集群内服务的端口,比如客户访问 nginx,apache port 是集群内的 pod 互相通信用的端口类型,比如 nginx 访问 mysql,而 mysql 是不需要让客户访问到的,port 是 service 的的端口 targetport 目标端口,也就是最终端口,也就是 pod 的端口
安装 metrics-server 组件
metrics-server 是一个集群范围内的资源数据集和工具,同样的,metrics-server 也只是显示数据,并不提供数据存储服务,主要关注的是资源度量 API 的实现,比如 CPU、文件描述符、内存、请求延时等指标,metric-server 收集数据给 k8s 集群内使用,如 kubectl,hpa,scheduler 等
1 2 3 4 5 6 7 8 9 10 11 12 # 把离线镜像压缩包上传到 k8s 的各个节点,按如下方法手动解压 [root@master1 ~]# docker load -i metrics-server-amd64-0-3-6.tar.gz [root@master1 ~]# docker load -i addon.tar.gz [root@node1 ~]# docker load -i metrics-server-amd64-0-3-6.tar.gz [root@node1 ~]# docker load -i addon.tar.gz [root@node2 ~]# docker load -i metrics-server-amd64-0-3-6.tar.gz [root@node2 ~]# docker load -i addon.tar.gz
在/etc/kubernetes/manifests 里面改一下 apiserver 的配置
注意:这个是 k8s 在 1.17 的新特性,如果是 1.16 版本的可以不用添加,1.17 以后要添加。这个参数的作用是 Aggregation 允许在不修改 Kubernetes 核心代码的同时扩展 Kubernetes API。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 [root@master1 ~]# vim /etc/kubernetes/manifests/kube-apiserver.yaml # 增加如下内容: - --enable-aggregator-routing=true # 重新更新apiserver配置 [root@master1 ~]# kubectl apply -f /etc/kubernetes/manifests/kube-apiserver.yaml [root@master1 ~]# kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE calico-kube-controllers-6949477b58-62b8l 1/1 Running 0 11h calico-node-4s4xl 1/1 Running 0 11h calico-node-lpml4 1/1 Running 0 11h calico-node-qbs7m 1/1 Running 0 11h coredns-7f89b7bc75-qmmp6 1/1 Running 0 11h coredns-7f89b7bc75-rpkgn 1/1 Running 0 11h etcd-master1 1/1 Running 0 11h kube-apiserver 0/1 CrashLoopBackOff 1 16s kube-apiserver-master1 1/1 Running 0 52s kube-controller-manager-master1 1/1 Running 1 11h kube-proxy-4c7zm 1/1 Running 0 11h kube-proxy-lr4vd 1/1 Running 0 11h kube-proxy-vm6m4 1/1 Running 0 11h kube-scheduler-master1 1/1 Running 1 11h # CrashLoopBackOff 状态的 pod 删除 [root@master1 ~]# kubectl delete pods kube-apiserver -n kube-system [root@master1 ~]# kubectl apply -f metrics.yaml [root@master1 ~]# kubectl get pods -n kube-system | grep metrics metrics-server-6595f875d6-hfgbk 2/2 Running 0 28s
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [root@master1 ~]# kubectl top pods -n kube-system NAME CPU(cores) MEMORY(bytes) calico-kube-controllers-6949477b58-62b8l 1m 25Mi calico-node-4s4xl 31m 77Mi calico-node-lpml4 37m 85Mi calico-node-qbs7m 36m 80Mi coredns-7f89b7bc75-qmmp6 4m 25Mi coredns-7f89b7bc75-rpkgn 4m 21Mi etcd-master1 21m 82Mi kube-apiserver-master1 59m 399Mi kube-controller-manager-master1 18m 49Mi kube-proxy-4c7zm 1m 10Mi kube-proxy-lr4vd 1m 10Mi kube-proxy-vm6m4 1m 10Mi kube-scheduler-master1 4m 25Mi metrics-server-6595f875d6-hfgbk 1m 16Mi [root@master1 ~]# kubectl top nodes NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% master1 181m 4% 2157Mi 56% node1 92m 2% 1686Mi 44% node2 100m 2% 1698Mi 44%
把 scheduler、controller-manager 端口变成物理机可以监听的端口 1 2 3 4 5 6 [root@master1 ~]# kubectl get cs Warning: v1 ComponentStatus is deprecated in v1.19+ NAME STATUS MESSAGE ERROR scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused etcd-0 Healthy {"health":"true"}
默认在 1.19 之后 10252 和 10251 都是绑定在 127 的,如果想要通过 prometheus 监控,会采集不到数据,所以可以把端口绑定到物理机
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 # 可按如下方法处理: vim /etc/kubernetes/manifests/kube-scheduler.yaml # 修改如下内容: 把--bind-address=127.0.0.1 变成--bind-address=192.168.1.180 把 httpGet:字段下的 hosts 由 127.0.0.1 变成 192.168.1.180 把—port=0 删除 # 注意:192.168.1.180 是 k8s 的控制节点 master1 的 ip vim /etc/kubernetes/manifests/kube-controller-manager.yaml 把--bind-address=127.0.0.1 变成--bind-address=192.168.1.180 把 httpGet:字段下的 hosts 由 127.0.0.1 变成 192.168.1.180 把—port=0 删除 # 修改之后在 k8s 各个节点重启下 kubelet systemctl restart kubelet [root@master1 ~]# kubectl get cs Warning: v1 ComponentStatus is deprecated in v1.19+ NAME STATUS MESSAGE ERROR scheduler Healthy ok controller-manager Healthy ok etcd-0 Healthy {"health":"true"} [root@master1 ~]# ss -antulp | grep 10251 tcp LISTEN 0 128 :::10251 :::* users:(("kube-scheduler",pid=16849,fd=7)) [root@master1 ~]# ss -antulp | grep 10252 tcp LISTEN 0 128 :::10252 :::* users:(("kube-controller",pid=17730,fd=7)) # 可以看到相应的端口已经被物理机监听了
Pod基础 k8s核心资源Pod介绍
K8s 官方文档:https://kubernetes.io/
K8s 中文官方文档:https://kubernetes.io/zh/
K8s Github 地址:https://github.com/kubernetes/
Pod是什么
Pod 是 Kubernetes 中的最小调度单元,k8s 是通过定义一个 Pod 的资源,然后在 Pod 里面运行容器,容器需要指定一个镜像,这样就可以用来运行具体的服务。一个 Pod 封装一个容器(也可以封装多个容器),Pod 里的容器共享存储、网络等。也就是说,应该把整个 pod 看作虚拟机,然后每个容器相当于运行在虚拟机的进程。
Pod 是需要调度到 k8s 集群的工作节点来运行的,具体调度到哪个节点,是根据 scheduler 调度器实现的。
Pod 如何管理多个容器
Pod 中可以同时运行多个容器。同一个 Pod 中的容器会自动的分配到同一个 node 上。
同一个 Pod 中的容器共享资源、网络环境,它们总是被同时调度,在一个 Pod 中同时运行多个容器是一种比较高级的用法,只有当你的容器需要紧密配合协作的时候才考虑用这种模式。
例如,你有一个容器作为 web 服务器运行,需要用到共享的 volume,有另一个“sidecar”容器来从远端获取资源更新这些文件。
一些 Pod 有 init 容器和应用容器。 在应用程序容器启动之前,运行初始化容器。
Pod网络
Pod存储
创建 Pod 的时候可以指定挂载的存储卷。 POD 中的所有容器都可以访问共享卷,允许这些容器共享数据。 Pod 只要挂载持久化数据卷,Pod 重启之后数据还是会存在的。
Pod工作方式
在 K8s 中,所有的资源都可以使用一个 yaml 文件来创建,创建 Pod 也可以使用 yaml 配置文件。或者使用 kubectl run 在命令行创建 Pod(不常用)。
自主式Pod
所谓的自主式 Pod,就是直接定义一个 Pod 资源
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@master1 ~ ] apiVersion: v1 kind: Pod metadata: name: tomcat-test namespace: default labels: app: tomcat spec: containers: - name: tomcat image: tomcat imagePullPolicy: IfNotPresent ports: - containerPort: 8080
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@master1 ~]# kubectl apply -f pod-tomcat.yaml [root@master1 ~]# kubectl get pods -o wide -l app=tomcat NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES tomcat-test 1/1 Running 0 70s 10.244.166.135 node1 <none> <none> # 但是自主式 Pod 是存在一个问题的,假如我们不小心删除了 pod,pod就会被永久删除 [root@master1 ~]# kubectl delete pods tomcat-test [root@master1 ~]# kubectl get pods -o wide -l app=tomcat No resources found in default namespace. # 通过上面可以看到,如果直接定义一个 Pod 资源,那 Pod 被删除,就彻底被删除了,不会再创建一个新的 Pod # 这在生产环境还是具有非常大风险的,所以今后我们接触的 Pod,都是控制器管理的。
控制器管理Pod
常见的管理 Pod 的控制器:Replicaset、Deployment、Job、CronJob、Daemonset、Statefulset。控制器管理的 Pod 可以确保 Pod 始终维持在指定的副本数运行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 [root@master1 ~ ] apiVersion: apps/v1 kind: Deployment metadata: name: nginx-test namespace: default labels: app: nginx-deploy spec: selector: matchLabels: app: nginx-deploy replicas: 2 template: metadata: labels: app: nginx-deploy spec: containers: - name: nginx image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 [root@master1 ~]# kubectl apply -f nginx-deploy.yaml # 查看Deployment [root@master1 ~]# kubectl get deploy -l app=nginx-deploy NAME READY UP-TO-DATE AVAILABLE AGE nginx-test 2/2 2 2 77s # 查看Replicaset [root@master1 ~]# kubectl get rs -l app=nginx-deploy NAME DESIRED CURRENT READY AGE nginx-test-68b6d698b7 2 2 2 89s # 查看Pod [root@master1 ~]# kubectl get pod -l app=nginx-deploy NAME READY STATUS RESTARTS AGE nginx-test-68b6d698b7-qvpfg 1/1 Running 0 11m nginx-test-68b6d698b7-wxlq2 1/1 Running 0 11m # 删除nginx-test-68b6d698b7-qvpfg这个pod [root@master1 ~]# kubectl delete pod nginx-test-68b6d698b7-qvpfg # 会发现重新创建了一个pod nginx-test-68b6d698b7-7qsk8 [root@master1 ~]# kubectl get pod -l app=nginx-deploy NAME READY STATUS RESTARTS AGE nginx-test-68b6d698b7-7qsk8 1/1 Running 0 17s nginx-test-68b6d698b7-wxlq2 1/1 Running 0 12m # 通过上面可以发现通过 deployment 管理的 pod,可以确保 pod 始终维持在指定副本数量
Pod创建具体流程
Pod 是 Kubernetes 中最基本的部署调度单元,可以包含 container,逻辑上表示某种应用的一个实例。
例如一个 web 站点应用由前端、后端及数据库构建而成,这三个组件将运行在各自的容器中,那么我们可以创建包含三个 container 的 pod。
master 节点:kubectl -> kube-api -> kubelet -> CRI 容器环境初始化
第一步
客户端提交创建 Pod 的请求,可以通过调用 API Server 的 Rest API 接口,也可以通过 kubectl 命令行工具。如 kubectl apply -f filename.yaml(资源清单文件)
第二步
apiserver 接收到 pod 创建请求后,会将 yaml 中的属性信息(metadata)写入 etcd。
第三步
apiserver触发 watch 机制准备创建 pod,信息转发给调度器 scheduler,调度器使用调度算法选择node,调度器将 node 信息给 apiserver,apiserver 将绑定的 node 信息写入 etcd调度器用一组规则过滤掉不符合要求的主机。比如 Pod 指定了所需要的资源量,那么可用资源比 Pod 需要的资源量少的主机会被过滤掉。
scheduler 查看 k8s api ,类似于通知机制。
首先判断:pod.spec.Node == null?
若为 null,表示这个 Pod 请求是新来的,需要创建;因此先进行调度计算,找到最“闲”的 node。
然后将信息在 etcd 数据库中更新分配结果:pod.spec.Node = nodeA (设置一个具体的节点)
ps:同样上述操作的各种信息也要写到 etcd 数据库中
第四步
apiserver 又通过 watch 机制,调用 kubelet,指定 pod 信息,调用 Docker API 创建并启动 pod 内的容器。
第五步
创建完成之后反馈给 kubelet, kubelet 又将 pod 的状态信息给 apiserver,apiserver 又将 pod 的状态信息写入 etcd。
Pod 资源清单编写技巧 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 # 通过 kubectl explain 查看定义 Pod 资源包含哪些字段 [root@master1 ~]# kubectl explain pod KIND: Pod VERSION: v1 DESCRIPTION: Pod is a collection of containers that can run on a host. This resource is created by clients and scheduled onto hosts. # [Pod 是可以在主机上运行的容器的集合。此资源是由客户端创建并安排到主机上] FIELDS: apiVersion <string> APIVersion defines the versioned schema of this representation of an object. Servers should convert recognized schemas to the latest internal value, and may reject unrecognized values. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources # [APIVersion 定义了对象,代表了一个版本] kind <string> Kind is a string value representing the REST resource this object represents. Servers may infer this from the endpoint the client submits requests to. Cannot be updated. In CamelCase. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds # [Kind 是字符串类型的值,代表了要创建的资源。服务器可以从客户端提交的请求推断出这个资源] metadata <Object> Standard object's metadata. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata # [metadata 是对象,定义元数据属性信息的] spec <Object> Specification of the desired behavior of the pod. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status # [spec 制定了定义 Pod 的规格,里面包含容器的信息] Docker 镜像信息等,例如时间戳、release id 号、镜像 hash 值、docker registry 地址等; # 日志库、监控库、分析库等资源库的地址信息; # 程序调试工具信息,例如工具名称、版本号等; # 团队的联系信息,例如电话号码、负责人名称、网址等。 clusterName <string> The name of the cluster which the object belongs to. This is used to distinguish resources with same name and namespace in different clusters. This field is not set anywhere right now and apiserver is going to ignore it if set in create or update request. # 对象所属群集的名称。这是用来区分不同集群中具有相同名称和命名空间的资源。 # 此字段现在未设置在任何位置,apiserver 将忽略它,如果设置了就使用设置的值 creationTimestamp <string> deletionTimestamp <string> finalizers <[]string> generateName <string> generation <integer> labels <map[string]string> # 创建的资源具有的标签 Map of string keys and values that can be used to organize and categorize (scope and select) objects. May match selectors of replication controllers and services. More info: http://kubernetes.io/docs/user-guide/labels # labels 是标签,labels 是 map 类型,map 类型表示对应的值是 key-value 键值对 # <string,string>表示 key 和 value 都是 String 类型的 managedFields <[]Object> name <string> # 创建资源的名字 namespace <string> # 创建资源所属的名称空间 Namespace defines the space within which each name must be unique. An empty namespace is equivalent to the "default" namespace, but "default" is the canonical representation. Not all objects are required to be scoped to a namespace - the value of this field for those objects will be empty. Must be a DNS_LABEL. Cannot be updated. More info: http://kubernetes.io/docs/user-guide/namespaces # namespaces 划分了一个空间,在同一个 namesace 下的资源名字是唯一的,默认的名称空间是default。 ownerReferences <[]Object> resourceVersion <string> selfLink <string> uid <string>
查看pod.spec字段如何定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 [root@master1 ~]# kubectl explain pod.spec KIND: Pod VERSION: v1 RESOURCE: spec <Object> DESCRIPTION: Specification of the desired behavior of the pod. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status PodSpec is a description of a pod. # Pod 的 spec 字段是用来描述 Pod 的 FIELDS: activeDeadlineSeconds <integer> # 表示 Pod 可以运行的最长时间,达到设置的值后,Pod 会自动停止。 affinity <Object> # 定义亲和性的 containers <[]Object> -required- # containers 是对象列表,用来定义容器的,是必须字段。 # 对象列表 表示下面有很多对象,对象列表下面的内容用 - 连接。 dnsConfig <Object> dnsPolicy <string> enableServiceLinks <boolean> ephemeralContainers <[]Object> hostAliases <[]Object> hostIPC <boolean> hostNetwork <boolean> hostPID <boolean> hostname <string> imagePullSecrets <[]Object> initContainers <[]Object> nodeName <string> nodeSelector <map[string]string> overhead <map[string]string> preemptionPolicy <string> priority <integer> priorityClassName <string> readinessGates <[]Object> restartPolicy <string> runtimeClassName <string> schedulerName <string> securityContext <Object> serviceAccount <string> serviceAccountName <string> setHostnameAsFQDN <boolean> shareProcessNamespace <boolean> subdomain <string> terminationGracePeriodSeconds <integer> tolerations <[]Object> topologySpreadConstraints <[]Object> volumes <[]Object>
查看pod.spec.containers字段如何定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 [root@master1 ~]# kubectl explain pod.spec.containers KIND: Pod VERSION: v1 RESOURCE: containers <[]Object> DESCRIPTION: List of containers belonging to the pod. Containers cannot currently be added or removed. There must be at least one container in a Pod. Cannot be updated. A single application container that you want to run within a pod. # container 是定义在 pod 里面的,一个 pod 至少要有一个容器。 FIELDS: args <[]string> command <[]string> env <[]Object> envFrom <[]Object> image <string> # 用来指定容器需要的镜像 imagePullPolicy <string> # 镜像拉取策略,pod 是要调度到 node 节点的,那 pod 启动需要镜像,可以根据这个字段设置镜像拉取策略,支持如下三种: # Always:不管本地是否存在镜像,都要重新拉取镜像 # Never: 从不拉取镜像 # IfNotPresent:如果本地存在,使用本地的镜像,本地不存在,从官方拉取镜像 lifecycle <Object> livenessProbe <Object> name <string> -required- # name 是必须字段,用来指定容器名字的 ports <[]Object> # port是端口,属于对象列表 readinessProbe <Object> resources <Object> securityContext <Object> startupProbe <Object> stdin <boolean> stdinOnce <boolean> terminationMessagePath <string> terminationMessagePolicy <string> tty <boolean> volumeDevices <[]Object> volumeMounts <[]Object> workingDir <string>
查看pod.spec.containers.ports字段如何定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 [root@master1 ~]# kubectl explain pod.spec.containers.ports KIND: Pod VERSION: v1 RESOURCE: ports <[]Object> DESCRIPTION: List of ports to expose from the container. Exposing a port here gives the system additional information about the network connections a container uses, but is primarily informational. Not specifying a port here DOES NOT prevent that port from being exposed. Any port which is listening on the default "0.0.0.0" address inside a container will be accessible from the network. Cannot be updated. ContainerPort represents a network port in a single container. FIELDS: containerPort <integer> -required- Number of port to expose on the pod's IP address. This must be a valid port number, 0 < x < 65536. # containerPort 是必须字段, pod 中的容器需要暴露的端口。 hostIP <string> What host IP to bind the external port to. # 将容器中的服务暴露到宿主机的端口上时,可以指定绑定的宿主机 IP。 hostPort <integer> Number of port to expose on the host. If specified, this must be a valid port number, 0 < x < 65536. If HostNetwork is specified, this must match ContainerPort. Most containers do not need this. # 容器中的服务在宿主机上映射的端口 name <string> If specified, this must be an IANA_SVC_NAME and unique within the pod. Each named port in a pod must have a unique name. Name for the port that can be referred to by services. # 端口的名字 protocol <string> Protocol for port. Must be UDP, TCP, or SCTP. Defaults to "TCP". # 端口协议
通过资源清单文件创建Pod 1 2 3 4 5 6 7 8 9 10 11 12 13 14 apiVersion: v1 kind: Pod metadata: name: tomcat-test namespace: default labels: app: pod spec: containers: - name: pod-container image: tomcat imagePullPolicy: IfNotPresent ports: - containerPort: 8080
1 2 3 4 5 [root@master1 ~]# kubectl apply -f pod-tomcat.yaml [root@master1 ~]# kubectl get pods -o wide -l app=tomcat NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES tomcat-test 1/1 Running 0 23s 10.244.166.138 node1 <none> <none>
1 2 3 4 [root@master1 ~]# kubectl logs tomcat-test # 查看pod里指定容器的日志 [root@master1 ~]# kubectl logs tomcat-test -c tomcat
1 2 3 4 [root@master1 ~]# kubectl exec -it tomcat-test -- /bin/bash # 假如 pod 里有多个容器,进入到 pod 里的指定容器 [root@master1 ~]# kubectl exec -it tomcat-test -c tomcat -- /bin/bash
我们上面创建的 pod 是一个自主式 pod,也就是通过 pod 创建一个应用程序,如果 pod 出现故障停掉,那么我们通过 pod 部署的应用也就会停掉,不安全, 还有一种控制器管理的 pod,通过控制器创建pod,可以对 pod 的生命周期做管理,可以定义 pod 的副本数,如果有一个 pod 意外停掉,那么会自动起来一个 pod 替代之前的 pod
通过kubectl run创建Pod 1 [root@master1 ~]# kubectl run tomcat --image=tomcat --image-pull-policy='IfNotPresent' --port 8080
Pod资源清单详细解读 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 apiVersion: v1 kind: Pod metadata: name: string namespace: string labels: - name: string annotations: - name: string spec: containers: - name: string image: string imagePullPolicy: [Always | Never | IfNotPresent ] command: [string ] args: [string ] workingDir: string volumeMounts: - name: string mountPath: string readOnly: boolean ports: - name: string containerPort: int hostPort: int protocol: string env: - name: string value: string resources: limits: cpu: string memory: string requests: cpu: string memory: string livenessProbe: exec: command: [string ] httpGet: path: string port: number host: string scheme: string HttpHeaders: - name: string value: string tcpSocket: port: number initialDelaySeconds: 0 timeoutSeconds: 0 periodSeconds: 0 successThreshold: 0 failureThreshold: 0 securityContext: privileged: false restartPolicy: [Always | Never | OnFailure ] nodeSelector: obeject imagePullSecrets: - name: string hostNetwork: false volumes: - name: string emptyDir: {} hostPath: string path: string secret: scretname: string items: - key: string path: string configMap: name: string items: - key: string path: string
命名空间 什么是命名空间
Kubernetes 支持多个虚拟集群,它们底层依赖于同一个物理集群。 这些虚拟集群被称为命名空间。
命名空间 namespace 是 k8s 集群级别的资源,可以给不同的用户、租户、环境或项目创建对应的命名空间
例如,可以为 test、devlopment、production 环境分别创建各自的命名空间。
namespace应用场景
命名空间适用于存在很多跨多个团队或项目的用户的场景。对于只有几到几十个用户的集群,根本不需要创建或考虑命名空间。
1、查看名称空间及其资源对象
2、管理 namespace 资源
namespace 资源属性较少,通常只需要指定名称即可创建,如“kubectl create namespace qa”。namespace 资源的名称仅能由字母、数字、下划线、连接线等字符组成。删除 namespace 资源会级联删除其包含的所有其他资源对象。
namespace使用案例 创建一个test命名空间 1 [root@master1 ~]# kubectl create ns test
切换命名空间
切换命名空间后,kubectl get pods 如果不指定-n,查看的就是 kube-system 命名空间的资源了。
1 [root@master1 ~]# kubectl config set-context --current --namespace=kube-system
查看哪些资源属于命名空间级别的 1 [root@master1 ~]# kubectl api-resources --namespaced=true
namespace 资源限额
namespace 是命名空间,里面有很多资源,可以对命名空间资源做个限制,防止该命名空间部署的资源超过限制
1 [root@master1 ~]# kubectl config set-context --current –namespace=default
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [root@master1 ~ ] apiVersion: v1 kind: ResourceQuota metadata: name: mem-cpu-quota namespace: default spec: hard: requests.cpu: "2" requests.memory: 2Gi limits.cpu: "4" limits.memory: 4Gi
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@master1 ~ ] apiVersion: v1 kind: Pod metadata: name: pod-test namespace: default labels: app: tomcat-pod-test spec: containers: - name: tomcat-pod-test image: tomcat imagePullPolicy: IfNotPresent ports: - containerPort: 8080 resources: requests: memory: "100Mi" cpu: "500m" limits: memory: "2Gi" cpu: "2"
标签 什么是标签
标签其实就一对 key/value ,被关联到对象上,比如 Pod
标签的使用我们倾向于能够表示对象的特殊特点,就是一眼就看出了这个 Pod 是干什么的,标签可以用来划分特定的对象(比如版本,服务类型等)
标签可以在创建一个对象的时候直接定义,也可以在后期随时修改,每一个对象可以拥有多个标签
但是,key 值必须是唯一的。创建标签之后也可以方便我们对资源进行分组管理。
如果对 pod 打标签,之后就可以使用标签来查看、删除指定的 pod。
在 k8s 中,大部分资源都可以打标签。
给pod资源打标签 1 2 3 4 5 6 # 对已经存在的pod打标签 [root@master1 ~]# kubectl label pods tomcat release=v1 [root@master1 ~]# kubectl get pods tomcat --show-labels NAME READY STATUS RESTARTS AGE LABELS tomcat 1/1 Running 0 3h48m release=v1,run=tomcat
查看资源标签 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # 查看默认名称空间下所有pod资源的标签 kubectl get pods --show-labels # 查看默认名称空间下指定pod具有的所有标签 kubectl get pods tomcat --show-labels # 列出默认名称空间下标签key是release的pod,不显示标签 kubectl get pods -l release # 列出默认名称空间下标签key是release、值是v1的pod,不显示标签 kubectl get pods -l release=v1 # 列出默认名称空间下标签 key 是 release 的所有 pod,并打印对应的标签值 kubectl get pods -L release # 查看所有名称空间下的所有 pod 的标签 kubectl get pods --all-namespaces --show-labels
node节点选择器
在创建 pod 资源的时候,pod 会根据 schduler 进行调度,那么默认会调度到随机的一个工作节点,如果想要 pod 调度到指定节点或者调度到一些具有相同特点的 node 节点,可以使用 pod 中的 nodeName 或者 nodeSelector 字段指定要调度到的 node 节点
nodeName
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 [root@master1 ~ ] apiVersion: v1 kind: Pod metadata: name: demo-pod namespace: default labels: app: myapp env: dev spec: nodeName: node1 containers: - name: tomcat ports: - containerPort: 8080 image: tomcat imagePullPolicy: IfNotPresent - name: busybox image: busybox command: - "/bin/sh" - "-c" - "sleep 3600" [root@master1 ~ ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES demo-pod 2 /2 Running 0 22s 10.244 .166 .147 node1 <none> <none>
nodeSelector
指定 pod 调度到具有哪些标签的 node 节点上
给 node 节点打标签,打个具有 disk=ceph 的标签
1 [root@master1 ~]# kubectl label nodes node2 disk=ceph
定义 pod 的时候指定要调度到具有 disk=ceph 标签的 node 上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [root@master1 ~ ] apiVersion: v1 kind: Pod metadata: name: demo-pod-1 namespace: default labels: app: myapp env: dev spec: nodeSelector: disk: ceph containers: - name: tomcat ports: - containerPort: 8080 image: tomcat imagePullPolicy: IfNotPresent [root@master1 ~ ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES demo-pod-1 1 /1 Running 0 45s 10.244 .104 .19 node2 <none> <none>
亲和、污点和容忍度 node节点亲和性
node 节点亲和性调度:nodeAffinity
1 2 3 4 5 6 7 8 9 10 11 12 [root@master1 ~]# kubectl explain pods.spec.affinity KIND: Pod VERSION: v1 RESOURCE: affinity <Object> DESCRIPTION: If specified, the pod's scheduling constraints Affinity is a group of affinity scheduling rules. FIELDS: nodeAffinity <Object> podAffinity <Object> podAntiAffinity <Object>
查看pods.spec.affinity.nodeAffinity字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@master1 ~]# kubectl explain pods.spec.affinity.nodeAffinity KIND: Pod VERSION: v1 RESOURCE: nodeAffinity <Object> DESCRIPTION: Describes node affinity scheduling rules for the pod. Node affinity is a group of node affinity scheduling rules. FIELDS: preferredDuringSchedulingIgnoredDuringExecution <[]Object> requiredDuringSchedulingIgnoredDuringExecution <Object> # prefered 表示有节点尽量满足这个位置定义的亲和性,这不是一个必须的条件,软亲和性 # require 表示必须有节点满足这个位置定义的亲和性,这是个硬性条件,硬亲和性
查看pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution字段
1 2 3 4 5 6 7 8 9 [root@master1 ~]# kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution KIND: Pod VERSION: v1 RESOURCE: requiredDuringSchedulingIgnoredDuringExecution <Object> DESCRIPTION: FIELDS: nodeSelectorTerms <[]Object> -required- Required. A list of node selector terms. The terms are ORed.
查看pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [root@master1 ~]# kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms KIND: Pod VERSION: v1 RESOURCE: nodeSelectorTerms <[]Object> DESCRIPTION: Required. A list of node selector terms. The terms are ORed. A null or empty node selector term matches no objects. The requirements of them are ANDed. The TopologySelectorTerm type implements a subset of the NodeSelectorTerm. FIELDS: matchExpressions <[]Object> A list of node selector requirements by node's labels. matchFields <[]Object> A list of node selector requirements by node's fields. # matchExpressions:匹配表达式的 (node标签) # matchFields: 匹配字段的
查看pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms.matchFields字段
1 2 3 4 5 6 7 8 9 [root@master1 ~]# kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms.matchFields KIND: Pod VERSION: v1 RESOURCE: matchFields <[]Object> FIELDS: key <string> -required- operator <string> -required- values <[]string>
查看pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms.matchExpressions字段
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@master1 ~]# kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms.matchExpressions KIND: Pod VERSION: v1 RESOURCE: matchExpressions <[]Object> FIELDS: key <string> -required- operator <string> -required- values <[]string> # key:检查 label # operator:做等值选则还是不等值选则 # values:给定值
使用 requiredDuringSchedulingIgnoredDuringExecution 硬亲和性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 apiVersion: v1 kind: Pod metadata: name: pod-node-affinity namespace: default labels: app: myapp tier: frontend spec: containers: - name: myapp image: ikubernetes/myapp:v1 affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: zone operator: In values: - foo - bar
检查当前节点中有任意一个节点拥有 zone 标签的值是 foo 或者 bar,就可以把 pod 调度到这个 node 节点的 foo 或者 bar 标签上的节点上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@master1 ~]# kubectl apply -f pod-nodeaffinity.yaml [root@master1 ~]# kubectl get pods pod-node-affinity NAME READY STATUS RESTARTS AGE pod-node-affinity 0/1 Pending 0 28s # status 的状态是 pending,上面说明没有完成调度,因为没有一个拥有 zone 的标签的值是 foo 或者 bar,而且使用的是硬亲和性,必须满足条件才能完成调度 # 给node1打赏zoo=foo标签 [root@master1 ~]# kubectl label nodes node1 zone=foo [root@master1 ~]# kubectl get pods pod-node-affinity NAME READY STATUS RESTARTS AGE pod-node-affinity 1/1 Running 6 6m50s
使用 preferredDuringSchedulingIgnoredDuringExecution 软亲和性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 apiVersion: v1 kind: Pod metadata: name: pod-node-affinity-2 namespace: default labels: app: myapp tier: frontend spec: containers: - name: myapp image: ikubernetes/myapp:v1 affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - preference: matchExpressions: - key: zone1 operator: In values: - foo1 - bar1 weight: 60
上面说明软亲和性是可以运行这个 pod 的,尽管没有运行这个 pod 的节点定义的 zone1 标签
Node 节点亲和性针对的是 pod 和 node 的关系,Pod 调度到 node 节点的时候匹配的条件
1 2 3 4 5 6 [root@master1 ~]# kubectl apply -f pod-nodeaffinity.yaml [root@master1 ~]# kubectl get pods pod-node-affinity-2 NAME READY STATUS RESTARTS AGE pod-node-affinity-2 1/1 Running 0 67s
Pod节点亲和性
pod 自身的亲和性调度有两种表示形式
podaffinity:pod 和 pod 更倾向腻在一起,把相近的 pod 结合到相近的位置,如同一区域,同一机架,这样的话 pod 和 pod 之间更好通信,比方说有两个机房,这两个机房部署的集群有 1000 台主机,那么我们希望把 nginx 和 tomcat 都部署同一个地方的 node 节点上,可以提高通信效率;
podantiaffinity:pod 和 pod 更倾向不腻在一起,如果部署两套程序,那么这两套程序更倾向于反亲和性,这样相互之间不会有影响。
第一个 pod 随机选则一个节点,做为评判后续的 pod 能否到达这个 pod 所在的节点上的运行方式,这就称为 pod 亲和性;怎么判定哪些节点是相同位置的,哪些节点是不同位置的;在定义 pod 亲和性时需要有一个前提,哪些 pod 在同一个位置,哪些 pod 不在同一个位置,这个位置是怎么定义的,标准是什么?以节点名称为标准,这个节点名称相同的表示是同一个位置,节点名称不相同的表示不是一个位置。
查看pods.spec.affinity.podAffinity字段
1 2 3 4 5 6 7 8 9 10 11 [root@master1 ~]# kubectl explain pods.spec.affinity.podAffinity KIND: Pod VERSION: v1 RESOURCE: podAffinity <Object> FIELDS: preferredDuringSchedulingIgnoredDuringExecution <[]Object> requiredDuringSchedulingIgnoredDuringExecution <[]Object> # requiredDuringSchedulingIgnoredDuringExecution: 硬亲和性 # preferredDuringSchedulingIgnoredDuringExecution:软亲和性
查看pods.spec.affinity.podAffinity.requiredDuringSchedulingIgnoredDuringExecution字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 [root@master1 ~]# kubectl explain pods.spec.affinity.podAffinity.requiredDuringSchedulingIgnoredDuringExecution KIND: Pod VERSION: v1 RESOURCE: requiredDuringSchedulingIgnoredDuringExecution <[]Object> DESCRIPTION: FIELDS: labelSelector <Object> namespaces <[]string> topologyKey <string> -required- # topologyKey: # 位置拓扑的键,这个是必须字段 # 怎么判断是不是同一个位置: # rack=rack1 # row=row1 # 使用 rack 的键是同一个位置 # 使用 row 的键是同一个位置 # labelSelector: # 判断 pod 跟别的 pod 亲和,跟哪个 pod 亲和,需要靠 labelSelector,通过 labelSelector选则一组能作为亲和对象的 pod 资源 # namespace: # labelSelector 需要选则一组资源,那么这组资源是在哪个名称空间中呢,通过 namespace 指定,如果不指定 namespaces,那么就是当前创建 pod 的名称空间
查看pods.spec.affinity.podAffinity.requiredDuringSchedulingIgnoredDuringExecution.labelSelector字段
1 2 3 4 5 6 7 8 9 [root@master1 ~]# kubectl explain pods.spec.affinity.podAffinity.requiredDuringSchedulingIgnoredDuringExecution.labelSelector KIND: Pod VERSION: v1 RESOURCE: labelSelector <Object> FIELDS: matchExpressions <[]Object> matchLabels <map[string]string>
pod节点亲和性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 --- apiVersion: v1 kind: Pod metadata: name: pod-1 labels: app: myapp tier: frontend spec: containers: - name: myapp image: ikubernetes/myapp:v1 --- apiVersion: v1 kind: Pod metadata: name: pod-2 labels: app: backend tier: db spec: containers: - name: busybox image: busybox imagePullPolicy: IfNotPresent command: ["sh" ,"-c" ,"sleep 3600" ] affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - myapp topologyKey: kubernetes.io/hostname [root@master1 ~ ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod-1 1 /1 Running 0 8m52s 10.244 .166 .150 node1 <none> <none> pod-2 1 /1 Running 0 50s 10.244 .166 .151 node1 <none> <none>
pod节点反亲和性
不要与已经存在的pod的标签冲突
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 --- apiVersion: v1 kind: Pod metadata: name: pod-1 labels: app: myapp tier: frontend spec: containers: - name: myapp image: ikubernetes/myapp:v1 --- apiVersion: v1 kind: Pod metadata: name: pod-2 labels: app: bachend tier: db spec: containers: - name: busybox image: busybox imagePullPolicy: IfNotPresent command: ["sh" ,"-c" ,"sleep 3600" ] affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - myapp topologyKey: kubernetes.io/hostname [root@master1 ~ ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod-1 1 /1 Running 0 2m3s 10.244 .166 .152 node1 <none> <none> pod-2 1 /1 Running 0 89s 10.244 .104 .20 node2 <none> <none>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 [root@master1 ~ ] [root@master1 ~ ] --- apiVersion: v1 kind: Pod metadata: name: pod-1 labels: app: myapp tier: frontend spec: containers: - name: myapp image: ikubernetes/myapp:v1 --- apiVersion: v1 kind: Pod metadata: name: pod-2 labels: app: bachend tier: db spec: containers: - name: busybox image: busybox imagePullPolicy: IfNotPresent command: ["sh" ,"-c" ,"sleep 3600" ] affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - myapp topologyKey: zone [root@master1 ~ ] NAME READY STATUS RESTARTS AGE pod-1 1 /1 Running 0 4s pod-2 0 /1 Pending 0 4s
第二个节点现是 pending,因为两个节点是同一个位置,现在没有不是同一个位置的了,而且要求反亲和性,所以就会处于 pending 状态,如果在反亲和性这个位置把 required 改成 preferred,那么也会运行。
podaffinity:pod 节点亲和性,pod 倾向于哪个 podnodeaffinity:node 节点亲和性,pod 倾向于哪个 node
污点,容忍度
给了节点选则的主动权,我们给节点打一个污点,不容忍的 pod 就运行不上来,污点就是定义在节点上的键值属性数据,可以定决定拒绝那些 pod
taints 是键值数据,用在节点上,定义污点
tolerations 是键值数据,用在 pod 上,定义容忍度,能容忍哪些污点
pod 亲和性是 pod 属性;但是污点是节点的属性,污点定义在 nodeSelector 上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 [root@master1 ~]# kubectl explain node.spec.taints KIND: Node VERSION: v1 RESOURCE: taints <[]Object> FIELDS: effect <string> -required- key <string> -required- timeAdded <string> value <string> # taints 的 effect 用来定义对 pod 对象的排斥等级(效果): # NoSchedule: 仅影响 pod 调度过程,当 pod 能容忍这个节点污点,就可以调度到当前节点,后来这个节点的污点改了,加了一个新的污点,使得之前调度的 pod 不能容忍了,那这个 pod 会怎么处理,对现存的 pod 对象不产生影响 # NoExecute: 既影响调度过程,又影响现存的 pod 对象,如果现存的 pod 不能容忍节点后来加的污点,这个 pod 就会被驱逐 # PreferNoSchedule: 最好不,也可以,是 NoSchedule 的柔性版本
在 pod 对象定义容忍度的时候支持两种操作
1.等值密钥:key 和 value 上完全匹配
2.存在性判断:key 和 effect 必须同时匹配,value 可以是空
在 pod 上定义的容忍度可能不止一个,在节点上定义的污点可能多个,需要琢个检查容忍度和污点能否匹配,每一个污点都能被容忍,才能完成调度
1 2 3 4 5 6 7 8 9 10 11 12 [root@master1 ~]# kubectl describe nodes master1 | grep Taints Taints: node-role.kubernetes.io/master:NoSchedule # 可以看到 master 这个节点的污点是 Noschedule # 所以创建的 pod 都不会调度到 master 上,因为创建的 pod 没有容忍度 [root@master1 ~]# kubectl describe pods kube-apiserver-master1 -n kube-system Node-Selectors: <none> Tolerations: :NoExecute op=Exists Events: <none> # 可以看到这个 pod 的容忍度是 NoExecute,则可以调度到 master1 上
给node2打污点,pod如果不能容忍就不会调度过来
1 [root@master1 ~]# kubectl taint node node2 node-type=production:NoSchedule
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 apiVersion: v1 kind: Pod metadata: name: tomcat namespace: default labels: app: tomcat spec: containers: - name: tomcat image: tomcat imagePullPolicy: IfNotPresent ports: - containerPort: 8080 [root@master1 ~ ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES tomcat 1 /1 Running 0 6s 10.244 .166 .154 node1 <none> <none>
1 2 3 4 5 6 7 [root@master1 ~]# kubectl taint node node1 node-type=dev:NoExecute [root@master1 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE tomcat 0/1 Terminating 0 3m9s # 上面可以看到已经存在的 pod 节点都被撵走了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 apiVersion: v1 kind: Pod metadata: name: tomcat namespace: default labels: app: tomcat spec: containers: - name: tomcat image: tomcat imagePullPolicy: IfNotPresent ports: - containerPort: 8080 tolerations: - key: "node-type" operator: "Equal" value: "production" effect: "NoExecute" tolerationSeconds: 3600 [root@master1 ~ ] NAME READY STATUS RESTARTS AGE tomcat 0 /1 Pending 0 15s [root@master1 ~ ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES tomcat 1 /1 Running 0 5s 10.244 .104 .21 node2 <none> <none>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 tolerations: - key: "node-type" operator: "Exists" value: "" effect: "NoSchedule" [root@master1 ~ ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES tomcat 1 /1 Running 0 11s 10.244 .104 .22 node2 <none> <none> tolerations: - key: "node-type" operator: "Exists" value: "" effect: "" [root@master1 ~ ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES tomcat 1 /1 Running 0 12s 10.244 .166 .155 node1 <none> <none>
1 2 3 [root@master1 ~]# kubectl taint node node1 node-type:NoExecute- [root@master1 ~]# kubectl taint node node2 node-type-
Pod常见的状态和重启策略 常见的Pod状态
Pod 的 status 定义在 PodStatus 对象中,其中有一个 phase 字段。它简单描述了 Pod 在其生命周期的阶段。熟悉 Pod 的各种状态对我们理解如何设置 Pod 的调度策略、重启策略是很有必要的。下面是 phase 可能的值,也就是 pod 常见的状态:
挂起(Pending)
我们在请求创建 pod 时,条件不满足,调度没有完成,没有任何一个节点能满足调度条件,已经创建了 pod 但是没有适合它运行的节点叫做挂起,调度没有完成,处于 pending的状态会持续一段时间:包括调度 Pod 的时间和通过网络下载镜像的时间。
运行中(Running)
Pod 已经绑定到了一个节点上,Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态。
成功(Succeeded)
Pod 中的所有容器都被成功终止,并且不会再重启。
失败(Failed)
Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非 0 状态退出或者被系统终止。
未知(Unknown)
未知状态,所谓 pod 是什么状态是 apiserver 和运行在 pod 节点的 kubelet 进行通信获取状态信息的,如果节点之上的 kubelet 本身出故障,那么 apiserver 就连不上kubelet,得不到信息了,就会看 Unknown
Evicted 状态
出现这种情况,多见于系统内存或硬盘资源不足,可 df-h 查看 docker 存储所在目录的资源使用情况,如果百分比大于 85%,就要及时清理下资源,尤其是一些大文件、docker 镜像。
CrashLoopBackOff
容器曾经启动了,但可能又异常退出了
Error 状态
Pod 启动过程中发生了错误
Pod重启策略
Pod 的重启策略(RestartPolicy)应用于 Pod 内的所有容器,并且仅在 Pod 所处的 Node 上由kubelet 进行判断和重启操作。当某个容器异常退出或者健康检查失败时,kubelet 将根据RestartPolicy 的设置来进行相应的操作。
Pod 的重启策略包括 Always、OnFailure 和 Never,默认值为 Always。
Always:当容器失败时,由 kubelet 自动重启该容器。
OnFailure:当容器终止运行且退出码不为 0 时,由 kubelet 自动重启该容器。
Never:不论容器运行状态如何,kubelet 都不会重启该容器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 apiVersion: v1 kind: Pod metadata: name: tomcat namespace: default labels: app: tomcat spec: restartPolicy: Always containers: - name: tomcat image: tomcat imagePullPolicy: IfNotPresent ports: - containerPort: 8080
Pod生命周期
Init容器
Pod 里面可以有一个或者多个容器,部署应用的容器可以称为主容器,在创建 Pod 时候,Pod 中可以有一个或多个先于主容器启动的 Init 容器,这个 init 容器就可以成为初始化容器,初始化容器一旦执行完,它从启动开始到初始化代码执行完就退出了,它不会一直存在,所以在主容器启动之前执行初始化,初始化容器可以有多个,多个初始化容器是要串行执行的,先执行初始化容器 1,在执行初始化容器 2 等,等初始化容器执行完初始化就退出了,然后再执行主容器,主容器一退出,pod 就结束了,主容器退出的时间点就是 pod 的结束点,它俩时间轴是一致的;
Init 容器就是做初始化工作的容器。可以有一个或多个,如果多个按照定义的顺序依次执行,只有所有的初始化容器执行完后,主容器才启动。由于一个 Pod 里的存储卷是共享的,所以 Init Container 里产生的数据可以被主容器使用到,Init Container 可以在多种 K8S 资源里被使用到,如 Deployment、DaemonSet, StatefulSet、Job 等,但都是在 Pod 启动时,在主容器启动前执行,做初始化工作。
Init 容器与普通的容器区别
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 [root@master1 ~ ] apiVersion: v1 kind: Pod metadata: name: myapp-pod labels: app: myapp spec: containers: - name: myapp-container image: busybox:1.28 command: ["sh" ,"-c" ,"echo The app is running! && sleep 3600" ] initContainers: - name: init-myservice image: busybox:1.28 command: ["sh" ,"-c" ,"until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done" ] - name: init-myweb image: busybox:1.28 command: ['sh' ,'-c' ,"until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for mydb; sleep 2; done" ] [root@master1 ~ ] NAME READY STATUS RESTARTS AGE myapp-pod 0 /1 Init:0/2 0 3s [root@master1 ~ ] apiVersion: v1 kind: Service metadata: name: myservice spec: ports: - protocol: TCP port: 80 targetPort: 9376 --- apiVersion: v1 kind: Service metadata: name: mydb spec: ports: - protocol: TCP port: 80 targetPort: 9377 [root@master1 ~ ] NAME READY STATUS RESTARTS AGE myapp-pod 1 /1 Running 0 4s
主容器
容器钩子
初始化容器启动之后,开始启动主容器,在主容器启动之前有一个 post start hook(容器启动后钩子)和 pre stop hook(容器结束前钩子),无论启动后还是结束前所做的事我们可以把它放两个钩子,这个钩子就表示用户可以用它来钩住一些命令,来执行它,做开场前的预设,结束前的清理,如 awk 有 begin,end,和这个效果类似;
postStart
该钩子在容器被创建后立刻触发,通知容器它已经被创建。如果该钩子对应的 hook handler 执行失败,则该容器会被杀死,并根据该容器的重启策略决定是否要重启该容器,这个钩子不需要传递任何参数。
preStop
该钩子在容器被删除前触发,其所对应的 hook handler 必须在删除该容器的请求发送给 Docker daemon 之前完成。在该钩子对应的 hook handler 完成后不论执行的结果如何,Docker daemon 会发送一个 SGTERN 信号量给 Docker daemon 来删除该容器,这个钩子不需要传递任何参数。
在 k8s 中支持两类对 pod 的检测
第一类叫做 livenessprobe(pod 存活性探测):存活探针主要作用是,用指定的方式检测 pod 中的容器应用是否正常运行,如果检测失败,则认为容器不健康,那么 Kubelet 将根据 Pod 中设置的 restartPolicy 来判断 Pod 是否要进行重启操作,如果容器配置中没有配置 livenessProbe,Kubelet 将认为存活探针探测一直为成功状态。
第二类是状态检 readinessprobe(pod 就绪性探测):用于判断容器中应用是否启动完成,当探测成功后才使 Pod 对外提供网络访问,设置容器 Ready 状态为 true,如果探测失败,则设置容器的Ready 状态为 false。
创建 pod 需要经过的阶段
当用户创建 pod 时,这个请求给 apiserver,apiserver 把创建请求的状态保存在 etcd 中;
接下来 apiserver 会请求 scheduler 来完成调度,如果调度成功,会把调度的结果(如调度到哪个节点上了,运行在哪个节点上了,把它更新到 etcd 的 pod 资源状态中)保存在 etcd 中
一旦存到 etcd 中并且完成更新以后,如调度到 node1 上,那么 node1 节点上的 kubelet 通过 apiserver 当中的状态变化知道有一些任务被执行了,所以此时此 kubelet 会拿到用户创建时所提交的清单,这个清单会在当前节点上运行或者启动这个 pod
如果创建成功或者失败会有一个当前状态,当前这个状态会发给 apiserver,apiserver 在存到 etcd 中;在这个过程中,etcd 和 apiserver 一直在打交道,不停的交互,scheduler 也参与其中,负责调度 pod 到合适的 node 节点上,这个就是 pod 的创建过程
pod 在整个生命周期中有非常多的用户行为
初始化容器完成初始化
主容器启动后可以做启动后钩子
主容器结束前可以做结束前钩子
在主容器运行中可以做一些健康检测,如 liveness probe,readness probe
Pod容器探测和钩子 容器钩子
postStart:容器创建成功后,运行前的任务,用于资源部署、环境准备等
preStop:容器被终止前的任务,用于优雅关闭应用程序、通知其他系统等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 ······ containers: - image: sample:v2 name: war lifecycle: postStart: exec: command: - "cp" - "/sample.war" - "/app" preStop: http: host: monitor.com path: /waring port: 8080 scheme: HTTP ······
当用户请求删除含有 pod 的资源对象时(如 RC、deployment 等),K8S 为了让应用程序优雅关闭(即让应用程序完成正在处理的请求后,再关闭软件),K8S 提供两种信息通知:
1)、默认:K8S 通知 node 执行 docker stop 命令,docker 会先向容器中 PID 为 1 的进程发送系统信号 SIGTERM,然后等待容器中的应用程序终止执行,如果等待时间达到设定的超时时间,或者默认超时时间(30s),会继续发送 SIGKILL 的系统信号强行 kill 掉进程。
2)、使用 pod 生命周期(利用 PreStop 回调函数),它执行在发送终止信号之前。默认情况下,所有的删除操作的优雅退出时间都在 30 秒以内。kubectl delete 命令支持–grace-period=的选项,以运行用户来修改默认值。0 表示删除立即执行,并且立即从 API 中删除 pod。在节点上,被设置了立即结束的的 pod,仍然会给一个很短的优雅退出时间段,才会开始被强制杀死。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ······ spec: containers: - name: nginx image: centos:nginx ports: - name: http containerPort: 80 lifecycle: preStop: exec: command: ["/usr/local/nginx/sbin/nginx" ,"-s" ,"quit" ] ······
存活性探测和就绪性探测
livenessProbe:存活性探测
许多应用程序经过长时间运行,最终过渡到无法运行的状态,除了重启,无法恢复。通常情况下,K8S 会发现应用程序已经终止,然后重启应用程序 pod。有时应用程序可能因为某些原因(后端服务故障等)导致暂时无法对外提供服务,但应用软件没有终止,导致 K8S 无法隔离有故障的pod,调用者可能会访问到有故障的 pod,导致业务不稳定。K8S 提供 livenessProbe 来检测容器是否正常运行,并且对相应状况进行相应的补救措施。
readinessProbe:就绪性探测
在没有配置 readinessProbe 的资源对象中,pod 中的容器启动完成后,就认为 pod 中的应用程序可以对外提供服务,该 pod 就会加入相对应的 service,对外提供服务。但有时一些应用程序启动后,需要较长时间的加载才能对外服务,如果这时对外提供服务,执行结果必然无法达到预期效果,影响用户体验。比如使用 tomcat 的应用程序来说,并不是简单地说 tomcat 启动成功就可以对外提供服务的,还需要等待 spring 容器初始化,数据库连接上等等。
LivenessProbe 和 ReadinessProbe 两种探针都支持下面三种探测方法
ExecAction
在容器中执行指定的命令,如果执行成功,退出码为 0 则探测成功。
TCPSocketAction
通过容器的 IP 地址和端口号执行 TCP 检查,如果能够建立 TCP 连接,则表明容器健康。
HTTPGetAction
通过容器的 IP 地址、端口号及路径调用 HTTP Get 方法,如果响应的状态码大于等于 200 且小于 400,则认为容器健康
探针探测结果有以下值
Success:表示通过检测。Failure:表示未通过检测。Unknown:表示检测没有正常进行。
Pod 探针相关的属性:
initialDelaySeconds
Pod 启动后首次进行检查的等待时间,单位“秒”。
periodSeconds
检查的间隔时间,默认为 10s,单位“秒”。
timeoutSeconds
探针执行检测请求后,等待响应的超时时间,默认为 1s,单位“秒”。
successThreshold
连续探测几次成功,才认为探测成功,默认为 1,在 Liveness 探针中必须为 1,最小值为 1。
failureThreshold
探测失败的重试次数,重试一定次数后将认为失败,在 readiness 探针中,Pod 会被标记为未就绪,默认为 3,最小值为 1
两种探针区别
ReadinessProbe 和 livenessProbe 可以使用相同探测方式,只是对 Pod 的处置方式不同
Pod探针使用
通过 exec 方式做健康探测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 apiVersion: v1 kind: Pod metadata: name: liveness-exec labels: app: liveness spec: containers: - name: liveness image: busybox args: - /bin/sh - -c - touch /tmp/healthy; sleep 30 ; rm -rf /tmp/healthy; sleep 600 livenessProbe: initialDelaySeconds: 10 periodSeconds: 5 exec: command: - cat - /tmp/healthy /bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
通过 HTTP 方式做健康检测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 apiVersion: v1 kind: Pod metadata: name: liveness-http labels: test: liveness spec: containers: - name: liveness image: mydlqclub/springboot-helloworld:0.0.1 livenessProbe: initialDelaySeconds: 20 periodSeconds: 5 timeoutSeconds: 10 httpGet: scheme: HTTP port: 8081 path: /actuator/health scheme: 用于连接 host 的协议,默认为 HTTP。 host: 要连接的主机名,默认为 Pod IP,可以在 http request head 中设置 host 头部。 port: 容器上要访问端口号或名称。 path: http 服务器上的访问 URI。 httpHeaders: 自定义 HTTP 请求 headers,HTTP 允许重复 headers。
通过TCP方式做健康检测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 apiVersion: v1 kind: Pod metadata: name: liveness-tcp labels: app: liveness spec: containers: - name: liveness image: nginx livenessProbe: initialDelaySeconds: 15 periodSeconds: 20 tcpSocket: port: 80
Pod 的 ReadinessProbe 探针使用方式和 LivenessProbe 探针探测方法一样,也是支持三种。只是一个是用于探测应用的存活,一个是判断是否对外提供流量的条件。
这里用一个 Springboot项目,设置 ReadinessProbe 探测 SpringBoot 项目的 8081 端口下的 /actuator/health 接口,如果探测成功则代表内部程序以及启动,就开放对外提供接口访问,否则内部应用没有成功启动,暂不对外提供访问,直到就绪探针探测成功。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 apiVersion: v1 kind: Service metadata: name: springboot labels: app: springboot spec: type: NodePort ports: - name: server port: 8080 targetPort: 8080 nodePort: 31180 - name: management port: 8081 targetPort: 8081 nodePort: 31181 selector: app: springboot --- apiVersion: v1 kind: Pod metadata: name: springboot labels: app: springboot spec: containers: - name: springboot image: mydlqclub/springboot-helloworld:0.0.1 ports: - name: server containerPort: 8080 - name: management containerPort: 8081 readinessProbe: initialDelaySeconds: 20 periodSeconds: 5 timeoutSeconds: 10 httpGet: scheme: HTTP port: 8081 path: /actuator/health
ReadinessProbe + LivenessProbe 配合使用示例
一般程序中需要设置两种探针结合使用,并且也要结合实际情况,来配置初始化检查时间和检测间隔,下面列一个简单的 SpringBoot 项目的 Deployment 例子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 --- apiVersion: v1 kind: Service metadata: name: springboot labels: app: springboot spec: type: NodePort selector: app: springboot ports: - name: server port: 8080 targetPort: 8080 nodePort: 31180 - name: management port: 8081 targetPort: 8081 nodePort: 31181 --- apiVersion: apps/v1 kind: Deployment metadata: name: springboot labels: app: springboot spec: replicas: 1 selector: matchLabels: app: springboot template: metadata: labels: name: springboot app: springboot spec: containers: - name: readiness image: mydlqclub/springboot-helloworld:0.0.1 ports: - name: server containerPort: 8080 - name: management containerPort: 8081 readinessProbe: initialDelaySeconds: 20 periodSeconds: 5 timeoutSeconds: 10 httpGet: scheme: HTTP port: 8081 path: /actuator/health livenessProbe: initialDelaySeconds: 30 periodSeconds: 10 timeoutSeconds: 5 httpGet: scheme: HTTP port: 8081 path: /actuator/health
启动探测
livenessProbe:用于探测容器是否运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其重启策略的影响决定是否重启。如果容器不提供存活探针,则默认状态为 Success。
readinessProbe:一般用于探测容器内的程序是否健康,容器是否准备好服务请求。如果就绪探测失败,endpoint 将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为 Failure。如果容器不提供就绪探针,则默认状态为 Success。
startupProbe: 探测容器中的应用是否已经启动。如果提供了启动探测(startup probe),则禁用所有其他探测,直到它成功为止。如果启动探测失败,kubelet 将杀死容器,容器服从其重启策略进行重启。如果容器没有提供启动探测,则默认状态为成功 Success。
在 k8s 中,通过控制器管理 pod,如果更新 pod 的时候,会创建新的 pod,删除老的 pod,但是如果新的 pod 创建了,pod 里的容器还没完成初始化,老的 pod 就被删除了,会导致访问 service 或者ingress 时候,访问到的 pod 是有问题的,所以 k8s 就加入了一些存活性探针:livenessProbe、就绪性探针 readinessProbe 以及启动探针 startupProbe。
正常情况下,在 pod template 中配置 livenessProbe 来探测容器是否正常运行,如果异常则会触发restartPolicy 重启容器(默认情况下 restartPolicy 设置的是 always)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 livenessProbe: httpGet: path: /test port: 80 failureThreshold: 1 initialDelay: 10 periodSeconds: 10 livenessProbe: httpGet: path: /test prot: 80 failureThreshold: 5 initialDelay: 60 periodSeconds: 10 livenessProbe: httpGet: path: /test prot: 80 failureThreshold: 1 initialDelay: 10 periodSeconds: 10 startupProbe: httpGet: path: /test prot: 80 failureThreshold: 10 initialDelay: 10 periodSeconds: 10
K8s 的 LivenessProbe 和 ReadinessProbe 的启动顺序问题
LivenessProbe 会导致 pod 重启,ReadinessProbe 只是不提供服务
我们最初的理解是 LivenessProbe 会在 ReadinessProbe 成功后开始检查,但事实并非如此。
kubelet 使用存活探测器来知道什么时候要重启容器。 例如,存活探测器可以捕捉到死锁(应用程序在运行,但是无法继续执行后面的步骤)。 这样的情况下重启容器有助于让应用程序在有问题的情况下可用。
kubelet 使用就绪探测器可以知道容器什么时候准备好了并可以开始接受请求流量, 当一个 Pod 内的所有容器都准备好了,才能把这个 Pod 看作就绪了。 这种信号的一个用途就是控制哪个 Pod 作为Service 的后端。 在 Pod 还没有准备好的时候,会从 Service 的负载均衡器中被剔除的。
kubelet 使用启动探测器(startupProbe)可以知道应用程序容器什么时候启动了。 如果配置了这类探测器,就可以控制容器在启动成功后再进行存活性和就绪检查, 确保这些存活、就绪探测器不会影响应用程序的启动。 这可以用于对慢启动容器进行存活性检测,避免它们在启动运行之前就被杀掉。
真正的启动顺序:https://github.com/kubernetes/kubernetes/issues/60647 https://github.com/kubernetes/kubernetes/issues/27114 https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/#define-readiness-probes
官方文档:Caution: Liveness probes do not wait for readiness probes to succeed. If you want to wait before executing a liveness probe you should use initialDelaySeconds or a startupProbe.
也就是 Liveness probes 并不会等到 Readiness probes 成功之后才运行
根据上面的官方文档,Liveness 和 readiness 应该是某种并发的关系
k8s 控制器:Replicaset
在定义 pod 资源时,可以直接创建一个 kind:Pod 类型的自主式 pod,但是这存在一个问题,假如 pod 被删除了,那这个 pod 就不能自我恢复,就会彻底被删除,线上这种情况非常危险
所以就要用到 pod 的控制器,所谓控制器就是能够管理 pod,监测 pod 运行状况,当 pod 发生故障,可以自动恢复 pod。也就是说能够代我们去管理 pod 中间层,并帮助我们确保每一个 pod 资源始终处于我们所定义或者我们所期望的目标状态,一旦 pod 资源出现故障,那么控制器会尝试重启 pod 或者里面的容器,如果一直重启有问题的话那么它可能会基于某种策略来进行重新布派或者重新编排;如果 pod 副本数量低于用户所定义的目标数量,它也会自动补全;如果多余,也会自动终止pod 资源。
Replicaset 概述
ReplicaSet 是 kubernetes 中的一种副本控制器,简称 rs,主要作用是控制由其管理的 pod,使 pod 副本的数量始终维持在预设的个数。它的主要作用就是保证一定数量的 Pod 能够在集群中正常运行,它会持续监听这些 Pod 的运行状态,在 Pod 发生故障时重启 pod,pod 数量减少时重新运行新的 Pod 副本。
官方推荐不要直接使用 ReplicaSet,用 Deployment 取而代之,Deployment 是比 ReplicaSet 更高级的概念,它会管理 ReplicaSet 并提供很多其它有用的特性,最重要的是 Deployment 支持声明式更新,声明式更新的好处是不会丢失历史变更。所以 Deployment 控制器不直接管理 Pod 对象,而是由 Deployment 管理 ReplicaSet,再由 ReplicaSet 负责管理 Pod 对象。
Replicaset 工作原理
Replicaset 核心作用在于代用户创建指定数量的 pod 副本,并确保 pod 副本一直处于满足用户期望的数量, 起到多退少补的作用,并且还具有自动扩容缩容等机制。
Replicaset 控制器主要由三个部分组成:
用户期望的 pod 副本数:用来定义由这个控制器管控的 pod 副本有几个
标签选择器:选定哪些 pod 是自己管理的,如果通过标签选择器选到的 pod 副本数量少于我们指定的数量,需要用到下面的组件
pod 资源模板:如果集群中现存的 pod 数量不够我们定义的副本中期望的数量怎么办,需要新建 pod,这就需要 pod 模板,新建的 pod 是基于模板来创建的。
Replicaset 资源清单文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@master1 ~]# kubectl explain rs KIND: ReplicaSet VERSION: apps/v1 DESCRIPTION: ReplicaSet ensures that a specified number of pod replicas are running at any given time. FIELDS: apiVersion <string> # 当前资源使用的api版本 kind <string> # 资源类型 metadata <Object> # 元数据 spec <Object> # 定义副本数、定义标签选择器、定义Pod模板 status <Object> # 状态信息,不能改
1 2 3 4 5 6 7 8 9 10 [root@master1 ~]# kubectl explain rs.spec KIND: ReplicaSet VERSION: apps/v1 RESOURCE: spec <Object> FIELDS: minReadySeconds <integer> replicas <integer> # 定义pod副本数 selector <Object> -required- # 用于匹配pod的标签选择器 template <Object> # 定义Pod模板
1 2 3 4 5 6 7 8 [root@master1 ~]# kubectl explain rs.spec.template KIND: ReplicaSet VERSION: apps/v1 RESOURCE: template <Object> FIELDS: metadata <Object> spec <Object>
通过上面可以看到,ReplicaSet 资源中有两个 spec 字段。第一个 spec 声明的是 ReplicaSet 定义多少个 Pod 副本(默认将仅部署 1 个 Pod)、匹配 Pod 标签的选择器、创建 pod 的模板。第二个 spec 是 spec.template.spec:主要用于 Pod 里的容器属性等配置。
.spec.template 里的内容是声明 Pod 对象时要定义的各种属性,所以这部分也叫做 PodTemplate(Pod 模板)。还有一个值得注意的地方是:在.spec.selector 中定义的标签选择器必须能够匹配到 spec.template.metadata.labels 里定义的 Pod 标签,否则 Kubernetes 将不允许创建 ReplicaSet。
Replicaset 使用案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 apiVersion: apps/v1 kind: ReplicaSet metadata: name: frontend labels: app: guestbook tier: frontend spec: replicas: 3 selector: matchLabels: tier: frontend template: metadata: labels: tier: frontend spec: containers: - name: php-redis image: yecc/gcr.io-google_samples-gb-frontend:v3 imagePullPolicy: IfNotPresent ports: - name: http containerPort: 80 [root@master1 ~ ] NAME DESIRED CURRENT READY AGE frontend 3 3 3 31s [root@master1 ~ ] NAME READY STATUS RESTARTS AGE frontend-57g5j 1 /1 Running 0 41s frontend-6zgqn 1 /1 Running 0 41s frontend-tw2ld 1 /1 Running 0 41s
ReplicaSet 最核心的功能是可以动态扩容和回缩,如果我们觉得两个副本太少了,想要增加,只需要修改配置文件 replicaset.yaml 里的 replicas 的值即可,原来 replicas: 3,现在变成 replicaset: 4,修改之后更新
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 [root@master1 ~]# kubectl get rs NAME DESIRED CURRENT READY AGE frontend 4 4 4 8m17s [root@master1 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE frontend-57g5j 1/1 Running 0 8m3s frontend-6zgqn 1/1 Running 0 8m3s frontend-tgmxk 1/1 Running 0 2s frontend-tw2ld 1/1 Running 0 8m3s # 也可以直接编辑控制器实现扩容 # 把请求提交给了 apiserver,实时修改 [root@master1 ~]# kubectl edit rs frontend # 把上面的 spec 下的 replicas 后面的值改成 5,保存退出 [root@master1 ~]# kubectl get rs NAME DESIRED CURRENT READY AGE frontend 5 5 5 30m [root@master1 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE frontend-57g5j 1/1 Running 0 30m frontend-6zgqn 1/1 Running 0 30m frontend-rf7gd 1/1 Running 0 25s frontend-tgmxk 1/1 Running 0 22m frontend-tw2ld 1/1 Running 0 30m # 如果觉得 5 个 Pod 副本太多了,想要减少,只需要修改配置文件里的 replicas 的值即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 [root@master1 ~]# kubectl edit rs frontend # 修改镜像 image: yecc/gcr.io-google_samples-gb-frontend:v3 变成 image: ikubernetes/myapp:v2,修改之后保存退出 [root@master1 ~]# kubectl get rs -o wide NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR frontend 5 5 5 34m php-redis ikubernetes/myapp:v2 # 上面可以看到镜像变成了 ikubernetes/myapp:v2,说明滚动升级成功了 [root@master1 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES frontend-57g5j 1/1 Running 0 37m 10.244.104.24 node2 <none> <none> [root@master1 ~]# curl 10.244.104.24 <h2>Guestbook</h2> # 上面可以看到虽然镜像已经更新了,但是原来的 pod 使用的还是之前的镜像,新创建的 pod 才会使用最新的镜像 # 删除 10.244.104.24 ip对应的pod [root@master1 ~]# kubectl delete pods frontend-57g5j [root@master1 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES frontend-5b49g 1/1 Running 0 12s 10.244.166.170 node1 [root@master1 ~]# curl 10.244.166.170 Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a> # 新生成的 pod 的镜像已经变成了 myapp 的,说明更新完成了
如果直接修改 replicaset.yaml 文件,把 image: yecc/gcr.io-google_samples-gb-frontend:v3 变成- image: ikubernetes/myapp:v2
生产环境如果升级,可以删除一个 pod,观察一段时间之后没问题再删除另一个 pod,但是这样需要人工干预多次;实际生产环境一般采用蓝绿发布,原来有一个 rs1,再创建一个 rs2(控制器),通过修改 service 标签,修改 service 可以匹配到 rs2 的控制器,这样才是蓝绿发布,这个也需要我们精心的部署规划,我们有一个控制器就是建立在 rs 之上完成的,叫做 Deployment
k8s 控制器:Deployment
Deployment 是 kubernetes 中最常用的资源对象,为 ReplicaSet 和 Pod 的创建提供了一种声明式的定义方法,在 Deployment 对象中描述一个期望的状态,Deployment 控制器就会按照一定的控制速率把实际状态改成期望状态,通过定义一个 Deployment 控制器会创建一个新的 ReplicaSet 控制器,通过 ReplicaSet 创建 pod,删除 Deployment 控制器,也会删除 Deployment 控制器下对应的 ReplicaSet 控制器和 pod 资源。
使用 Deployment 而不直接创建 ReplicaSet 是因为 Deployment 对象拥有许多 ReplicaSet 没有的特性,例如滚动升级和回滚。
扩展:声明式定义是指直接修改资源清单 yaml 文件,然后通过 kubectl apply -f 资源清单 yaml 文件,就可以更改资源
Deployment 控制器是建立在 rs 之上的一个控制器,可以管理多个 rs,每次更新镜像版本,都会生成一个新的 rs,把旧的 rs 替换掉,多个 rs 同时存在,但是只有一个 rs 运行。
rs v1 控制三个 pod,删除一个 pod,在 rs v2 上重新建立一个,依次类推,直到全部都是由 rs v2控制,如果 rs v2 有问题,还可以回滚,Deployment 是建构在 rs 之上的,多个 rs 组成一个Deployment,但是只有一个 rs 处于活跃状态。
Deployment 工作原理
Deployment 可以使用声明式定义,直接在命令行通过纯命令的方式完成对应资源版本的内容的修改,也就是通过打补丁的方式进行修改;Deployment 能提供滚动式自定义自控制的更新;对 Deployment来讲,在实现更新时还可以实现控制更新节奏和更新逻辑。
互动:什么叫做更新节奏和更新逻辑呢?
比如说 Deployment 控制 5 个 pod 副本,pod 的期望值是 5 个,但是升级的时候需要额外多几个pod,那我们控制器可以控制在 5 个 pod 副本之外还能再增加几个 pod 副本;比方说能多一个,但是不能少,那么升级的时候就是先增加一个,再删除一个,增加一个删除一个,始终保持 pod 副本数是 5 个;还有一种情况,最多允许多一个,最少允许少一个,也就是最多 6 个,最少 4 个,第一次加一个,删除两个,第二次加两个,删除两个,依次类推,可以自己控制更新方式,这种滚动更新需要加 readinessProbe 和 livenessProbe 探测,确保 pod 中容器里的应用都正常启动了才删除之前的 pod。
启动第一步,刚更新第一批就暂停了也可以;假如目标是 5 个,允许一个也不能少,允许最多可以10 个,那一次加 5 个即可;这就是我们可以自己控制节奏来控制更新的方法。
通过 Deployment 对象,可以轻松的做到以下事情:
创建 ReplicaSet 和 Pod
滚动升级(不停止旧服务的状态下升级)和回滚应用(将应用回滚到之前的版本)
平滑地扩容和缩容
暂停和继续 Deployment
Deployment 资源清单文件
1 2 3 4 5 6 7 8 9 10 11 [root@master1 ~]# kubectl explain deployment KIND: Deployment VERSION: apps/v1 DESCRIPTION: FIELDS: apiVersion <string> kind <string> metadata <Object> spec <Object> status <Object>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 [root@master1 ~]# kubectl explain deployment.spec KIND: Deployment VERSION: apps/v1 RESOURCE: spec <Object> DESCRIPTION: FIELDS: minReadySeconds <integer> # Kubernetes 在等待设置的时间后才进行升级 # 如果没有设置该值,Kubernetes 会假设该容器启动起来后就提供服务了 paused <boolean> # 暂停,当我们更新的时候创建 pod 先暂停,不是立即更新 progressDeadlineSeconds <integer> # k8s 在升级过程中有可能由于各种原因升级卡住(这个时候还没有明确的升级失败) # 比如在拉取被墙的镜像,权限不够等错误。那么这个时候就需要有个 deadline ,在 deadline 之内如果还卡着,那么就上报这个情况 # 这个时候这个 Deployment 状态就被标记为 False,并且注明原因。 # 但是它并不会阻止 Deployment 继续进行卡住后面的操作。完全由用户进行控制。 replicas <integer> # 副本数 revisionHistoryLimit <integer> # 保留的历史版本,默认是10 selector <Object> -required- # 标签选择器,选择它关联的pod strategy <Object> # 更新策略 template <Object> -required- # 定义 pod 模板
查看deployment.spec.strategy字段
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@master1 ~]# kubectl explain deployment.spec.strategy KIND: Deployment VERSION: apps/v1 RESOURCE: strategy <Object> FIELDS: rollingUpdate <Object> type <string> Type of deployment. Can be "Recreate" or "RollingUpdate". Default is RollingUpdate. # 支持两种更新,Recreate 和 RollingUpdate # Recreate 是重建式更新,删除一个更新一个 # RollingUpdate 滚动更新,定义滚动更新方式,也就是 pod 能多几个,少几个
查看deployment.spec.strategy.rollingUpdate字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@master1 ~]# kubectl explain deployment.spec.strategy.rollingUpdate KIND: Deployment VERSION: apps/v1 RESOURCE: rollingUpdate <Object> FIELDS: maxSurge <string> # 更新的过程当中最多允许超出的指定的目标副本数有几个; # 它有两种取值方式,第一种直接给定数量, # 第二种根据百分比,百分比表示原本是 5 个,最多可以超出 20%,那就允许多一个,最多可以超过 40%,那就允许多两个 maxUnavailable <string> # 最多允许几个不可用 # 假设有 5 个副本,最多一个不可用,就表示最少有 4 个可用
1 2 3 4 5 6 7 8 9 10 11 12 [root@master1 ~]# kubectl explain deployment.spec.template KIND: Deployment VERSION: apps/v1 RESOURCE: template <Object> DESCRIPTION: FIELDS: metadata <Object> # 定义模板的名字 spec <Object> # deployment.spec.template 为 Pod 定义的模板,和 Pod 定义不太一样 # template 中不包含apiVersion 和 Kind 属性,要求必须有 metadata。 # deployment.spec.template.spec 为容器的属性信息,其他定义内容和 Pod 一致。
查看deploy.spec.template.spec字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 [root@master1 ~]# kubectl explain deployment.spec.template.spec KIND: Deployment VERSION: apps/v1 RESOURCE: spec <Object> FIELDS: activeDeadlineSeconds <integer> # 表示 pod 可以运行的最长时间,达到设置的值后,pod会自动停止 affinity <Object> # 定义亲和性,跟直接创建pod时候定义的亲和性类似 automountServiceAccountToken <boolean> # 身份认证相关的 containers <[]Object> -required- # 定义容器属性 dnsConfig <Object> # 设置pod的DNS (写入 pod 的 /etc/resolv.conf 需要与 dnsPolicy字段连用) dnsConfig: nameservers: - 192.xxx.xxx.6 searches: - xianchao.svc.cluster.local - my.dns.search.xianchao dnsPolicy <string> # 决定pod内预设的DNS配置策略 # None 无任何策略:使用自定义的策略 # Default 默认:使用宿主机的 dns 配置,/etc/resolv.conf # ClusterFirst 集群 DNS 优先,与 Default 相反,会预先使用 kube-dns (或 CoreDNS ) 的信息当预设置参数写入到该 Pod 内的 DNS 配置。 # ClusterFirstWithHostNet 集群 DNS 优先,并伴随着使用宿主机网络:同时使用 hostNetwork 与 kube-dns 作为 Pod 预设 DNS 配置。 enableServiceLinks <boolean> ephemeralContainers <[]Object> # 定义临时容器 # 临时容器与其他容器的不同之处在于,它们缺少对资源或执行的保证,并且永远不会自动重启,因此不适用于构建应用程序。 # 临时容器使用与常规容器相同的 ContainerSpec 段进行描述,但许多字段是不相容且不允许的。 # 临时容器没有端口配置,因此像 ports,livenessProbe,readinessProbe 这样的字段是不允许的。 # Pod 资源分配是不可变的,因此 resources 配置是不允许的。 # 临时容器用途: # 当由于容器崩溃或容器镜像不包含调试应用程序而导致 kubectl exec 无用时,临时容器对于交互式故障排查很有用。 hostAliases <[]Object> # 在pod中增加域名解析的(写入 pod 中的 /etc/hosts) hostAliases - ip: "10.1.2.2" hostnames: - "mc.local" - "rabbitmq.local" - ip: "10.1.2.3" hostnames: - "redis.local" - "mq.local" hostIPC <boolean> # 使用主机IPC hostNetwork <boolean> # 是否使用宿主机的网络 hostPID <boolean> # 可以设置容器里是否可以看到宿主机上的进程 hostname <string> imagePullSecrets <[]Object> initContainers <[]Object> # 定义初始化容器 nodeName <string> # 定义pod调度到具体哪个节点上 nodeSelector <map[string]string> # 定义节点选择器 overhead <map[string]string> # overhead 是 1.16 引入的字段 # 在没有引入 Overhead 之前,只要一个节点的资源可用量大于等于 Pod 的 requests 时,这个 Pod 就可以被调度到这个节点上。 # 引入 Overhead 之后,只有节点的资源可用量大于等于 Overhead 加上 requests 的和时才能被调度上来。 preemptionPolicy <string> priority <integer> priorityClassName <string> readinessGates <[]Object> restartPolicy <string> # pod重启策略 runtimeClassName <string> schedulerName <string> securityContext <Object> # 是否开启特权模式 serviceAccount <string> serviceAccountName <string> setHostnameAsFQDN <boolean> shareProcessNamespace <boolean> subdomain <string> terminationGracePeriodSeconds <integer> # 在真正删除容器之前,K8S 会先发终止信号(kill -15 {pid})给容器,默认 30s tolerations <[]Object> # 定义容忍度 topologySpreadConstraints <[]Object> volumes <[]Object> # 挂载存储卷
Deployment案例
创建一个web站点
deployment 是一个三级结构,deployment 管理 replicaset,replicaset 管理 pod
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 apiVersion: apps/v1 kind: Deployment metadata: name: myapp-v1 spec: replicas: 2 selector: matchLabels: app: myapp version: v1 template: metadata: labels: app: myapp version: v1 spec: containers: - name: myapp image: janakiramm/myapp:v1 imagePullPolicy: IfNotPresent ports: - containerPort: 80 [root@master1 ~ ] NAME READY UP-TO-DATE AVAILABLE AGE myapp-v1 2 /2 2 2 72s [root@master1 ~ ] NAME DESIRED CURRENT READY AGE myapp-v1-67fd9fc9c8 2 2 2 3m9s [root@master1 ~ ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES myapp-v1-67fd9fc9c8-9ffjn 1 /1 Running 0 4m41s 10.244 .104 .2 node2 <none> <none> myapp-v1-67fd9fc9c8-qccls 1 /1 Running 0 4m41s 10.244 .166 .130 node1 <none> <none> [root@master1 ~ ] background-color: blue; [root@master1 ~ ] background-color: blue;
扩容、缩容、滚动更新、回滚
通过deployment管理应用,实现扩容,把副本数变成3
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@master1 ~]# vim deploy-demo.yaml # 直接修改 replicas 数量,如下,变成 3 spec: replicas: 3 [root@master1 ~]# kubectl apply -f deploy-demo.yaml # 注意:apply 不同于 create,apply 可以执行多次;create 执行一次,再执行就会报错复。 [root@master1 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE myapp-v1-67fd9fc9c8-9ffjn 1/1 Running 0 8m4s myapp-v1-67fd9fc9c8-qccls 1/1 Running 0 8m4s myapp-v1-67fd9fc9c8-w7khk 1/1 Running 0 2s
通过deployment管理应用,实现缩容,把副本数变成2
1 2 3 4 5 6 7 8 9 10 # 修改deploy清单文件,把副本数改为2 spec: replicas: 2 [root@master1 ~]# kubectl apply -f deploy-demo.yaml [root@master1 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE myapp-v1-67fd9fc9c8-9ffjn 1/1 Running 0 11m myapp-v1-67fd9fc9c8-qccls 1/1 Running 0 11m
通过deployment管理应用,实现滚动更新
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 # 在一个终端执行 [root@master1 ~]# kubectl get pods -l app=myapp -w NAME READY STATUS RESTARTS AGE myapp-v1-67fd9fc9c8-9ffjn 1/1 Running 0 13m myapp-v1-67fd9fc9c8-qccls 1/1 Running 0 13m # 打开一个新的终端窗口更改镜像版本 [root@master1 ~]# vim deploy-demo.yaml # 把janakiramm/myapp:v1变成janakiramm/myapp:v2 [root@master1 ~]# kubectl apply -f deploy-demo.yaml # 再回到刚才执行监测 kubectl get pods -l app=myapp -w 的那个窗口 [root@master1 ~]# kubectl get pods -l app=myapp -w NAME READY STATUS RESTARTS AGE myapp-v1-67fd9fc9c8-9ffjn 1/1 Running 0 13m myapp-v1-67fd9fc9c8-qccls 1/1 Running 0 13m myapp-v1-75fb478d6c-w99v2 0/1 Pending 0 0s myapp-v1-75fb478d6c-w99v2 0/1 Pending 0 0s myapp-v1-75fb478d6c-w99v2 0/1 ContainerCreating 0 0s myapp-v1-75fb478d6c-w99v2 0/1 ContainerCreating 0 0s myapp-v1-75fb478d6c-w99v2 1/1 Running 0 1s myapp-v1-67fd9fc9c8-qccls 1/1 Terminating 0 15m myapp-v1-75fb478d6c-jdrjj 0/1 Pending 0 0s myapp-v1-75fb478d6c-jdrjj 0/1 Pending 0 0s myapp-v1-75fb478d6c-jdrjj 0/1 ContainerCreating 0 0s myapp-v1-67fd9fc9c8-qccls 1/1 Terminating 0 15m myapp-v1-75fb478d6c-jdrjj 0/1 ContainerCreating 0 1s myapp-v1-67fd9fc9c8-qccls 0/1 Terminating 0 15m myapp-v1-75fb478d6c-jdrjj 1/1 Running 0 1s myapp-v1-67fd9fc9c8-9ffjn 1/1 Terminating 0 15m myapp-v1-67fd9fc9c8-9ffjn 1/1 Terminating 0 15m myapp-v1-67fd9fc9c8-9ffjn 0/1 Terminating 0 15m myapp-v1-67fd9fc9c8-9ffjn 0/1 Terminating 0 15m myapp-v1-67fd9fc9c8-9ffjn 0/1 Terminating 0 15m myapp-v1-67fd9fc9c8-qccls 0/1 Terminating 0 15m myapp-v1-67fd9fc9c8-qccls 0/1 Terminating 0 15m # pending 表示正在进行调度 # ContainerCreating 表示正在创建一个 pod # running 表示运行 # 一个 pod,running 起来一个 pod 之后再 Terminating(停掉)一个 pod,以此类推,直到所有 pod 完成滚动升级 # 在另外一个窗口执行 [root@master1 ~]# kubectl get rs NAME DESIRED CURRENT READY AGE myapp-v1-67fd9fc9c8 0 0 0 16m myapp-v1-75fb478d6c 2 2 2 76s # 上面可以看到 rs 有两个,上面那个是升级之前的,已经被停掉,但是可以随时回滚 # 查看 myapp-v1 这个控制器的历史版本 [root@master1 ~]# kubectl rollout history deployment myapp-v1 deployment.apps/myapp-v1 REVISION CHANGE-CAUSE 1 <none> 2 <none>
回滚
1 2 3 4 5 6 7 [root@master1 ~]# kubectl rollout undo deployment myapp-v1 --to-revision=1 [root@master1 ~]# kubectl rollout history deployment myapp-v1 deployment.apps/myapp-v1 REVISION CHANGE-CAUSE 2 <none> 3 <none>
自定义滚动更新策略
maxSurge 和 maxUnavailable 用来控制滚动更新的更新策略
取值范围 数值
maxUnavailable: [0, 副本数]maxSurge: [0, 副本数]注意:两者不能同时为 0。
比例
maxUnavailable: [0%, 100%] 向下取整
比如 10 个副本,5%的话==0.5 个,但计算按照 0 个
maxSurge: [0%, 100%] 向上取整
比如 10 个副本,5%的话==0.5 个,但计算按照 1 个
注意:两者不能同时为 0。
建议配置
总结
自定义策略
修改更新策略:maxUnavailable=1,maxSurge=1
1 2 3 4 5 6 7 8 9 10 11 12 [root@master1 ~]# kubectl patch deployments myapp-v1 -p '{"spec":{"strategy":{"rollingUpdate":{"maxSurge":1,"maxUnavailable":1}}}}' # 也可以写 yaml 文件,在 deploy.spec 下 strategy: rollingUpdate: maxSurge: 1 maxUnavailable: 1 # 查看 myapp-v1 这个控制器的详细信息 [root@master1 ~]# kubectl describe deployments myapp-v1 RollingUpdateStrategy: 1 max unavailable, 1 max surge
上面可以看到 RollingUpdateStrategy: 1 max unavailable, 1 max surge 这个 rollingUpdate 更新策略变成了刚才设定的,因为我们设定的 pod 副本数是 3,1 和 1 表示最少不能少于 2 个 pod,最多不能超过 4 个 pod 这个就是通过控制 RollingUpdateStrategy 这个字段来设置滚动更新策略的
k8s 四层负载均衡-service 概念、原理解读
在 kubernetes 中,Pod 是有生命周期的,如果 Pod 重启它的 IP 很有可能会发生变化。
如果我们的服务都是将 Pod 的 IP 地址写死,Pod 挂掉或者重启,和刚才重启的 pod 相关联的其他服务将会找不到它所关联的 Pod,为了解决这个问题,在 kubernetes 中定义了 service 资源对象,Service 定义了一个服务访问的入口,客户端通过这个入口即可访问服务背后的应用集群实例,service 是一组 Pod 的逻辑集合,这一组 Pod 能够被 Service 访问到,通常是通过 Label Selector 实现的。
pod ip 经常变化,service 是 pod 的代理,我们客户端访问,只需要访问 service,就会把请求代理到 Pod
pod ip 在 k8s 集群之外无法访问,所以需要创建 service,这个 service 可以在 k8s 集群外访问的。
service 是一个固定接入层,客户端可以通过访问 service 的 ip 和端口访问到 service 关联的后端pod,这个 service 工作依赖于在 kubernetes 集群之上部署的一个附件,就是 kubernetes 的 dns 服务(不同 kubernetes 版本的 dns 默认使用的也是不一样的,1.11 之前的版本使用的是 kubeDNS,较新的版本使用的是 coredns),service 的名称解析是依赖于 dns 附件的,因此在部署完 k8s 之后需要再部署 dns附件,kubernetes 要想给客户端提供网络功能,需要依赖第三方的网络插件(flannel,calico 等)。
每个 K8s 节点上都有一个组件叫做 kube-proxy,kube-proxy 这个组件将始终监视着 apiserver 中有关 service 资源的变动信息,需要跟 master 之上的 apiserver 交互,随时连接到 apiserver 上获取任何一个与 service 资源相关的资源变动状态,这种是通过 kubernetes 中固有的一种请求方法 watch(监视)来实现的,一旦有 service 资源的内容发生变动(如创建,删除),kube-proxy 都会将它转化成当前节点之上的能够实现 service 资源调度,把我们请求调度到后端特定的 pod 资源之上的规则,这个规则可能是 iptables,也可能是 ipvs,取决于 service 的实现方式。
k8s 在创建 Service 时,会根据标签选择器 selector(lable selector)来查找 Pod,据此创建与 Service 同名的 endpoint 对象,当 Pod 地址发生变化时,endpoint 也会随之发生变化,service 接收前端 client 请求的时候,就会通过 endpoint,找到转发到哪个 Pod 进行访问的地址。(至于转发到哪个节点的 Pod,由负载均衡 kube-proxy 决定)
Node Network(节点网络):物理节点或者虚拟节点的网络,如 ens32接口上的网络地址
1 2 3 4 [root@master1 ~]# ip addr 2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:73:1d:1f brd ff:ff:ff:ff:ff:ff inet 192.168.1.180/24 brd 192.168.1.255 scope global noprefixroute ens32
Pod Network(pod 网络):创建的 Pod 具有的IP地址
1 2 3 4 5 6 7 8 9 [root@master1 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES myapp-v1-67fd9fc9c8-lzsjb 1/1 Running 0 74m 10.244.104.5 node2 <none> <none> myapp-v1-67fd9fc9c8-m7hhp 1/1 Running 0 74m 10.244.166.134 node1 <none> <none> # Node Network 和 Pod network 这两种网络地址是我们实实在在配置的 # 其中节点网络地址是配置在节点接口之上 # 而 pod 网络地址是配置在 pod 资源之上的 # 因此这些地址都是配置在某些设备之上的,这些设备可能是硬件,也可能是软件模拟的
Cluster Network(集群地址,也成为 service network):这个地址是虚拟的地址(virtual ip),没有配置在某个接口上,只是出现在 service 的规则当中
1 2 3 [root@master1 ~]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 3d19h
创建Service资源
1 2 3 4 5 6 7 8 9 10 [root@master1 ~]# kubectl explain service KIND: Service VERSION: v1 FIELDS: apiVersion <string> # service资源使用的api组 kind <string> # 创建的资源类型 metadata <Object> # 定义元数据 spec <Object> status <Object>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 [root@master1 ~]# kubectl explain service.spec KIND: Service VERSION: v1 RESOURCE: spec <Object> FIELDS: allocateLoadBalancerNodePorts <boolean> clusterIP <string> # 动态分配的地址,也可以自己在创建的时候指定,创建之后就改不了了 clusterIPs <[]string> externalIPs <[]string> externalName <string> externalTrafficPolicy <string> healthCheckNodePort <integer> ipFamilies <[]string> ipFamilyPolicy <string> loadBalancerIP <string> loadBalancerSourceRanges <[]string> ports <[]Object> # 定义 service 端口,用来和后端 pod 建立联系 publishNotReadyAddresses <boolean> selector <map[string]string> # 通过标签选择器选择关联的 pod 由哪些 sessionAffinity <string> sessionAffinityConfig <Object> # service 在实现负载句哼的时候还支持 sessionAffinity,sessionAffinityConfig # 会话联系,默认是 none,随机调度(基于 iptables 规则调度) # 如果定义 sessionAffinity 的 client ip,那就表示把来自同一个客户端的 ip 请求调度到同一个 pod 上 topologyKeys <[]string> type <string> # 定义 service 的类型
Service 的四种类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 [root@master1 ~]# kubectl explain service.spec.type KIND: Service VERSION: v1 FIELD: type <string> DESCRIPTION: type determines how the Service is exposed. Defaults to ClusterIP. Valid options are `ExternalName`, `ClusterIP`, `NodePort`, and `LoadBalancer`. "ClusterIP" allocates a cluster-internal IP address for load-balancing to endpoints. Endpoints are determined by the selector or if that is not specified, by manual construction of an Endpoints object or EndpointSlice objects. If clusterIP is "None", no virtual IP is allocated and the endpoints are published as a set of endpoints rather than a virtual IP. "NodePort" builds on ClusterIP and allocates a port on every node which routes to the same endpoints as the clusterIP. "LoadBalancer" builds on NodePort and creates an external load-balancer (if supported in the current cloud) which routes to the same endpoints as the clusterIP. "ExternalName" aliases this service to the specified externalName. Several other fields do not apply to ExternalName services. More info: https://kubernetes.io/docs/concepts/services-networking/service/#publishing-services-service-types
适用于 k8s 集群内部容器访问外部资源,它没有 selector,也没有定义任何的端口和 Endpoint。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 --- apiVersion: v1 kind: Service metadata: name: my-service namespace: prod spec: type: ExternalName externalName: my.database.example.com
通过 k8s 集群内部 IP 暴露服务,选择该值,服务只能够在集群内部访问,这也是默认的ServiceType。
通过每个 Node 节点上的 IP 和静态端口暴露 k8s 集群内部的服务。通过请求 <NodeIP>:<NodePort>可以把请求代理到内部的 pod。
Client—–>NodeIP:NodePort—–>Service Ip:ServicePort—–>PodIP:ContainerPort。
使用云提供商的负载均衡器,可以向外部暴露服务。外部的负载均衡器可以路由到 NodePort 服务和 ClusterIP 服务。
Service 的端口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@master1 ~]# kubectl explain service.spec.ports KIND: Service VERSION: v1 RESOURCE: ports <[]Object> FIELDS: appProtocol <string> name <string> # 定义端口的名字 nodePort <integer> # 宿主机上映射的端口,比如一个 Web 应用需要被 k8s 集群之外的其他用户访问,那么需要配置type =NodePort # 若配置 nodePort=30001,那么其他机器就可以通过浏览器访问 scheme://k8s 集群中的任何一个节点 ip:30001 即可访问到该服务,例如 http://192.168.1.63:30001。 # 如果在 k8s 中部署MySQL 数据库,MySQL 可能不需要被外界访问,只需被内部服务访问,那么就不需要设置 NodePort port <integer> -required- # service 的端口,这个是 k8s 集群内部服务可访问的端口 protocol <string> targetPort <string> # targetPort 是 pod 上的端口,从 port 和 nodePort 上来的流量,经过 kube-proxy 流入到后端 pod的 targetPort 上,最后进入容器。 # 与制作容器时暴露的端口一致(使用 DockerFile 中的 EXPOSE),例如官方的 nginx 暴露 80 端口。
创建 service:type 类型是 ClusterIP
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 --- apiVersion: apps/v1 kind: Deployment metadata: name: my-nginx spec: replicas: 2 selector: matchLabels: run: my-nginx template: metadata: labels: run: my-nginx spec: containers: - name: my-nginx image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80 [root@master1 service ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES my-nginx-69f769d56f-6jqkc 1 /1 Running 0 44s 10.244 .166 .135 node1 <none> <none> my-nginx-69f769d56f-fckmc 1 /1 Running 0 44s 10.244 .104 .6 node2 <none> <none> [root@master1 service ] <!DOCTYPE html> <html> <h1>Welcome to nginx!</h1> </html> [root@master1 service ] <!DOCTYPE html> <html> <h1>Welcome to nginx!</h1> </html> [root@master1 ~ ] [root@master1 ~ ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES my-nginx-69f769d56f-6jqkc 1 /1 Running 0 4m59s 10.244 .166 .135 node1 <none> <none> my-nginx-69f769d56f-ztl2w 1 /1 Running 0 19s 10.244 .166 .136 node1 <none> <none> --- apiVersion: v1 kind: Service metadata: name: my-nginx labels: run: my-nginx spec: type: ClusterIP selector: run: my-nginx ports: - protocol: TCP port: 80 targetPort: 80 [root@master1 ~ ] NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE my-nginx ClusterIP 10.105 .193 .164 <none> 80 /TCP 3m52s [root@master1 ~ ] <!DOCTYPE html> <html> <h1>Welcome to nginx!</h1> </html> root@master1 ~]# kubectl describe svc my-nginx Name: my-nginx Namespace: default Labels: run=my-nginx Annotations: <none> Selector: run=my-nginx Type: ClusterIP IP Families: <none> IP: 10.105 .193 .164 IPs: 10.105 .193 .164 Port: <unset> 80 /TCP TargetPort: 80 /TCP Endpoints: 10.244 .166 .135 :80,10.244.166.136:80 Session Affinity: None Events: <none> [root@master1 ~ ] NAME ENDPOINTS AGE my-nginx 10.244 .166 .135 :80,10.244.166.136:80 6m59s [root@master1 ~ ] root@my-nginx-69f769d56f-ztl2w:/# curl my-nginx.default.svc.cluster.local <!DOCTYPE html> <html> <h1>Welcome to nginx!</h1> </html>
创建 Service:type 类型是 NodePort
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 --- apiVersion: apps/v1 kind: Deployment metadata: name: nginx spec: replicas: 2 selector: matchLabels: run: nginx-nodeport template: metadata: labels: run: nginx-nodeport spec: containers: - name: nginx image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: my-nginx labels: run: nginx-nodeport spec: selector: run: nginx-nodeport ports: - protocol: TCP targetPort: 80 port: 80 nodePort: 30380 type: NodePort [root@master1 ~ ] NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE my-nginx NodePort 10.96 .56 .24 <none> 80 :30380/TCP 36s [root@master1 ~ ] <!DOCTYPE html> <html> <h1>Welcome to nginx!</h1> </html> [root@master1 ~ ] <!DOCTYPE html> <html> <h1>Welcome to nginx!</h1> </html>
创建 Service:type 类型是 ExternalName
应用场景:跨名称空间访问
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 --- apiVersion: apps/v1 kind: Deployment metadata: name: client spec: replicas: 1 selector: matchLabels: app: busybox template: metadata: labels: app: busybox spec: containers: - name: busybox image: busybox command: ["/bin/sh" ,"-c" ,"sleep 36000" ] --- apiVersion: v1 kind: Service metadata: name: client-svc spec: type: ExternalName externalName: nginx-svc.nginx-ns.svc.cluster.local ports: - name: http port: 80 targetPort: 80 [root@master1 ~ ] --- apiVersion: apps/v1 kind: Deployment metadata: name: nginx namespace: nginx-ns spec: replicas: 1 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: nginx-svc namespace: nginx-ns spec: selector: app: nginx ports: - name: http protocol: TCP port: 80 targetPort: 80 [root@master1 ~ ] / <!DOCTYPE html> <html> <h1>Welcome to nginx!</h1> </html> / <!DOCTYPE html> <html> <h1>Welcome to nginx!</h1> </html>
k8s 实践:映射外部服务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 # 在 node2 上安装mysql数据库 [root@node2 ~]# yum install mariadb-server -y [root@node2 ~]# systemctl start mariadb.service # 创建 service --- apiVersion: v1 kind: Service metadata: name: mysql spec: type: ClusterIP ports: - port: 3306 [root@master1 ~]# kubectl get svc | grep mysql mysql ClusterIP 10.107.38.63 <none> 3306/TCP 17s [root@master1 ~]# kubectl describe svc mysql Name: mysql Namespace: default Labels: <none> Annotations: <none> Selector: <none> Type: ClusterIP IP Families: <none> IP: 10.107.38.63 IPs: 10.107.38.63 Port: <unset> 3306/TCP TargetPort: 3306/TCP Endpoints: <none> # 还没有 endpoints Session Affinity: None Events: <none> # 创建 mysql endpoints --- apiVersion: v1 kind: Endpoints metadata: name: mysql # 名字需要跟 service name 保持一致 subsets: - addresses: - ip: 192.168.1.182 ports: - port: 3306 [root@master1 ~]# kubectl describe svc mysql Name: mysql Namespace: default Labels: <none> Annotations: <none> Selector: <none> Type: ClusterIP IP Families: <none> IP: 10.107.38.63 IPs: 10.107.38.63 Port: <unset> 3306/TCP TargetPort: 3306/TCP Endpoints: 192.168.1.182:3306 # 这个就是定义的外部数据库 Session Affinity: None Events: <none> # 上面配置就是将外部 IP 地址和服务引入到 k8s 集群内部,由 service 作为一个代理来达到能够访问外部服务的目的。
Service 代理:kube-proxy 组件详解 kube-proxy 组件介绍
Kubernetes service 只是把应用对外提供服务的方式做了抽象,真正的应用跑在 Pod 中的container 里,我们的请求转到 kubernetes nodes 对应的 nodePort 上,那么 nodePort 上的请求是如何进一步转到提供后台服务的 Pod 的呢? 就是通过 kube-proxy 实现的
kube-proxy 部署在 k8s 的每一个 Node 节点上,是 Kubernetes 的核心组件,我们创建一个 service 的时候,kube-proxy 会在 iptables 中追加一些规则,为我们实现路由与负载均衡的功能。在 k8s1.8 之前,kube-proxy 默认使用的是 iptables 模式,通过各个 node 节点上的 iptables 规则来实现 service 的负载均衡,但是随着 service 数量的增大,iptables 模式由于线性查找匹配、全量更新等特点,其性能会显著下降。从 k8s 的 1.8 版本开始,kube-proxy 引入了 IPVS 模式,IPVS 模式与 iptables 同样基于Netfilter,但是采用的 hash 表,因此当 service 数量达到一定规模时,hash 查表的速度优势就会显现出来,从而提高 service 的服务性能。
service 是一组 pod 的服务抽象,相当于一组 pod 的 LB,负责将请求分发给对应的 pod。service 会为这个 LB 提供一个 IP,一般称为 cluster IP。kube-proxy 的作用主要是负责 service 的实现,具体来说,就是实现了内部从 pod 到 service 和外部的从 node port 向 service 的访问。
1、kube-proxy 其实就是管理 service 的访问入口,包括集群内 Pod 到 Service 的访问和集群外访问 service。
2、kube-proxy 管理 sevice 的 Endpoints,该 service 对外暴露一个 Virtual IP,也可以称为是 Cluster IP, 集群内通过访问这个 Cluster IP:Port 就能访问到集群内对应的 serivce 下的 Pod。
kube-proxy 三种工作模式
Client Pod 要访问 Server Pod 时,它先将请求发给内核空间中的 service iptables 规则,由它再将请求转给监听在指定套接字上的 kube-proxy 的端口,kube-proxy 处理完请求,并分发请求到指定Server Pod 后,再将请求转发给内核空间中的 service ip,由 service iptables 将请求转给各个节点中的 Server Pod。
这个模式有很大的问题,客户端请求先进入内核空间的,又进去用户空间访问 kube-proxy,由 kube-proxy 封装完成后再进去内核空间的 iptables,再根据 iptables 的规则分发给各节点的用户空间的 pod。由于其需要来回在用户空间和内核空间交互通信,因此效率很差。在 Kubernetes 1.1 版本之前,userspace 是默认的代理模型。
客户端 IP 请求时,直接请求本地内核 service ip,根据 iptables 的规则直接将请求转发到到各 pod 上,因为使用 iptable NAT 来完成转发,也存在不可忽视的性能损耗。另外,如果集群中存上万的 Service/Endpoint,那么 Node 上的 iptables rules 将会非常庞大,性能还会再打折
iptables 代理模式由 Kubernetes 1.1 版本引入,自 1.2 版本开始成为默认类型。
Kubernetes 自 1.9-alpha 版本引入了 ipvs 代理模式,自 1.11 版本开始成为默认设置。
客户端请求时到达内核空间时,根据 ipvs 的规则直接分发到各 pod 上。kube-proxy 会监视 Kubernetes Service 对象和 Endpoints,调用 netlink 接口以相应地创建 ipvs 规则并定期与 Kubernetes Service 对象和 Endpoints 对象同步 ipvs 规则,以确保 ipvs 状态与期望一致。访问服务时,流量将被重定向到其中一个后端 Pod。与 iptables 类似,ipvs 基于 netfilter 的 hook 功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着 ipvs 可以更快地重定向流量,并且在同步代理规则时具有更好的性能。此外,ipvs 为负载均衡算法提供了更多选项,例如:
rr:轮询调度
lc:最小连接数
dh:目标哈希
sh:源哈希
sed:最短期望延迟
nq:不排队调度
如果某个服务后端 pod 发生变化,标签选择器适应的 pod 又多一个,适应的信息会立即反映到 apiserver 上,而 kube-proxy 一定可以 watch 到 etc 中的信息变化,而将它立即转为 ipvs 或者 iptables 中的规则,这一切都是动态和实时的,删除一个 pod 也是同样的原理。如图:
注:
以上不论哪种,kube-proxy 都通过 watch 的方式监控着 apiserver 写入 etcd 中关于 Pod 的最新状态信息,它一旦检查到一个 Pod 资源被删除了或新建了,它将立即将这些变化,反应在 iptables 或 ipvs 规则中,以便 iptables 和 ipvs 在调度 Clinet Pod 请求到 Server Pod 时,不会出现 Server Pod 不存在的情况。
自 k8s1.11 以后,service 默认使用 ipvs 规则,若 ipvs 没有被激活,则降级使用 iptables 规则。
kube-proxy 生成的 iptables 规则
service 的 type 类型是 ClusterIp,iptables 规则分析
在 k8s 创建的 service,虽然有 ip 地址,但是 service 的 ip 是虚拟的,不存在物理机上的,是在 iptables 或者 ipvs 规则里的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 --- apiVersion: v1 kind: Pod metadata: name: my-nginx labels: run: my-nginx spec: containers: - name: my-nginx image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: my-nginx labels: run: my-nginx spec: type: ClusterIP selector: run: my-nginx ports: - protocol: TCP port: 80 targetPort: 80 [root@master1 ~ ] NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE my-nginx ClusterIP 10.109 .210 .245 <none> 80 /TCP 60s [root@master1 ~ ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES my-nginx 1 /1 Running 0 3m42s 10.244 .166 .140 node1 <none> <none> [root@master1 ~ ] KUBE-MARK-MASQ tcp -- !10.244.0.0/16 10.109 .210 .245 /* default/my-nginx cluster IP */ tcp dpt:http KUBE-SVC-L65ENXXZWWSAPRCR tcp -- anywhere 10.109 .210 .245 /* default/my-nginx cluster IP */ tcp dpt:http [root@master1 ~ ] KUBE-SVC-L65ENXXZWWSAPRCR tcp -- anywhere 10.109 .210 .245 /* default/my-nginx cluster IP */ tcp dpt:http Chain KUBE-SVC-L65ENXXZWWSAPRCR (1 references) [root@master1 ~ ] KUBE-MARK-MASQ all -- 10.244 .166 .140 anywhere /* default/my-nginx */ DNAT tcp -- anywhere anywhere /* default/my-nginx */ tcp to:10.244.166.140:80
service 的 type 类型是 nodePort,iptables 规则分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 --- apiVersion: v1 kind: Pod metadata: name: my-nginx labels: run: my-nginx spec: containers: - name: my-nginx image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: my-nginx labels: run: my-nginx spec: type: NodePort selector: run: my-nginx ports: - protocol: TCP port: 80 targetPort: 80 nodePort: 30380 [root@master1 ~ ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES my-nginx 1 /1 Running 0 19s 10.244 .166 .141 node1 <none> <none> [root@master1 ~ ] NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE my-nginx NodePort 10.104 .149 .141 <none> 80 :30380/TCP 33s [root@master1 ~ ] -A KUBE-NODEPORTS -p tcp -m comment --comment "default/my-nginx" -m tcp --dport 30380 -j KUBE-MARK-MASQ -A KUBE-NODEPORTS -p tcp -m comment --comment "default/my-nginx" -m tcp --dport 30380 -j KUBE-SVC-L65ENXXZWWSAPRCR [root@master1 ~ ] -N KUBE-SVC-L65ENXXZWWSAPRCR -A KUBE-NODEPORTS -p tcp -m comment --comment "default/my-nginx" -m tcp --dport 30380 -j KUBE-SVC-L65ENXXZWWSAPRCR -A KUBE-SERVICES -d 10.104 .149 .141 /32 -p tcp -m comment --comment "default/my-nginx cluster IP" -m tcp --dport 80 -j KUBE-SVC-L65ENXXZWWSAPRCR -A KUBE-SVC-L65ENXXZWWSAPRCR -m comment --comment "default/my-nginx" -j KUBE-SEP-LT262BZBHIW45DZX [root@master1 ~ ] -N KUBE-SEP-LT262BZBHIW45DZX -A KUBE-SEP-LT262BZBHIW45DZX -s 10.244 .166 .141 /32 -m comment --comment "default/my-nginx" -j KUBE-MARK-MASQ -A KUBE-SEP-LT262BZBHIW45DZX -p tcp -m comment --comment "default/my-nginx" -m tcp -j DNAT --to-destination 10.244 .166 .141 :80 -A KUBE-SVC-L65ENXXZWWSAPRCR -m comment --comment "default/my-nginx" -j KUBE-SEP-LT262BZBHIW45DZX
Service 服务发现:coredns 组件 DNS 是什么
DNS 全称是 Domain Name System:域名系统,是整个互联网的电话簿,它能够将可被人理解的域名翻译成可被机器理解 IP 地址,使得互联网的使用者不再需要直接接触很难阅读和理解的 IP 地址。
域名系统在现在的互联网中非常重要,因为服务器的 IP 地址可能会经常变动,如果没有了 DNS,那么可能 IP 地址一旦发生了更改,当前服务器的客户端就没有办法连接到目标的服务器了,如果我们为 IP 地址提供一个『别名』并在其发生变动时修改别名和 IP 地址的关系,那么我们就可以保证集群对外提供的服务能够相对稳定地被其他客户端访问。
DNS 其实就是一个分布式的树状命名系统,它就像一个去中心化的分布式数据库,存储着从域名到 IP 地址的映射。
CoreDNS
CoreDNS 其实就是一个 DNS 服务,而 DNS 作为一种常见的服务发现手段,所以很多开源项目以及工程师都会使用 CoreDNS 为集群提供服务发现的功能,Kubernetes 就在集群中使用 CoreDNS 解决服务发现的问题。 作为一个加入 CNCF(Cloud Native Computing Foundation)的服务, CoreDNS 的实现非常简单。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 --- apiVersion: v1 kind: Pod metadata: name: dig spec: containers: - name: dig image: xianchao/dig:latest imagePullPolicy: IfNotPresent command: - sleep - "3600" restartPolicy: Always [root@master1 ~ ] kubernetes ClusterIP 10.96 .0 .1 <none> 443 /TCP 4d12h [root@master1 ~ ] Server: 10.96 .0 .10 Address: 10.96 .0 .10 Name: kubernetes.default.svc.cluster.local Address: 10.96 .0 .1
k8s持久化存储
在 k8s 中部署的应用都是以 pod 容器的形式运行的,假如我们部署 MySQL、Redis 等数据库,需要对这些数据库产生的数据做备份。因为 Pod 是有生命周期的,如果 pod 不挂载数据卷,那 pod 被删除或重启后这些数据会随之消失,如果想要长久的保留这些数据就要用到 pod 数据持久化存储。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 [root@master1 ~]# kubectl explain pods.spec.volumes KIND: Pod VERSION: v1 RESOURCE: volumes <[]Object> FIELDS: awsElasticBlockStore <Object> azureDisk <Object> azureFile <Object> `cephfs` <Object> cinder <Object> `configMap` <Object> csi <Object> downwardAPI <Object> `emptyDir` <Object> ephemeral <Object> fc <Object> flexVolume <Object> gcePersistentDisk <Object> gitRepo <Object> `glusterfs` <Object> `hostPath` <Object> iscsi <Object> name <string> -required- `nfs` <Object> `persistentVolumeClaim` <Object> photonPersistentDisk <Object> portworxVolume <Object> projected <Object> quobyte <Object> rbd <Object> scaleIO <Object> `secret` <Object> storageos <Object> vsphereVolume <Object> # 常用的如下: # emptyDir # hostPath # nfs # persistentVolumeClaim # glusterfs # cephfs # configMap # secret # 想要使用存储卷,需要经历如下步骤 1、定义 pod 的 volume,这个 volume 指明它要关联到哪个存储上的 2、在容器中要使用 volumemounts 挂载对应的存储 # 经过以上两步才能正确的使用存储卷
k8s持久化存储:emptyDir
emptyDir 类型的 Volume 是在 Pod 分配到 Node 上时被创建,Kubernetes 会在 Node 上自动分配一个目录,因此无需指定宿主机 Node 上对应的目录文件。 这个目录的初始内容为空,当 Pod 从 Node 上移除时,emptyDir 中的数据会被永久删除。emptyDir Volume 主要用于某些应用程序无需永久保存的临时目录,多个容器的共享目录等。
Emptydir 的官方网址:https://kubernetes.io/docs/concepts/storage/volumes#emptydir
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 apiVersion: v1 kind: Pod metadata: name: pod-empty spec: containers: - name: container-empty image: nginx volumeMounts: - name: cache-volume mountPath: /cache volumes: - name: cache-volume emptyDir: {} [root@master1 ~ ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod-empty 1 /1 Running 0 63s 10.244 .104 .10 node2 <none> <none> [root@master1 ~ ] uid: 3bc98582-6066-49bf-90a5-bd57567d82e2 [root@node2 ~ ] /var/lib/kubelet/pods/3bc98582-6066-49bf-90a5-bd57567d82e2/ ├── containers │ └── container-empty │ └── 64f0c29b ├── etc-hosts ├── plugins │ └── kubernetes.io~empty-dir │ ├── cache-volume │ │ └── ready │ └── wrapped_default-token-bnmcc │ └── ready └── volumes ├── kubernetes.io~empty-dir │ └── cache-volume └── kubernetes.io~secret └── default-token-bnmcc ├── ca.crt -> ..data/ca.crt ├── namespace -> ..data/namespace └── token -> ..data/token
k8s持久化存储:hostPath
hostPath Volume 是指 Pod 挂载宿主机上的目录或文件。 hostPath Volume 使得容器可以使用宿主机的文件系统进行存储,hostpath(宿主机路径):节点级别的存储卷,在 pod 被删除,这个存储卷还是存在的,不会被删除,所以只要同一个 pod 被调度到同一个节点上来,在 pod 被删除重新被调度到这个节点之后,对应的数据依然是存在的。
1 2 3 4 5 6 7 8 [root@master1 ~]# kubectl explain pod.spec.volumes.hostPath KIND: Pod VERSION: v1 RESOURCE: hostPath <Object> FIELDS: path <string> -required- type <string>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 apiVersion: v1 kind: Pod metadata: name: test-hostpath spec: containers: - name: test-nginx image: nginx volumeMounts: - name: test-volume mountPath: /test-nginx - name: test-tomcat image: tomcat volumeMounts: - name: test-volume mountPath: /test-tomcat volumes: - name: test-volume hostPath: path: /data1 type: DirectoryOrCreate [root@master1 ~ ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES test-hostpath 2 /2 Running 0 64s 10.244 .166 .144 node1 <none> <none> [root@node1 ~ ] 总用量 0 [root@node1 ~ ] [root@master1 ~ ] root@test-hostpath:/# cd test-nginx/ root@test-hostpath:/test-nginx# ls aa [root@master1 ~ ] root@test-hostpath:/usr/local/tomcat# cd /test-tomcat/ root@test-hostpath:/test-tomcat# ls aa
hostpath 存储卷缺点:
单节点
可以用分布式存储:nfs,cephfs,glusterfs
k8s持久化存储:nfs
上面说的 hostPath 存储,存在单点故障,pod 挂载 hostPath 时,只有调度到同一个节点,数据才不会丢失。那可以使用 nfs 作为持久化存储。
Pod 挂载 nfs 的官方地址:https://kubernetes.io/zh/docs/concepts/storage/volumes/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 # 以 master1 作为 NFS 服务端 [root@master1 ~]# yum install nfs-utils -y # 在宿主机创建 NFS服务端 [root@master1 ~]# mkdir -pv /data/volumes mkdir: 已创建目录 "/data" mkdir: 已创建目录 "/data/volumes" # 配置 nfs 共享服务器上的 /data/volumes 目录 [root@master1 ~]# vim /etc/exports /data/volumes 192.168.1.0/24(rw,no_root_squash) # no_root_squash: 用户具有根目录的完全管理访问权限 # 使 NFS 配置生效 [root@master1 ~]# exportfs -arv exporting 192.168.1.0/24:/data/volumes [root@master1 ~]# systemctl enable --now nfs [root@master1 ~]# systemctl status nfs Active: active (exited) # 看到 nfs 是 active,说明 nfs 正常启动了 # node1 和 node2 上也安装 nfs 驱动 [root@node1 ~]# yum install nfs-utils -y [root@node1 ~]# systemctl enable --now nfs [root@node2 ~]# yum install nfs-utils -y [root@node2 ~]# systemctl enable --now nfs # 在 node1 上挂载测试 [root@node1 ~]# mkdir /test [root@node1 ~]# mount 192.168.1.180:/data/volumes /test [root@node1 ~]# df -h 192.168.1.180:/data/volumes 79G 5.5G 74G 7% /test # 手动卸载 [root@node1 ~]# umount /test
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 apiVersion: v1 kind: Pod metadata: name: test-nfs spec: containers: - name: test-nfs image: nginx ports: - protocol: TCP containerPort: 80 volumeMounts: - name: nfs-volume mountPath: /usr/share/nginx/html volumes: - name: nfs-volume nfs: path: /data/volumes server: 192.168 .1 .180 [root@master1 ~ ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES test-nfs 1 /1 Running 0 58s 10.244 .166 .145 node1 <none> <none> [root@master1 ~ ] Hello World!!! Hello World!!! Hello World!!! [root@master1 ~ ] Hello World!!! Hello World!!! Hello World!!! [root@master1 ~ ] root@test-nfs:/# cat /usr/share/nginx/html/index.html Hello World!!! Hello World!!! Hello World!!!
上面说明挂载 nfs 存储卷成功了,nfs 支持多个客户端挂载,可以创建多个 pod,挂载同一个 nfs 服务器共享出来的目录;但是 nfs 如果宕机了,数据也就丢失了,所以需要使用分布式存储,常见的分布式存储有 glusterfs 和 cephfs
k8s持久化存储:PVC
PersistentVolume(PV)是群集中的一块存储,由管理员配置或使用存储类动态配置。 它是集群中的资源,就像 pod 是 k8s 集群资源一样。 PV 是容量插件,如 Volumes,其生命周期独立于使用 PV 的任何单个 pod。
PersistentVolumeClaim(PVC)是一个持久化存储卷,我们在创建 pod 时可以定义这个类型的存储卷。 它类似于一个 pod。 Pod 消耗节点资源,PVC 消耗 PV 资源。 Pod 可以请求特定级别的资源(CPU 和内存)。 pvc 在申请 pv 的时候也可以请求特定的大小和访问模式(例如,可以一次读写或多次只读)。
k8s PVC 和 PV 工作原理
PV 是群集中的资源。 PVC 是对这些资源的请求。
pv 的供应方式
可以通过两种方式配置 PV:静态或动态。
静态
集群管理员创建了许多 PV。它们包含可供群集用户使用的实际存储的详细信息。它们存在于 Kubernetes API 中,可供使用。
动态
当管理员创建的静态 PV 都不匹配用户的 PersistentVolumeClaim 时,群集可能会尝试为 PVC 专门动态配置卷。此配置基于 StorageClasses,PVC 必须请求存储类,管理员必须创建并配置该类,以便进行动态配置
绑定
用户创建 pvc 并指定需要的资源和访问模式。在找到可用 pv 之前,pvc 会保持未绑定状态
使用
需要找一个存储服务器,把它划分成多个存储空间;
k8s 管理员可以把这些存储空间定义成多个 pv;
在 pod 中使用 pvc 类型的存储卷之前需要先创建 pvc,通过定义需要使用的 pv 的大小和对应的访问模式,找到合适的 pv;
pvc 被创建之后,就可以当成存储卷来使用了,我们在定义 pod 时就可以使用这个 pvc 的存储卷
pvc 和 pv 它们是一一对应的关系,pv 如果被 pvc 绑定了,就不能被其他 pvc 使用了;
在创建 pvc 的时候,应该确保和底下的 pv 能绑定,如果没有合适的 pv,那么 pvc 就会处于 pending 状态。
回收策略
创建 pod 时如果使用 pvc 做为存储卷,那么它会和 pv 绑定,当删除 pod,pvc 和 pv 绑定就会解除,解除之后和 pvc 绑定的 pv 卷里的数据需要怎么处理,目前,卷可以保留,回收或删除:
Retain
当删除 pvc 的时候,pv 仍然存在,处于 released 状态,但是它不能被其他 pvc 绑定使用,里面的数据还是存在的,当我们下次再使用的时候,数据还是存在的,这个是默认的回收策略
Delete
删除 pvc 时即会从 Kubernetes 中移除 PV,也会从相关的外部设施中删除存储资产
创建 pod,使用 pvc 作为持久存储卷
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@master1 ~]# mkdir -p /data/volume_test/v{1..10} [root@master1 ~]# vim /etc/exports /data/volume_test/v1 192.168.1.0/24(rw,no_root_squash) /data/volume_test/v2 192.168.1.0/24(rw,no_root_squash) /data/volume_test/v3 192.168.1.0/24(rw,no_root_squash) /data/volume_test/v4 192.168.1.0/24(rw,no_root_squash) /data/volume_test/v5 192.168.1.0/24(rw,no_root_squash) /data/volume_test/v6 192.168.1.0/24(rw,no_root_squash) /data/volume_test/v7 192.168.1.0/24(rw,no_root_squash) /data/volume_test/v8 192.168.1.0/24(rw,no_root_squash) /data/volume_test/v9 192.168.1.0/24(rw,no_root_squash) /data/volume_test/v10 192.168.1.0/24(rw,no_root_squash) # 重新加载配置,使配置成效 [root@master1 ~]# exportfs -arv
1 2 3 4 5 6 7 8 9 10 [root@master1 ~]# kubectl explain pv KIND: PersistentVolume VERSION: v1 FIELDS: apiVersion <string> kind <string> metadata <Object> spec <Object> status <Object>
1 2 3 4 5 6 7 8 9 [root@master1 ~]# kubectl explain pv.spec.nfs KIND: PersistentVolume VERSION: v1 RESOURCE: nfs <Object> FIELDS: path <string> -required- readOnly <boolean> server <string> -required-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 --- apiVersion: v1 kind: PersistentVolume metadata: name: v1 spec: capacity: storage: 1Gi accessModes: ["ReadWriteOnce" ] nfs: path: /data/volume_test/v1 server: 192.168 .1 .180 --- apiVersion: v1 kind: PersistentVolume metadata: name: v2 spec: capacity: storage: 2Gi accessModes: ["ReadWriteMany" ] nfs: path: /data/volume_test/v2 server: 192.168 .1 .180 --- apiVersion: v1 kind: PersistentVolume metadata: name: v3 spec: capacity: storage: 3Gi accessModes: ["ReadWriteMany" ] nfs: path: /data/volume_test/v3 server: 192.168 .1 .180 --- apiVersion: v1 kind: PersistentVolume metadata: name: v4 spec: capacity: storage: 4Gi accessModes: ["ReadWriteOnce" ,"ReadWriteMany" ] nfs: path: /data/volume_test/v4 server: 192.168 .1 .180 --- apiVersion: v1 kind: PersistentVolume metadata: name: v5 spec: capacity: storage: 5Gi accessModes: ["ReadWriteOnce" ,"ReadWriteMany" ] nfs: path: /data/volume_test/v5 server: 192.168 .1 .180 --- apiVersion: v1 kind: PersistentVolume metadata: name: v6 spec: capacity: storage: 6Gi accessModes: ["ReadWriteOnce" ,"ReadWriteMany" ] nfs: path: /data/volume_test/v6 server: 192.168 .1 .180 --- apiVersion: v1 kind: PersistentVolume metadata: name: v7 spec: capacity: storage: 7Gi accessModes: ["ReadWriteOnce" ,"ReadWriteMany" ] nfs: path: /data/volume_test/v7 server: 192.168 .1 .180 --- apiVersion: v1 kind: PersistentVolume metadata: name: v8 spec: capacity: storage: 8Gi accessModes: ["ReadWriteOnce" ,"ReadWriteMany" ] nfs: path: /data/volume_test/v8 server: 192.168 .1 .180 --- apiVersion: v1 kind: PersistentVolume metadata: name: v9 spec: capacity: storage: 9Gi accessModes: ["ReadWriteOnce" ,"ReadWriteMany" ] nfs: path: /data/volume_test/v9 server: 192.168 .1 .180 --- apiVersion: v1 kind: PersistentVolume metadata: name: v10 spec: capacity: storage: 10Gi accessModes: ["ReadWriteOnce" ,"ReadWriteMany" ] nfs: path: /data/volume_test/v10 server: 192.168 .1 .180 [root@master1 ~ ] NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE v1 1Gi RWO Retain Available 4m34s v10 10Gi RWO,RWX Retain Available 4m34s v2 2Gi RWX Retain Available 4m34s v3 3Gi RWX Retain Available 4m34s v4 4Gi RWO,RWX Retain Available 4m34s v5 5Gi RWO,RWX Retain Available 4m34s v6 6Gi RWO,RWX Retain Available 4m34s v7 7Gi RWO,RWX Retain Available 4m34s v8 8Gi RWO,RWX Retain Available 4m34s v9 9Gi RWO,RWX Retain Available 4m34s
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: my-pvc spec: accessModes: ["ReadWriteMany" ] resources: requests: storage: 2Gi [root@master1 ~ ] NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE v2 2Gi RWX Retain Bound default/my-pvc 7m42s [root@master1 ~ ] NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE my-pvc Bound v2 2Gi RWX 57s
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 apiVersion: v1 kind: Pod metadata: name: pgd-pvc spec: containers: - name: nginx image: nginx volumeMounts: - name: nginx-html mountPath: /usr/share/nginx/html volumes: - name: nginx-html persistentVolumeClaim: claimName: my-pvc [root@master1 ~ ] NAME READY STATUS RESTARTS AGE pgd-pvc 1 /1 Running 0 31s
注:使用 pvc 和 pv 的注意事项
1、每次创建 pvc 的时候,需要事先有划分好的 pv,这样可能不方便,那么可以在创建 pvc 的时候直接动态创建一个 pv 这个存储类,pv 事先是不存在的
2、pvc 和 pv 绑定,如果使用默认的回收策略 retain,那么删除 pvc 之后,pv 会处于 released 状态,我们想要继续使用这个 pv,需要手动删除 pv,kubectl delete pv pv_name,删除 pv,不会删除 pv 里的数据,当我们重新创建 pvc 时还会和这个最匹配的 pv 绑定,数据还是原来数据,不会丢失。
k8s 存储类:storageclass
上面介绍的 PV 和 PVC 模式都是需要先创建好 PV,然后定义好 PVC 和 pv 进行一对一的 Bond,但是如果 PVC 请求成千上万,那么就需要创建成千上万的 PV,对于运维人员来说维护成本很高,Kubernetes 提供一种自动创建 PV 的机制,叫 StorageClass,它的作用就是创建 PV 的模板。k8s 集群管理员通过创建 storageclass 可以动态生成一个存储卷 pv 供 k8s pvc 使用。
每个 StorageClass 都包含字段 provisioner,parameters 和 reclaimPolicy。
具体来说,StorageClass 会定义以下两部分:
有了这两部分信息,Kubernetes 就能够根据用户提交的 PVC,找到对应的 StorageClass,然后Kubernetes 就会调用 StorageClass 声明的存储插件,创建出需要的 PV。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [root@master1 ~]# kubectl explain storageclass KIND: StorageClass VERSION: storage.k8s.io/v1 FIELDS: allowVolumeExpansion <boolean> allowedTopologies <[]Object> apiVersion <string> kind <string> metadata <Object> mountOptions <[]string> parameters <map[string]string> provisioner <string> -required- reclaimPolicy <string> volumeBindingMode <string> # provisioner:供应商,storageclass 需要有一个供应者,用来确定我们使用什么样的存储来创建 pv
provisioner 既可以由内部供应商提供,也可以由外部供应商提供,如果是外部供应商可以参考:https://github.com/kubernetes-incubator/external-storage/下提供的方法创建。
以 NFS 为例,要想使用 NFS,我们需要一个 nfs-client 的自动装载程序,称之为 provisioner,这个程序会使用我们已经配置好的 NFS 服务器自动创建持久卷,也就是自动帮我们创建 PV。
reclaimPolicy:回收策略
allowVolumeExpansion:允许卷扩展,PersistentVolume 可以配置成可扩展。将此功能设置为 true时,允许用户通过编辑相应的 PVC 对象来调整卷大小。当基础存储类的 allowVolumeExpansion 字段设置为 true 时,以下类型的卷支持卷扩展。
注意:此功能仅用于扩容卷,不能用于缩小卷。
安装 nfs provisioner 用于配置存储类动态生成 pv
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 1 .创建运行 nfs-provisioner 需要的 sa 账号 --- apiVersion: v1 kind: ServiceAccount metadata: name: nfs-provisioner 2 .对 sa 授权 [root@master1 ~ ] 3 .安装 nfs-provisioner 程序 [root@master1 ~ ] [root@master1 ~ ] /data/nfs_pro 192.168 .1 .0 /24(rw,no_root_squash) [root@master1 ~ ] [root@master1 ~ ] --- apiVersion: apps/v1 kind: Deployment metadata: name: nfs-provisioner spec: selector: matchLabels: app: nfs-provisioner replicas: 1 strategy: type: Recreate template: metadata: labels: app: nfs-provisioner spec: serviceAccount: nfs-provisioner containers: - name: nfs-provisioner image: registry.cn-beijing.aliyuncs.com/mydlq/nfs-subdir-external-provisioner:v4.0.0 volumeMounts: - name: nfs-client-root mountPath: /persistentvolumes env: - name: PROVISIONER_NAME value: example.com/nfs - name: NFS_SERVER value: 192.168 .1 .180 - name: NFS_PATH value: /data/nfs_pro volumes: - name: nfs-client-root nfs: server: 192.168 .1 .180 path: /data/nfs_pro [root@master1 ~ ] NAME READY STATUS RESTARTS AGE nfs-provisioner-cd8bf8889-gb2ft 1 /1 Running 0 22s
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: nfs provisioner: example.com/nfs [root@master1 ~ ] NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE nfs example.com/nfs Delete Immediate false 17s env: - name: PROVISIONER_NAME value: example.com/nfs
创建 pvc,通过 storageclass 动态生成 pv
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 apiVersion: v1 kind: PersistentVolumeClaim metadata: name: test-claim1 spec: accessModes: ["ReadWriteMany" ] resources: requests: storage: 1Gi storageClassName: nfs [root@master1 ~ ] NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE test-claim1 Bound pvc-42b53b60-30b0-4e74-9f40-0f86aa8c5ef8 1Gi RWX nfs 18s
步骤总结:
1.供应商:创建一个 nfs provisioner
创建 pod,挂载 storageclass 动态生成的 pvc
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 apiVersion: v1 kind: Pod metadata: name: read-pod spec: containers: - name: read-pod image: nginx volumeMounts: - name: nfs-pvc mountPath: /usr/share/nginx/html restartPolicy: "Never" volumes: - name: nfs-pvc persistentVolumeClaim: claimName: test-claim1 [root@master1 ~ ] NAME READY STATUS RESTARTS AGE read-pod 1 /1 Running 0 40s
默认回收策略是 delete,删除 pvc 后 pv 也会被删除,修改为ratain
1 2 3 4 5 6 7 apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: nfs provisioner: example.com/nfs reclaimPolicy: Retain
k8s 控制器:StatefulSet 概念、原理解读
StatefulSet 是为了管理有状态服务的问题而设计的
扩展:
有状态服务?StatefulSet 是有状态的集合,管理有状态的服务,它所管理的 Pod 的名称不能随意变化。数据持久化的目录也是不一样,每一个 Pod 都有自己独有的数据持久化存储目录。比如 MySQL 主从、redis 集群等。
无状态服务?RC、Deployment、DaemonSet 都是管理无状态的服务,它们所管理的 Pod 的 IP、名字,启停顺序等都是随机的。个体对整体无影响,所有 pod 都是共用一个数据卷的,部署的 tomcat 就是无状态的服务,tomcat 被删除,在启动一个新的 tomcat,加入到集群即可,跟 tomcat 的名字无关。
StatefulSet 由以下几个部分组成
Headless Service:用来定义 pod 网路标识,生成可解析的 DNS 记录
volumeClaimTemplates:存储卷申请模板,创建 pvc,指定 pvc 名称大小,自动创建pvc,且 pvc 由存储类供应。
StatefulSet:管理 pod 的
扩展:什么是 Headless service?
Headless service 不分配 clusterIP,headless service 可以通过解析 service 的 DNS,返回所有 Pod 的 dns 和 ip 地址 (statefulSet 部署的 Pod 才有 DNS),普通的 service,只能通过解析service 的 DNS 返回 service 的 ClusterIP。
为什么要用 headless service(没有 service ip 的 service)?
在使用 Deployment 时,创建的 Pod 名称是没有顺序的,是随机字符串,在用 statefulset 管理 pod 时要求 pod 名称必须是有序的 ,每一个 pod 不能被随意取代,pod 重建后 pod 名称还是一样的。因为 pod IP 是变化的,所以要用 Pod 名称来识别。pod 名称是 pod 唯一性的标识符,必须持久稳定有效。这时候要用到无头服务,它可以给每个 Pod 一个唯一的名称。
headless service 会为 service 分配一个域名
<service name>.$<namespace name>.svc.cluster.local
K8s 中资源的全局 FQDN 格式
Service_NAME.NameSpace_NAME.Domain.LTD.Domain.LTD.=svc.cluster.local. 这是默认 k8s 集群的域名。
FQDN 全称 Fully Qualified Domain Name,即全限定域名:同时带有主机名和域名的名称
如主机名是 master,域名是 baidu.com
StatefulSet 会为关联的 Pod 保持一个不变的 Pod Name
statefulset 中 Pod 的名字格式为$(StatefulSet name)-$(pod 序号)
StatefulSet 会为关联的 Pod 分配一个 dnsName
$<Pod Name>.$<service name>.$<namespace name>.svc.cluster.local
为什么要用 volumeClaimTemplate?
对于有状态应用都会用到持久化存储,比如 mysql 主从,由于主从数据库的数据是不能存放在一个目录下的,每个 mysql 节点都需要有自己独立的存储空间。而在 deployment 中创建的存储卷是一个共享的存储卷,多个 pod 使用同一个存储卷,它们数据是同步的,而 statefulset 定义中的每一个 pod 都不能使用同一个存储卷,这就需要使用 volumeClainTemplate,当在使用 statefulset 创建 pod 时,volumeClainTemplate 会自动生成一个 PVC,从而请求绑定一个 PV,每一个 pod 都有自己专用的存储卷。
Statefulset 资源清单文件编写技巧
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [root@master1 ~]# kubectl explain statefulset KIND: StatefulSet VERSION: apps/v1 DESCRIPTION: StatefulSet represents a set of pods with consistent identities. Identities are defined as: - Network: A single stable DNS and hostname. - Storage: As many VolumeClaims as requested. The StatefulSet guarantees that a given network identity will always map to the same storage identity. FIELDS: apiVersion <string> kind <string> metadata <Object> spec <Object> status <Object>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [root@master1 ~]# kubectl explain statefulset.spec KIND: StatefulSet VERSION: apps/v1 RESOURCE: spec <Object> DESCRIPTION: Spec defines the desired identities of pods in this set. A StatefulSetSpec is the specification of a StatefulSet. FIELDS: podManagementPolicy <string> # pod 管理策略 replicas <integer> # 副本数 revisionHistoryLimit <integer> # 保留的历史版本 selector <Object> -required- # 标签选择器,选择关联的 pod serviceName <string> -required- # headless service 的名字 template <Object> -required- # 生成 pod 的模板 updateStrategy <Object> # 更新策略 volumeClaimTemplates <[]Object> # 存储卷申请模板
查看 statefulset.spec.template 字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 # 对于 template 而言,其内部定义的就是 pod,pod 模板是一个独立的对象 [root@master1 ~]# kubectl explain statefulset.spec.template KIND: StatefulSet VERSION: apps/v1 RESOURCE: template <Object> DESCRIPTION: template is the object that describes the pod that will be created if insufficient replicas are detected. Each pod stamped out by the StatefulSet will fulfill this Template, but have a unique identity from the rest of the StatefulSet. PodTemplateSpec describes the data a pod should have when created from a template FIELDS: metadata <Object> spec <Object> # 定义容器属性 # 通过上面可以看到,statefulset 资源中有两个 spec 字段。 # 第一个 spec 声明的是 statefulset 定义多少个 Pod 副本(默认将仅部署 1 个 Pod)、匹配 Pod 标签的选择器、创建 pod 的模板、存储卷申请模板。 # 第二个 spec 是 spec.template.spec:主要用于 Pod 里的容器属性等配置。 # .spec.template 里的内容是声明 Pod 对象时要定义的各种属性,所以这部分也叫做 PodTemplate(Pod 模板)。 # 还有一个值得注意的地方是:在.spec.selector 中定义的标签选择器必须能够匹配到 spec.template.metadata.labels 里定义的 Pod 标签,否则 Kubernetes 将不允许创建 statefulset。
Statefulset 使用案例:部署 web 站点
1 2 3 4 5 apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: nfs-web provisioner: example.com/nfs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 --- apiVersion: v1 kind: Service metadata: name: nginx labels: app: nginx spec: selector: app: nginx ports: - name: nginx port: 80 clusterIP: None --- apiVersion: apps/v1 kind: StatefulSet metadata: name: web spec: selector: matchLabels: app: nginx serviceName: "nginx" replicas: 2 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx imagePullPolicy: IfNotPresent ports: - name: web containerPort: 80 volumeMounts: - name: www mountPath: /ust/share/nginx/html volumeClaimTemplates: - metadata: name: www spec: accessModes: ["ReadWriteOnce" ] storageClassName: "nfs-web" resources: requests: storage: 1Gi
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 # 查看 statefulset [root@master1 ~]# kubectl get statefulsets.apps NAME READY AGE web 2/2 40s # 查看 pod [root@master1 ~]# kubectl get pods -l app=nginx NAME READY STATUS RESTARTS AGE web-0 1/1 Running 0 67s web-1 1/1 Running 0 54s # 查看 headless service [root@master1 ~]# kubectl get svc -l app=nginx NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nginx ClusterIP None <none> 80/TCP 7m40s # 查看 pvc [root@master1 ~]# kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE www-web-0 Bound pvc-f41837a4-ad51-4193-aac4-b47b4214c02a 1Gi RWO nfs-web 114s www-web-1 Bound pvc-702c097e-dbb8-4433-a735-3830e6e27e9a 1Gi RWO nfs-web 101s # 查看 pv [root@master1 ~]# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-702c097e-dbb8-4433-a735-3830e6e27e9a 1Gi RWO Delete Bound default/www-web-1 nfs-web 2m15s pvc-f41837a4-ad51-4193-aac4-b47b4214c02a 1Gi RWO Delete Bound default/www-web-0 nfs-web # 查看 pod 主机名 [root@master1 ~]# for i in 0 1;do kubectl exec web-$i -- sh -c "hostname";done web-0 web-1 # 使用 kubectl run 运行一个提供 nslookup 命令的容器的,这个命令来自于 dnsutils 包,通过对 pod 主机名执行 nslookup,可以检查它们在集群内部的 DNS 地址 [root@master1 ~]# kubectl exec -it web-1 -- /bin/bash root@web-1:/# apt-get update root@web-1:/# apt-get install dnsutils -y root@web-1:/# nslookup web-0.nginx.default.svc.cluster.local Server: 10.96.0.10 Address: 10.96.0.10#53 # statefulset 创建的 pod 也是有 dns 记录的 Name: web-0.nginx.default.svc.cluster.local Address: 10.244.166.148 # 解析的是 pod 的 ip root@web-1:/# nslookup nginx.default.svc.cluster.local Server: 10.96.0.10 # 查询 service dns,会把对应的 pod ip 解析出来 Address: 10.96.0.10#53 Name: nginx.default.svc.cluster.local Address: 10.244.166.148 Name: nginx.default.svc.cluster.local Address: 10.244.104.12 root@web-1:/# dig -t A nginx.default.svc.cluster.local @10.96.0.10 ; <<>> DiG 9.16.42-Debian <<>> -t A nginx.default.svc.cluster.local @10.96.0.10 ;; global options: +cmd ;; Got answer: ;; WARNING: .local is reserved for Multicast DNS ;; You are currently testing what happens when an mDNS query is leaked to DNS ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 33624 ;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ; COOKIE: 780d6610adb0a779 (echoed) ;; QUESTION SECTION: ;nginx.default.svc.cluster.local. IN A ;; ANSWER SECTION: nginx.default.svc.cluster.local. 30 IN A 10.244.104.12 nginx.default.svc.cluster.local. 30 IN A 10.244.166.148 ;; Query time: 25 msec ;; SERVER: 10.96.0.10#53(10.96.0.10) ;; WHEN: Tue Aug 01 10:12:58 UTC 2023 ;; MSG SIZE rcvd: 166 # dig 的使用 # dig -t A nginx.default.svc.cluster.local @10.96.0.10 # 格式如下: # @来指定域名服务器 # A 为解析类型 ,A 记录 # -t 指定要解析的类型 # A 记录: # A 记录是解析域名到 IP
service 和 headless service 区别
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 # 创建一个 type 为 clusterip 的 service,并绑定 pod --- apiVersion: v1 kind: Service metadata: name: test labels: app: test spec: selector: app: test ports: - port: 80 type: ClusterIP --- apiVersion: apps/v1 kind: Deployment metadata: name: test spec: selector: matchLabels: app: test replicas: 2 template: metadata: labels: app: test spec: containers: - name: test image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80 [root@master1 ~]# kubectl get pods -o wide -l app=test NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES test-59d44ff467-hrz92 1/1 Running 0 45s 10.244.166.152 node1 <none> <none> test-59d44ff467-jp8k5 1/1 Running 0 45s 10.244.104.13 node2 <none> <none> [root@master1 ~]# kubectl get svc -l app=test NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE test ClusterIP 10.111.14.127 <none> 80/TCP 55s [root@master1 ~]# kubectl exec -it web-1 -- /bin/bash root@web-1:/# nslookup test.default.svc.cluster.local Server: 10.96.0.10 Address: 10.96.0.10#53 Name: test.default.svc.cluster.local Address: 10.111.14.127 # 解析的是 service 的 ip 地址
Statefulset 管理 pod:扩容、缩容、更新
1 2 3 4 5 6 7 8 9 10 11 12 # 可以直接修改 statefulset.yaml 里的 replicas 的值 # 也可以直接编辑控制器实现扩容 [root@master1 ~]# kubectl edit sts web replicas: 4 [root@master1 ~]# kubectl get pods -l app=nginx NAME READY STATUS RESTARTS AGE web-0 1/1 Running 0 16h web-1 1/1 Running 0 16h web-2 1/1 Running 0 50s web-3 1/1 Running 0 24s
1 2 3 4 5 6 7 8 9 # 可以直接修改 statefulset.yaml 里的 replicas 的值 # 也可以直接编辑控制器实现扩容 replicas: 2 [root@master1 ~]# kubectl get pods -l app=nginx NAME READY STATUS RESTARTS AGE web-0 1/1 Running 0 16h web-1 1/1 Running 0 16h
1 2 3 4 5 6 7 8 9 10 11 12 # 修改镜像 nginx 变成- image: ikubernetes/myapp:v2,修改之后保存退出 [root@master1 ~]# kubectl edit sts web image: ikubernetes/myapp:v2 [root@master1 ~]# kubectl get pods -l app=nginx -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES web-0 1/1 Running 0 37s 10.244.166.154 node1 <none> <none> web-1 1/1 Running 0 41s 10.244.104.15 node2 <none> <none> # 查看 pod 详细信息 [root@master1 ~]# kubectl describe pods web-0 Image: ikubernetes/myapp:v2
k8s 控制器:Daemonset DaemonSet 控制器:概念、原理解读
DaemonSet 控制器能够确保 k8s 集群所有的节点都运行一个相同的 pod 副本,当向 k8s 集群中增加 node 节点时,这个 node 节点也会自动创建一个 pod 副本,当 node 节点从集群移除,这些 pod 也会自动删除;删除 Daemonset 也会删除它们创建的 pod
如何管理 Pod
daemonset 的控制器会监听 kuberntes 的 daemonset 对象、pod 对象、node 对象,这些被监听的对象之变动,就会触发 syncLoop 循环让 kubernetes 集群朝着 daemonset 对象描述的状态进行演进。
在集群的每个节点上运行存储,比如:glusterd 或 ceph。
在每个节点上运行日志收集组件,比如:flunentd 、 logstash、filebeat 等。
在每个节点上运行监控组件,比如:Prometheus、 Node Exporter 、collectd 等。
DaemonSet 与 Deployment 的区别
Deployment 部署的副本 Pod 会分布在各个 Node 上,每个 Node 都可能运行好几个副本。DaemonSet 的不同之处在于:每个 Node 上最多只能运行一个副本。
DaemonSet 资源清单文件编写技巧
1 2 3 4 5 6 7 8 9 10 11 12 [root@master1 ~]# kubectl explain ds KIND: DaemonSet VERSION: apps/v1 DESCRIPTION: DaemonSet represents the configuration of a daemon set. FIELDS: apiVersion <string> kind <string> metadata <Object> spec <Object> status <Object>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [root@master1 ~]# kubectl explain ds.spec KIND: DaemonSet VERSION: apps/v1 RESOURCE: spec <Object> DESCRIPTION: The desired behavior of this daemon set. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status DaemonSetSpec is the specification of a daemon set. FIELDS: minReadySeconds <integer> # 当新的 pod 启动几秒后,再kill 掉旧的 pod revisionHistoryLimit <integer> # 历史版本 selector <Object> -required- template <Object> -required- updateStrategy <Object> # daemonset 升级策略
1 2 3 4 5 6 7 8 [root@master1 ~]# kubectl explain ds.spec.template KIND: DaemonSet VERSION: apps/v1 RESOURCE: template <Object> FIELDS: metadata <Object> spec <Object>
DaemonSet 使用案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd-elasticsearch namespace: kube-system labels: k8s-app: fluentd-logging spec: selector: matchLabels: k8s-app: fluentd-logging template: metadata: labels: k8s-app: fluentd-logging spec: tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule containers: - name: fluentd-elasticsearch image: xianchao/fluentd:v2.5.1 resources: requests: cpu: 100m memory: 200Mi limits: memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers [root@master1 ~ ] NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE fluentd-elasticsearch 3 3 3 3 3 <none> 38s [root@master1 ~ ] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES fluentd-elasticsearch-2lg85 1 /1 Running 0 62s 10.244 .104 .19 node2 <none> <none> fluentd-elasticsearch-n76zw 1 /1 Running 0 62s 10.244 .137 .67 master1 <none> <none> fluentd-elasticsearch-nkbx5 1 /1 Running 0 62s 10.244 .166 .156 node1 <none> <none>
Daemonset 管理 pod:滚动更新
1 2 3 4 5 6 7 8 9 10 11 12 [root@master1 ~]# kubectl explain ds.spec.updateStrategy KIND: DaemonSet VERSION: apps/v1 RESOURCE: updateStrategy <Object> FIELDS: rollingUpdate <Object> Rolling update config params. Present only if type = "RollingUpdate". type <string> Type of daemon set update. Can be "RollingUpdate" or "OnDelete". Default is RollingUpdate.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [root@master1 ~]# kubectl explain ds.spec.updateStrategy.rollingUpdate KIND: DaemonSet VERSION: apps/v1 RESOURCE: rollingUpdate <Object> DESCRIPTION: Rolling update config params. Present only if type = "RollingUpdate". Spec to control the desired behavior of daemon set rolling update. FIELDS: maxUnavailable <string> # 上面表示 rollingUpdate 更新策略只支持 maxUnavailabe,先删除再更新;因为我们不支持一个节点运行两个 pod,因此需要先删除一个,在更新一个。 # 更新镜像版本,可以按照如下方法: kubectl set image daemonsets fluentd-elasticsearch fluentd-elasticsearch=ikubernetes/filebeat:5.6.6-alpine -n kube-system # 第一个 fluentd-elasticsearch 为 daemonset 的名字 # 第二个 fluentd-elasticsearch 为 daemonset 中 container 的名字
配置管理中心 configmap Configmap 概述
Configmap 是 k8s 中的资源对象,用于保存非机密性的配置的,数据可以用 key/value 键值对的形式保存,也可通过文件的形式保存。
我们在部署服务的时候,每个服务都有自己的配置文件,如果一台服务器上部署多个服务:nginx、tomcat、apache 等,那么这些配置都存在这个节点上,假如一台服务器不能满足线上高并发的要求,需要对服务器扩容,扩容之后的服务器还是需要部署多个服务:nginx、tomcat、apache,新增加的服务器上还是要管理这些服务的配置,如果有一个服务出现问题,需要修改配置文件,每台物理节点上的配置都需要修改,这种方式肯定满足不了线上大批量的配置变更要求。 所以,k8s 中引入了 Configmap 资源对象,可以当成 volume 挂载到 pod 中,实现统一的配置管理。
Configmap 是 k8s 中的资源, 相当于配置文件,可以有一个或者多个 Configmap;
Configmap 可以做成 Volume,k8s pod 启动之后,通过 volume 形式映射到容器内部指定目录上;
容器中应用程序按照原有方式读取容器特定目录上的配置文件。
在容器看来,配置文件就像是打包在容器内部特定目录,整个过程对应用没有任何侵入。
使用 k8s 部署应用,当你将应用配置写进代码中,更新配置时也需要打包镜像,configmap 可以将配置信息和 docker 镜像解耦,以便实现镜像的可移植性和可复用性,因为一个 configMap 其实就是一系列配置信息的集合,可直接注入到 Pod 中给容器使用。configmap 注入方式有两种,一种将 configMap 做为存储卷,一种是将 configMap 通过 env 中 configMapKeyRef 注入到容器中。
使用微服务架构的话,存在多个服务共用配置的情况,如果每个服务中单独一份配置的话,那么更新配置就很麻烦,使用 configmap 可以友好的进行配置共享。
ConfigMap 在设计上不是用来保存大量数据的。在 ConfigMap 中保存的数据不可超过 1 MiB。如果你需要保存超出此尺寸限制的数据,可以考虑挂载存储卷或者使用独立的数据库或者文件服务。
Configmap 创建方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 直接在命令行中指定 configmap 参数创建,通过--from-literal 指定参数 [root@master1 ~]# kubectl create configmap tomcat-config --from-literal=tomcat_port=8080 --from-literal=server_name=myapp.tomcat.com [root@master1 ~]# kubectl describe configmap tomcat-config Name: tomcat-config Namespace: default Labels: <none> Annotations: <none> Data ==== server_name: ---- myapp.tomcat.com tomcat_port: ---- 8080 Events: <none>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 # 通过指定文件创建一个 configmap,--from-file=<文件> [root@master1 ~]# vim nginx.conf server { server_name www.nginx.com; listen 80; root /home/nginx/www/ } # 定义一个 key 是 www,值是 nginx.conf 中的内容 [root@master1 ~]# kubectl create configmap www-nginx --from-file=www=./nginx.conf [root@master1 ~]# kubectl describe configmaps www-nginx Name: www-nginx Namespace: default Labels: <none> Annotations: <none> Data ==== www: ---- server { server_name www.nginx.com; listen 80; root /home/nginx/www/ } Events: <none>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 [root@master1 ~]# mkdir test-a [root@master1 ~]# echo "server-id=1" > test-a/my-server.cnf [root@master1 ~]# echo "server-id=2" > test-a/my-slave.cnf [root@master1 ~]# kubectl create configmap mysql-config --from-file=/root/test-a/ [root@master1 ~]# kubectl describe configmaps mysql-config Name: mysql-config Namespace: default Labels: <none> Annotations: <none> Data ==== my-server.cnf: ---- server-id=1 my-slave.cnf: ---- server-id=2 Events: <none>
编写 configmap 资源清单 YAML 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 apiVersion: v1 kind: ConfigMap metadata: name: mysql labels: app: mysql data: master.cnf: | [mysqld ] log-bin log_bin_trust_function_creators=1 slave.cnf: | [mysqld] super-read-only log_bin_trust_function_creators=1
使用 ConfigMap
通过环境变量引入:使用 configMapKeyRef
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 --- apiVersion: v1 kind: ConfigMap metadata: name: mysql labels: app: mysql data: log: "1" lower: "1" --- apiVersion: v1 kind: Pod metadata: name: mysql-pod spec: containers: - name: mysql image: busybox command: ["/bin/sh" ,"-c" ,"sleep 3600" ] env: - name: log_bin valueFrom: configMapKeyRef: name: mysql key: log - name: lower valueFrom: configMapKeyRef: name: mysql key: lower restartPolicy: Never [root@master1 ~ ] / log_bin=1 lower=1
通过环境变量引入:使用 envfrom
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 --- apiVersion: v1 kind: Pod metadata: name: mysql-pod-envfrom spec: containers: - name: mysql image: busybox command: ["/bin/sh" ,"-c" ,"sleep 3600" ] envFrom: - configMapRef: name: mysql restartPolicy: Never [root@master1 ~ ] / lower=1 log=1
把 configmap 做成 volume,挂载到 pod
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 --- apiVersion: v1 kind: ConfigMap metadata: name: mysql labels: app: mysql data: log: "1" lower: "1" my.cnf: | [mysqld] Welcome=master --- apiVersion: v1 kind: Pod metadata: name: mysql-pod-volume spec: containers: - name: mysql image: busybox command: ["/bin/sh" ,"-c" ,"sleep 3600" ] volumeMounts: - name: mysql-config mountPath: /tmp/config volumes: - name: mysql-config configMap: name: mysql restartPolicy: Never [root@master1 ~ ] / /tmp/config log lower my.cnf /tmp/config 1 /tmp/config 1 /tmp/config [mysqld ] Welcome=master
ConfigMap 热更新 1 2 3 4 5 6 7 8 9 10 11 12 [root@master1 ~]# kubectl edit configmaps mysql log: "2" [root@master1 ~]# kubectl exec -it mysql-pod-volume -- /bin/sh / # cat /tmp/config/log 2 # 注意: # 更新 ConfigMap 后:使用该 ConfigMap 挂载的 Env 不会同步更新 # 使用该 ConfigMap 挂载的 Volume 中的数据需要一段时间(实测大概 10 秒)才能同步更新
配置管理中心 Secret Secret 概述
Configmap 一般是用来存放明文数据的,如配置文件,对于一些敏感数据,如密码、私钥等数据时,要用 secret 类型。
Secret 解决了密码、token、秘钥等敏感数据的配置问题,而不需要把这些敏感数据暴露到镜像或者 Pod Spec 中。Secret 可以以 Volume 或者环境变量的方式使用。
要使用 secret,pod 需要引用 secret。Pod 可以用两种方式使用 secret:作为 volume 中的文件被挂载到 pod 中的一个或者多个容器里,或者当 kubelet 为 pod 拉取镜像时使用。
secret 可选参数有三种:
generic: 通用类型,通常用于存储密码数据。
tls:此类型仅用于存储私钥和证书。
docker-registry: 若要保存 docker 仓库的认证信息的话,就必须使用此种类型来创建。
Secret 类型
Service Account:用于被 serviceaccount 引用。serviceaccout 创建时Kubernetes 会默认创建对应的 secret。Pod 如果使用了 serviceaccount,对应的 secret 会自动挂载到 Pod 的 /run/secrets/kubernetes.io/serviceaccount 目录中。
Opaque:base64 编码格式的 Secret,用来存储密码、秘钥等。可以通过 base64 –decode 解码获得原始数据,因此安全性弱
kubernetes.io/dockerconfigjson:用来存储私有 docker registry 的认证信息。
使用 Secret
通过环境变量引入 Secret
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 [root@master1 ~ ] [root@master1 ~ ] Name: mysql-password Namespace: default Labels: <none> Annotations: <none> Type: Opaque Data ==== password: 18 bytes apiVersion: v1 kind: Pod metadata: name: pod-secret labels: app: myapp spec: containers: - name: myapp image: ikubernetes/myapp:v1 imagePullPolicy: IfNotPresent ports: - name: http containerPort: 80 env: - name: MYSQL_ROOT_PASSWORD valueFrom: secretKeyRef: name: mysql-password key: password [root@master1 ~ ] / MYSQL_ROOT_PASSWORD=masterpod**lucky66
通过 volume 挂载 Secret
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 [root@master1 ~ ] YWRtaW4= [root@master1 ~ ] bWFzdGVyMTIzNDU2Zg== [root@master1 ~ ] master123456f apiVersion: v1 kind: Secret metadata: name: mysecret type: Opaque data: username: YWRtaW4= password: bWFzdGVyMTIzNDU2Zg== [root@master1 ~ ] Name: mysecret Namespace: default Labels: <none> Annotations: <none> Type: Opaque Data ==== password: 13 bytes username: 5 bytes apiVersion: v1 kind: Pod metadata: name: pod-secret-volume spec: containers: - name: myapp image: registry.cn-beijing.aliyuncs.com/google_registry/myapp:v1 imagePullPolicy: IfNotPresent volumeMounts: - name: secret-volume mountPath: /etc/secret readOnly: true volumes: - name: secret-volume secret: secretName: mysecret [root@master1 ~ ] / password username / admin / master123456f
k8s 安全管理:RBAC授权 认证、授权、准入控制概述
k8s 对我们整个系统的认证,授权,访问控制做了精密的设置;对于 k8s 集群来说,apiserver 是整个集群访问控制的唯一入口,我们在 k8s 集群之上部署应用程序的时候,也可以通过宿主机的 NodePort 暴露的端口访问里面的程序,用户访问 kubernetes 集群需要经历如下认证过程:认证->授权->准入控制(adminationcontroller)
认证(Authenticating)是对客户端的认证,通俗点就是用户名密码验证
授权(Authorization)是对资源的授权,k8s 中的资源无非是容器,最终其实就是容器的计算,网络,存储资源,当一个请求经过认证后,需要访问某一个资源(比如创建一个 pod),授权检查会根据授权规则判定该资源(比如某 namespace 下的 pod)是否是该客户可访问的。
准入(Admission Control)机制:准入控制器(Admission Controller)位于 API Server 中,在对象被持久化之前,准入控制器拦截对 API Server 的请求,一般用来做身份验证和授权。其中包含两个特殊的控制器:MutatingAdmissionWebhook 和 ValidatingAdmissionWebhook。分别作为配置的变异和验证准入控制 webhook。
我们在部署 Kubernetes 集群的时候都会默认开启一系列准入控制器,如果没有设置这些准入控制器的话可以说你的 Kubernetes 集群就是在裸奔,应该只有集群管理员可以修改集群的准入控制器。
例如我会默认开启如下的准入控制器。
–admission-control=ServiceAccount,NamespaceLifecycle,NamespaceExists,LimitRanger,ResourceQuota,MutatingAdmissionWebhook,ValidatingAdmissionWebhook
k8s 的整体架构也是一个微服务的架构,所有的请求都是通过一个 GateWay,也就是 kube-apiserver 这个组件(对外提供 REST 服务),k8s 中客户端有两类,一种是普通用户,一种是集群内的 Pod,这两种客户端的认证机制略有不同,但无论是哪一种,都需要依次经过认证,授权,准入这三个机制。
认证
认证支持多种插件
令牌(token)认证:
双方有一个共享密钥,服务器上先创建一个密码下来,客户端登陆的时候拿这个密码登陆即可,这个就是对称密钥认证方式;k8s 提供了一个 restful 风格的接口,它的所有服务都是通过 http 协议提供的,因此认证信息只能经由 http 协议的认证首部进行传递,这种认证首部进行传递通常叫做令牌;
ssl 认证:
对于 k8s 访问来讲,ssl 认证能让客户端确认服务器的认证身份,我们在跟服务器通信的时候,需要服务器发过来一个证书,我们需要确认这个证书是不是 ca 签署的,如果是我们认可的 ca 签署的,里面的 subj 信息与我们访问的目标主机信息保持一致,没有问题,那么我们就认为服务器的身份得到认证了,k8s 中最重要的是服务器还需要认证客户端的信息,kubectl 也应该有一个证书,这个证书也是 server 所认可的 ca 签署的证书,双方需要互相认证,实现加密通信,这就是 ssl 认证。
kubernetes 上的账号
客户端对 apiserver 发起请求,apiserver 要识别这个用户是否有请求的权限,要识别用户本身能否通过 apiserver 执行相应的操作,那么需要哪些信息才能识别用户信息来完成对用户的相关的访问控制呢?
kubectl explain pods.spec 可以看到有一个字段 serviceAccountName(服务账号名称),这个就是我们 pod 连接 apiserver 时使用的账号,因此整个 kubernetes 集群中的账号有两类,ServiceAccount(服务账号),User account(用户账号)
User account:实实在在现实中的人,人可以登陆的账号,客户端想要对 apiserver 发起请求,apiserver 要识别这个客户端是否有请求的权限,那么不同的用户就会有不同的权限,靠用户账号表示,叫做 username
ServiceAccount:方便 Pod 里面的进程调用 Kubernetes API 或其他外部服务而设计的,是 kubernetes 中的一种资源
sa 账号:登陆 dashboard 使用的账号
Service account 是为了方便 Pod 里面的进程调用 Kubernetes API 或其他外部服务而设计的。它与 User account 不同,User account 是为人设计的,而 service account 则是为 Pod 中的进程调用 Kubernetes API 而设计;User account 是跨 namespace 的,而 service account 则是仅局限它所在的 namespace;每个 namespace 都会自动创建一个 default service account;开启 ServiceAccount Admission Controller 后
每个 Pod 在创建后都会自动设置 spec.serviceAccount 为 default(除非指定了其他 ServiceAccout)
验证 Pod 引用的 service account 已经存在,否则拒绝创建;
当创建 pod 的时候,如果没有指定一个 serviceaccount,系统会自动在与该 pod 相同的 namespace 下为其指派一个 default service account。这是 pod 和 apiserver 之间进行通信的账号,如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@master1 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE nfs-provisioner-cd8bf8889-gb2ft 1/1 Running 0 5d17h pod-secret 1/1 Running 0 41h pod-secret-volume 1/1 Running 0 40h [root@master1 ~]# kubectl get pods pod-secret -o yaml | grep "serviceAccountName" serviceAccountName: default [root@master1 ~]# kubectl describe pods pod-secret Volumes: default-token-bnmcc: Type: Secret (a volume populated by a Secret) SecretName: default-token-bnmcc Optional: false
从上面可以看到每个 Pod 无论定义与否都会有个存储卷,这个存储卷为 default-token-xxx。pod 和 apiserver 的认证信息通过 secret 进行定义,由于认证信息属于敏感信息,所以需要保存在 secret 资源当中,并以存储卷的方式挂载到 Pod 当中。从而让 Pod 内运行的应用通过对应的 secret 中的信息来连接 apiserver,并完成认证。每个 namespace 中都有一个默认的叫做 default 的 serviceaccount 资源。查看名称空间内的 secret,也可以看到对应的 default-token。让当前名称空间中所有的 pod 在连接 apiserver 时可以使用的预制认证信息,从而保证 pod 之间的通信。
1 2 3 4 5 6 7 [root@master1 ~]# kubectl get sa NAME SECRETS AGE default 1 11d [root@master1 ~]# kubectl get secrets NAME TYPE DATA AGE default-token-bnmcc kubernetes.io/service-account-token 3 11d
默认的 service account 仅仅只能获取当前 Pod 自身的相关属性,无法观察到其他名称空间 Pod 的相关属性信息。如果想要扩展 Pod,假设有一个 Pod 需要用于管理其他 Pod 或者是其他资源对象,是无法通过自身的名称空间的 serviceaccount 进行获取其他 Pod 的相关属性信息的,此时就需要进行手动创建一个 serviceaccount,并在创建 Pod 时进行定义。那么 serviceaccount 该如何进行定义呢?实际上,service accout 也属于一个 k8s 资源,serviceAccount 也属于标准的 k8s 资源,可以创建一个 serviceAccount,创建之后由我们创建的 pod 使用 serviceAccountName 去加载自己定义的 serviceAccount 就可以了,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 # 创建 serviceaccount [root@master1 ~]# kubectl create sa test [root@master1 ~]# kubectl get sa NAME SECRETS AGE default 1 11d test 1 9s [root@master1 ~]# kubectl describe sa test Name: test Namespace: default Labels: <none> Annotations: <none> Image pull secrets: <none> Mountable secrets: test-token-r2zmh Tokens: test-token-r2zmh Events: <none> # 上面可以看到生成了一个 test-token-r2zmh 的 secret 和 test-token-r2zmh 的 token [root@master1 ~]# kubectl get secrets NAME TYPE DATA AGE test-token-r2zmh kubernetes.io/service-account-token 3 2m48s [root@master1 ~]# kubectl describe secrets test-token-r2zmh Name: test-token-r2zmh Namespace: default Labels: <none> Annotations: kubernetes.io/service-account.name: test kubernetes.io/service-account.uid: 0dd14a67-3d78-4612-acdb-51f72efedf24 Type: kubernetes.io/service-account-token Data ==== ca.crt: 1066 bytes namespace: 7 bytes token: eyJhbGciOiJSUzI1NiIsImtpZCI6IjBCaXlVcWRjT29MSUhNVDdCOXN0TmpfUXNBdEhSdnBVazZqRWNKNENSRFEifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJkZWZhdWx0Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6InRlc3QtdG9rZW4tcjJ6bWgiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoidGVzdCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6IjBkZDE0YTY3LTNkNzgtNDYxMi1hY2RiLTUxZjcyZWZlZGYyNCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpkZWZhdWx0OnRlc3QifQ.lSgX4-ikGFIaCT7luCPu0_U_25MG9zPxcZdufIo-Wzctf1DvTsst90FcSMqIFWts8pBQm9KxJLtAfeZlHNSx088ukfwZHExcrKkmq7pJQ0zE_3aU3gTPqOFErFiCmP7wdpTemidf69si8Ez24gPLvPjv4QZnjRKuESS7_sSn9XUbyu1kKSKQUWw1Jx3Jpbb2b5STV-2fE_8PFe8Lcg0N2DD8_iZFWZ_yVIna57KCJ-uO80wT-K7XsxdKTlipRp7K74v1CKq9RQy19vZ3pPJNf4CVzkZLpMwBhCkvYU1Of1jLZZkg7A-3y1x2OvVueqztVhseric7eJe9utndLMOcLw
上面可以看到生成了 test-token-r2zmh 的 token 详细信息,这个 token 就是 sa 连接 apiserver 的认证信息,这个 token 也是登陆 k8s dashboard 的 token,这些是一个认证信息,能够登陆 k8s,能认证到 k8s,但是不能做别的事情,不代表权限,想要做其他事情,需要授权
在 K8S 集群当中,每一个用户对资源的访问都是需要通过 apiserver 进行通信认证才能进行访问的,那么在此机制当中,对资源的访问可以是 token,也可以是通过配置文件的方式进行保存和使用认证信息,可以通过 kubectl config 进行查看配置,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [root@master1 ~]# kubectl config view apiVersion: v1 clusters: - cluster: certificate-authority-data: DATA+OMITTED server: https://192.168.1.180:6443 # apiserver 的地址 name: kubernetes # 集群的名字 contexts: - context: cluster: kubernetes user: kubernetes-admin name: kubernetes-admin@kubernetes # 上下文的名字 current-context: kubernetes-admin@kubernetes # 当前上下文 kind: Config preferences: {} users: - name: kubernetes-admin user: client-certificate-data: REDACTED client-key-data: REDACTED
在上面的配置文件当中,定义了集群、上下文以及用户。其中 Config 也是 K8S 的标准资源之一,在该配置文件当中定义了一个集群列表,指定的集群可以有多个;用户列表也可以有多个,指明集群中的用户;而在上下文列表当中,是进行定义可以使用哪个用户对哪个集群进行访问,以及当前使用的上下文是什么。
1 2 3 4 5 6 7 [root@master1 ~]# kubectl get pods --kubeconfig=.kube/config NAME READY STATUS RESTARTS AGE mysql-pod 0/1 Completed 0 17h mysql-pod-volume 0/1 Completed 0 42h nfs-provisioner-cd8bf8889-gb2ft 1/1 Running 0 5d17h pod-secret 1/1 Running 0 41h pod-secret-volume 1/1 Running 0 41h
授权
如果用户通过认证,什么权限都没有,需要一些后续的授权操作,如对资源的增删该查等,kubernetes1.6 之后开始有 RBAC(基于角色的访问控制机制)授权检查机制。Kubernetes 的授权是基于插件形成的,其常用的授权插件有以下几种:
Node(节点认证)
ABAC(基于属性的访问控制)
RBAC(基于角色的访问控制)
Webhook(基于 http 回调机制的访问控制)
什么是 RBAC(基于角色的访问控制)
让一个用户(Users)扮演一个角色(Role),角色拥有权限,从而让用户拥有这样的权限,随后在授权机制当中,只需要将权限授予某个角色,此时用户将获取对应角色的权限,从而实现角色的访问控制。如图:
在 k8s 的授权机制当中,采用 RBAC 的方式进行授权,其工作逻辑是,把对对象的操作权限定义到一个角色当中,再将用户绑定到该角色,从而使用户得到对应角色的权限。如果通过 rolebinding 绑定 role,只能对 rolebingding 所在的名称空间的资源有权限,上图 user1 这个用户绑定到 role1 上,只对 role1 这个名称空间的资源有权限,对其他名称空间资源没有权限,属于名称空间级别的;
另外,k8s 为此还有一种集群级别的授权机制,就是定义一个集群角色(ClusterRole),对集群内的所有资源都有可操作的权限,从而将 User2 通过 ClusterRoleBinding 到 ClusterRole,从而使 User2 拥有集群的操作权限。
Role、RoleBinding、ClusterRole 和 ClusterRoleBinding 的关系如下图:
通过上图可以看到,可以通过 rolebinding 绑定 role,rolebinding 绑定 clusterrole,clusterrolebinding 绑定 clusterrole。
上面我们说了两个角色绑定:
还有一种:rolebinding 绑定 clusterrole
rolebinding 绑定 clusterrole 的好处:
假如有 6 个名称空间,每个名称空间的用户都需要对自己的名称空间有管理员权限,那么需要定义 6 个 role 和 rolebinding,然后依次绑定,如果名称空间更多,我们需要定义更多的 role,这个是很麻烦的,所以我们引入 clusterrole,定义一个 clusterrole,对 clusterrole 授予所有权限,然后用户通过 rolebinding 绑定到 clusterrole,就会拥有自己名称空间的管理员权限了
注:RoleBinding 仅仅对当前名称空间有对应的权限。
准入控制
一般而言,准入控制只是用来定义我们授权检查完成之后的后续的其他安全检查操作的,进一步补充了授权机制,由多个插件组合实行,一般而言在创建,删除,修改或者做代理时做补充;
Kubernetes 的 Admission Control 实际上是一个准入控制器(Admission Controller)插件列表,发送到 APIServer 的请求都需要经过这个列表中的每个准入控制器插件的检查,如果某一个控制器插件准入失败,就准入失败。
控制器插件如下:
AlwaysAdmit:允许所有请求通过
AlwaysPullImages:在启动容器之前总是去下载镜像,相当于每当容器启动前做一次用于是否有权使用该容器镜像的检查
AlwaysDeny:禁止所有请求通过,用于测试
DenyEscalatingExec:拒绝 exec 和 attach 命令到有升级特权的 Pod 的终端用户访问。如果集中包含升级特权的容器,而要限制终端用户在这些容器中执行命令的能力,推荐使用此插件 ImagePolicyWebhook
ServiceAccount:这个插件实现了 serviceAccounts 等等自动化,如果使用 ServiceAccount 对象,强烈推荐使用这个插件
SecurityContextDeny:将 Pod 定义中定义了的 SecurityContext 选项全部失效。SecurityContext 包含在容器中定义了操作系统级别的安全选型如 fsGroup,selinux 等选项
ResourceQuota:用于 namespace 上的配额管理,它会观察进入的请求,确保在 namespace 上的配额不超标。推荐将这个插件放到准入控制器列表的最后一个。ResourceQuota 准入控制器既可以限制某个 namespace 中创建资源的数量,又可以限制某个 namespace 中被 Pod 请求的资源总量。ResourceQuota 准入控制器和 ResourceQuota 资源对象一起可以实现资源配额管理。
LimitRanger:用于 Pod 和容器上的配额管理,它会观察进入的请求,确保 Pod 和容器上的配额不会超标。准入控制器 LimitRanger 和资源对象 LimitRange 一起实现资源限制管理
NamespaceLifecycle:当一个请求是在一个不存在的 namespace 下创建资源对象时,该请求会被拒绝。当删除一个 namespace 时,将会删除该 namespace 下的所有资源对象
DefaultStorageClass
DefaultTolerationSeconds
PodSecurityPolicy
当 Kubernetes 版本>=1.6.0,官方建议使用这些插件:
–admission-control=NamespaceLifecycle,LimitRanger,ServiceAccount,PersistentVolumeLabel,DefaultStorageClass,ResourceQuota,DefaultTolerationSeconds
当 Kubernetes 版本>=1.4.0,官方建议使用这些插件:
–admission-control=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,ResourceQuota
以上是标准的准入插件,如果是自己定制的话,k8s1.7 版出了两个 alpha features, Initializers 和 External Admission Webhooks
ServiceAccount 介绍
kubernetes 中账户区分为:User Accounts(用户账户) 和 Service Accounts(服务账户)两种:
UserAccount 是给 kubernetes 集群外部用户使用的,例如运维或者集群管理人员,,kubeadm 安装的 k8s,默认用户账号是 kubernetes-admin;
k8s 客户端(一般用: kubectl) ——>API Server
APIServer 需要对客户端做认证,使用 kubeadm 安装的 K8s,会在用户家目录下创建一个认证配置文件 .kube/config 这里面保存了客户端访问 API Server 的密钥相关信息,这样当用 kubectl 访问 k8s 时,它就会自动读取该配置文件,向 API Server 发起认证,然后完成操作请求。
1 2 3 4 5 [root@master1 ~]# cat .kube/config ······ users: - name: kubernetes-admin ······
ServiceAccount 是 Pod 使用的账号,Pod 容器的进程需要访问 API Server 时用的就是ServiceAccount 账户;ServiceAccount 仅局限它所在的 namespace,每个 namespace 创建时都会自动创建一个 default service account;创建 Pod 时,如果没有指定 Service Account,Pod 则会使用 default Service Account。
RBAC 认证授权策略
RBAC 介绍
在 Kubernetes 中,所有资源对象都是通过 API 进行操作,他们保存在 etcd 里。而对 etcd 的操作我们需要通过访问 kube-apiserver 来实现,上面的 Service Account 其实就是 APIServer 的认证过程,而授权的机制是通过 RBAC:基于角色的访问控制实现。
RBAC 有四个资源对象,分别是 Role、ClusterRole、RoleBinding、ClusterRoleBinding
Role:角色
一组权限的集合,在一个命名空间中,可以用其来定义一个角色,只能对命名空间内的资源进行授权。如果是集群级别的资源,则需要使用 ClusterRole。
例如:定义一个角色用来读取 Pod 的权限
1 2 3 4 5 6 7 8 9 10 apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: namespace: rbac name: pod-read rules: - apiGroups: ["" ] resources: ["pods" ] resourceNames: ["" ] verbs: ["get" ,"watch" ,"list" ]
rules 中的参数说明
apiGroups:支持的 API 组列表,例如:“apiVersion: batch/v1”等
resources:支持的资源对象列表,例如 pods、deplayments、jobs 等
resourceNames: 指定 resource 的名称
verbs:对资源对象的操作方法列表。
ClusterRole:集群角色
具有和角色一致的命名空间资源的管理能力,还可用于以下特殊元素的授权
集群范围的资源,例如 Node
非资源型的路径,例如:/healthz
包含全部命名空间的资源,例如 Pods
例如:定义一个集群角色可让用户访问任意 secrets
1 2 3 4 5 6 7 8 apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: secret-clusterrole rules: - apiGroups: ["" ] resources: ["secret" ] verbs: ["get" ,"watch" ,"list" ]
RoleBinding && ClusterRolebinding
角色绑定和集群角色绑定用于把一个角色绑定在一个目标上,可以是 User,Group,Service Account,使用 RoleBinding 为某个命名空间授权,使用 ClusterRoleBinding 为集群范围内授权。
例如:将在 rbac 命名空间中把 pod-read 角色授予用户 es
1 2 3 4 5 6 7 8 9 10 11 12 13 apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: pod-read-bind namespace: rbac subjects: - kind: User name: es apiGroup: rbac.authorization.k8s.io roleRef: - kind: Role name: pod-read apiGroup: rbac.authorizatioin.k8s.io
RoleBinding 也可以引用 ClusterRole,对属于同一命名空间内的 ClusterRole 定义的资源主体进行授权
例如:es 能获取到集群中所有的资源信息
1 2 3 4 5 6 7 8 9 10 11 12 13 apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: ex-allresource namespace: rbac subjects: - kind: User name: es apiGroup: rbac.authorization.k8s.io roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin
集群角色绑定的角色只能是集群角色,用于进行集群级别或对所有命名空间都生效的授权
例如:允许 manager 组的用户读取所有 namaspace 的 secrets
1 2 3 4 5 6 7 8 9 10 11 12 apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: read-secret-global subjects: - kind: Group name: manager apiGroup: rbac.authorization.k8s.io ruleRef: - kind: ClusterRole name: secret-read apiGroup: rbac.authorization.k8s.io
资源的引用方式
多数资源可以用其名称的字符串表示,也就是 Endpoint 中的 URL 相对路径,例如 pod 中的日志是GET /api/v1/namaspaces/{namespace}/pods/{podname}/log
如果需要在一个 RBAC 对象中体现上下级资源,就需要使用 “/” 分割资源和下级资源。
例如:若想授权让某个主体同时能够读取 Pod 和 Pod log,则可以配置 resources 为一个数组
1 2 3 4 5 6 7 8 9 apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: logs-reader namespace: default rules: - apiGroups: ["" ] resources: ["pods" ,"pods/log" ] verbs: ["get" ,"list" ]
资源还可以通过名称(ResourceName)进行引用,在指定 ResourceName 后,使用 get、delete、update、patch 请求,就会被限制在这个资源实例范围内
例如,下面的声明让一个主体只能对名为 my-configmap 的 Configmap 进行 get 和 update 操作
1 2 3 4 5 6 7 8 9 10 apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: namespace: default name: configmap-update rules: - apiGroups: ["" ] resources: ["configmap" ] resourceNames: ["my-configmap" ] verbs: ["get" ,"update" ]
常见角色示例
1 2 3 4 rules: - apiGroups: ["" ] resources: ["pods" ] verbs: ["get" ,"list" ,"watch" ]
允许读写 extensions 和 apps 两个 API 组中的 deployment 资源
1 2 3 4 rules: - apiGroups: ["extensions" ,"apps" ] resources: ["deployment" ] verbs: ["get" ,"list" ,"watch" ,"create" ,"update" ,"patch" ,"delete" ]
1 2 3 4 5 6 7 rules: - apiGroups: ["" ] resources: ["pods" ] verbs: ["get" ,"list" ,"watch" ] - apiGroups: ["extensions" ,"batch" ] resources: ["jobs" ] verbs: ["get" ,"list" ,"watch" ,"create" ,"update" ,"patch" ,"delete" ]
允许读取一个名为 my-config 的 ConfigMap(必须绑定到一个 RoleBinding 来限制到一个 Namespace 下的 ConfigMap)
1 2 3 4 5 rules: - apiGroups: ["" ] resources: ["configmap" ] resourceNames: ["my-configmap" ] verbs: ["get" ]
读取核心组的 Node 资源(Node 属于集群级的资源,所以必须存在于 ClusterRole 中,并使用 ClusterRoleBinding 进行绑定)
1 2 3 4 rules: - apiGroups: ["" ] resources: ["nodes" ] verbs: ["get" ,"list" ,"watch" ]
允许对非资源端点 “/healthz” 及其所有子路径进行 GET 和 POST 操作(必须使用 ClusterRole 和 ClusterRoleBinding)
1 2 3 rules: - nonResourcesURLs: ["/healthz" ,"/healthz/*" ] verbs: ["get" ,"post" ]
常见的角色绑定示例
1 2 3 4 subjects: - kind: User name: alice apiGroup: rbac.authorization.k8s.io
1 2 3 4 subjects: - kind: Group name: alice apiGroup: rbac.authorization.k8s.io
kube-system 命名空间中默认 Service Account
1 2 3 4 subjects: - kind: ServiceAccount name: default namespace: kube-system
qa 命名空间中的所有 Service Account
1 2 3 4 subjects: - kind: Group name: system:serviceaccounts:qa apiGroup: rbac.authorization.k8s.io
1 2 3 4 subjects: - kind: Group name: system:serviceaccountes apiGroup: rbac.authorization.k8s.io
1 2 3 4 subjects: - kind: Group name: system:authenticated apiGroup: rbac.authorization.k8s.io
1 2 3 4 subjects: - kind: Group name: system:unauthenticated apiGroup: rbac.authorization.k8s.io
1 2 3 4 5 6 7 subjects: - kind: Group name: system:authenticated apiGroup: rbac.authorization.k8s.io - kind: Group name: system:unauthenticated apiGroup: rbac.authorization.k8s.io
对 Service Account 的授权管理
Service Account 也是一种账号,是给运行在 Pod 里的进程提供了必要的身份证明。需要在 Pod定义中指明引用的 Service Account,这样就可以对 Pod 的进行赋权操作。
例如:pod 内可获取rbac 命名空间的所有 Pod 资源,pod-reader-sc 的 Service Account 是绑定了名为 pod-read 的Role
1 2 3 4 5 6 7 8 9 10 11 12 13 apiVersion: v1 kind: Pod metadta: name: nginx namespace: rbac spec: serviceAccountName: pod-reader-sc containers: - name: nginx image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80
默认的 RBAC 策略为控制平台组件、节点和控制器授予有限范围的权限,但是除 kube-system 外的 Service Account 是没有任何权限的。
为一个应用专属的 Service Account 赋权
此应用需要在 Pod 的 spec 中指定一个 serviceAccountName,用于 API、Application Manifest、kubectl create serviceaccount 等创建 Service Account 的命令。
例如为 my-namespace 中的 my-sa Service Account 授予只读权限
1 kubectl create rolebinding my-sa-view --clusterrole=view --serviceaccount=my-namespace:my-sa --namespace=my-namespace
为一个命名空间中名为 default 的 Service Account 授权
如果一个应用没有指定 serviceAccountName,则会使用名为 default 的 Service Account。注意,赋予 Service Account “default”的权限会让所有没有指定 serviceAccountName 的 Pod都具有这些权限
例如,在 my-namespace 命名空间中为 Service Account“default”授予只读权限:
1 kubectl create rolebinding default-view --clusterrole=view --serviceaccount=my-namespace:default --namespace=my-namespace
另外,许多系统级 Add-Ons 都需要在 kube-system 命名空间中运行,要让这些 Add-Ons 能够使用超级用户权限,则可以把 cluster-admin 权限赋予 kube-system 命名空间中名为 default 的 Service Account,这一操作意味着 kube-system 命名空间包含了通向 API 超级用户的捷径。
1 kubectl create clusterrolebinding add-ons-add-admin --clusterrole=cluster-admin --serviceaccount=kube-system:default
为命名空间中所有 Service Account 都授予一个角色
如果希望在一个命名空间中,任何 Service Account 应用都具有一个角色,则可以为这一命名空间的 Service Account 群组进行授权
1 kubectl create rolebinding serviceaccounts-view --clusterrole=view --group=system:serviceaccounts:my-namespace --namespace=my-namespace
为集群范围内所有 Service Account 都授予一个低权限角色
如果不想为每个命名空间管理授权,则可以把一个集群级别的角色赋给所有 Service Account。
1 kubectl create clusterrolebinding serviceaccounts-view --clusterrole=view --group=system:serviceaccounts
为所有 Service Account 授予超级用户权限
1 kubectl create clusterrolebinding serviceaccounts-view --clusterrole=cluster-admin --group=system:serviceaccounts
使用 kubectl 命令行工具创建资源对象
在命名空间 rbac 中为用户 es 授权 admin ClusterRole
1 kubectl create rolebinding bob-admin-binding --clusterrole=admin --user=es --namespace=rbac
在命名空间 rbac 中为名为 myapp 的 Service Account 授予 view ClusterRole
1 kubectl create rolebinding myapp-role-binding --clusterrole=view --serviceaccount=rbac:myapp --namespace=rbac
在全集群范围内为用户 root 授予 cluster-admin ClusterRole
1 kubectl create clusterrolebinding cluster-binding --clusterrole=cluster-admin --user=root
在全集群范围内为名为 myapp 的 Service Account 授予 view ClusterRole
1 kubectl create clusterrolebinding service-account-binding --clusterrole=view --serviceaccount=myapp
限制不同的用户操作 k8s 集群
1 2 3 4 5 6 7 8 9 # 生成私钥 cd /etc/kubernetes/pki/ (umask 077;openssl genrsa -out lucky.key 2048) # 生成证书请求 openssl req -new -key lucky.key -out lucky.csr -subj "/CN=lucky" # 生成证书 openssl x509 -req -in lucky.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out lucky.crt -days 3650
在 kubeconfig 下新添加一个 lucky 这个用户
1 2 3 4 5 6 7 8 9 10 11 # 把 lucky 这个用户添加到 kubernetes 集群中,可以用来认证 apiserver 的连接 kubectl config set-credentials lucky --client-certificate=./lucky.crt --client-key=./lucky.key --embed-certs=true # 在 kubeconfig 下新增加一个 lucky 这个账号 kubectl config set-context lucky@kubernetes --cluster=kubernetes --user=lucky # 切换账号到 lucky,默认没有任何权限 kubectl config use-context lucky@kubernetes kubectl config use-context kubernetes-admin@kubernetes # 这个是集群用户,有任何权限
把 user 这个用户通过 rolebinding 绑定到 clusterrole 上,授予权限,权限只是在 lucky 这个名称空间有效
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 # 把 lucky 这个用户通过 rolebinding 绑定到 clusterrole 上 kubectl create ns lucky kubectl create rolebinding lucky -n lucky --clusterrole=cluster-admin --user=lucky # 切换到 lucky 这个用户 kubectl config use-context lucky@kubernetes # 测试是否有权限 kubectl get pods -n lucky # 有权限操作这个名称空间 kubectl get pods # 没有权限操作其他名称空间 # 添加一个 lucky 的普通用户 useradd lucky cp -ar /root/.kube/ /home/lucky/ chown -R lucky.lucky /home/lucky/ su - lucky kubectl get pods -n lucky